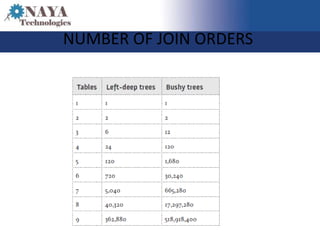
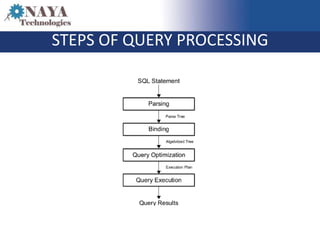
The document discusses the role of the SQL query optimizer in generating efficient query plans. It describes the optimizer's multi-stage process of parsing the SQL statement, binding objects, optimizing through different search levels, applying logical and physical properties and over 350 rules to simplify and optimize the query tree, and selecting the cheapest plan. It notes challenges like a large number of possible join orders and timeouts during complex optimizations.