Download to read offline













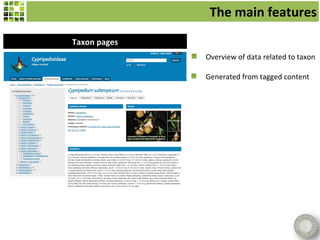


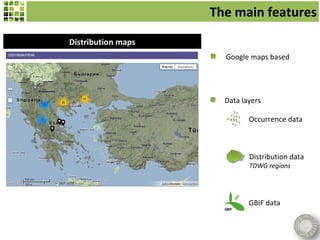
![The main features
Character matrices – Key construction
Quantitative or qualitative characters
Auto generation of keys
Taxon based matrices
[Specimens based character matrices]](https://image.slidesharecdn.com/publishingbiodiversitykoureas-130225083914-phpapp02/85/Publishing-biodiversity-The-interplay-between-Scratchpads-and-the-new-Biodiversity-Data-Journal-21-320.jpg)



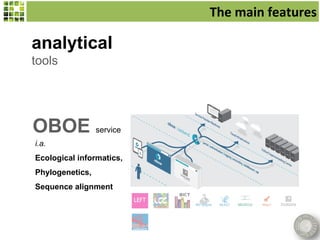






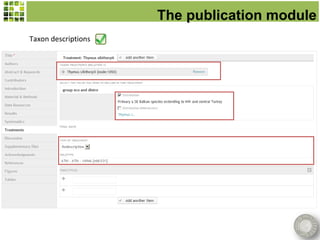

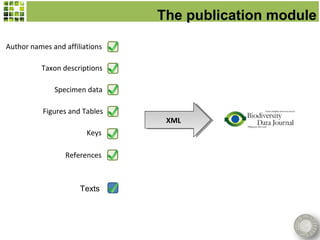
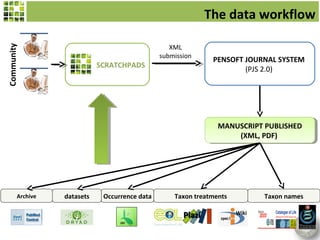
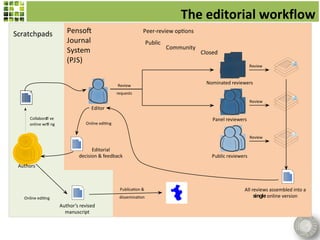

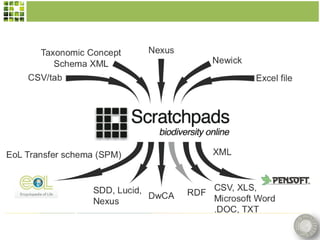


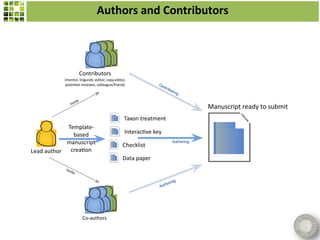

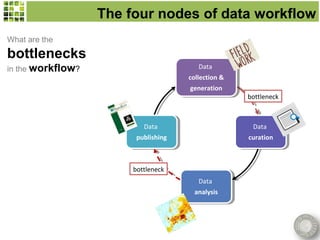
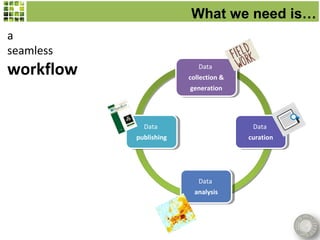
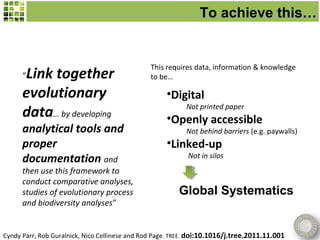
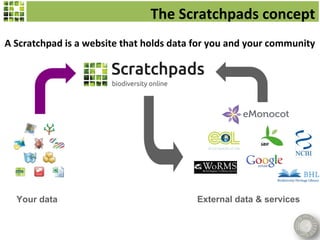
Scratchpads are virtual research environments that allow researchers to collect, curate, analyze, and publish biodiversity data in a seamless workflow. They facilitate open access to digital data through standardized modular platforms that allow data sharing and interlinking. The new Biodiversity Data Journal will publish taxonomic treatments, checklists, keys, and datasets that have been generated using Scratchpads. This will integrate the processes of conducting research and publishing results within a single online environment.















































