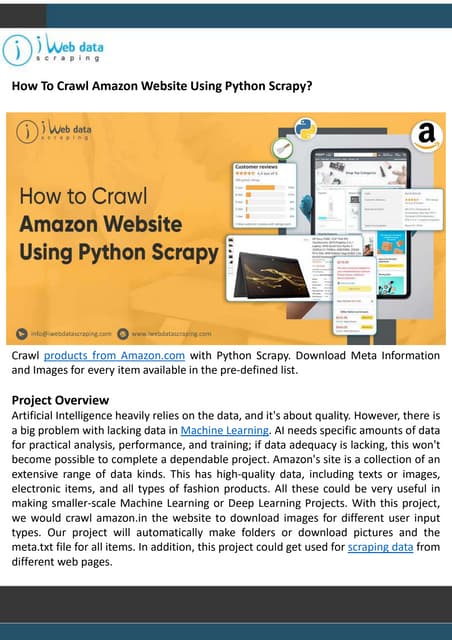
Downloaded 14 times









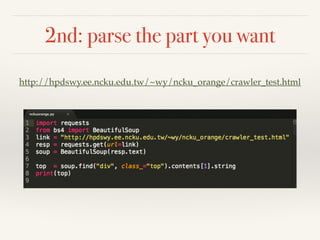







1. The document discusses the steps to create a web crawler: observe the website's framework, parse the desired parts of the HTML code, and save the extracted data to a JSON file. 2. It recommends using the Beautiful Soup library in Python to parse HTML and extract data, and demonstrates how to select specific parts of a sample web page's code to print. 3. JSON is suggested as the format to save the extracted data because it is a lightweight data interchange format.