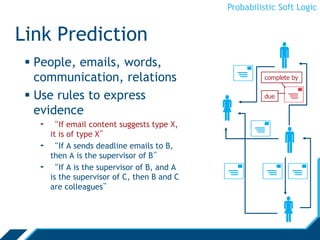
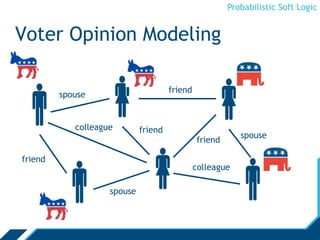
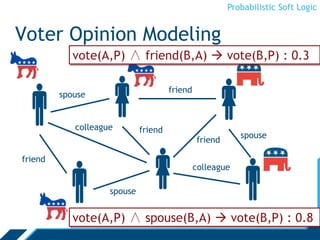
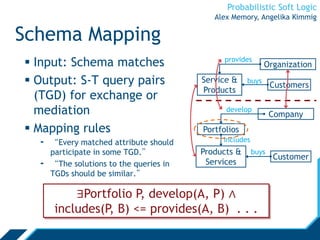
Probabilistic Soft Logic (PSL) is a declarative language for expressing collective probabilistic inference problems. PSL uses predicates, atoms, rules, and sets to define relationships and constraints between entities. A PSL program consists of a set of rules and an input database. PSL can be used for tasks like entity resolution and link prediction by expressing evidence through rules and performing probabilistic inference. Inference in PSL finds the most probable explanation for unknown atoms by minimizing a hinge-loss objective using an alternating direction method of multipliers algorithm. This scalable algorithm optimizes local copies of variables in parallel.








![Probabilistic Soft Logic
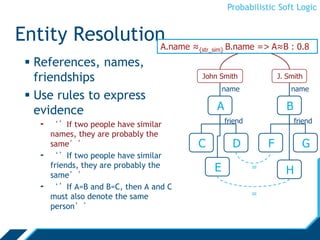
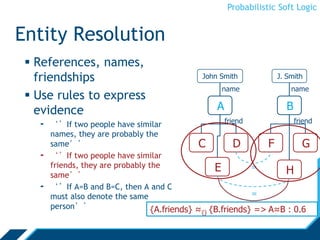
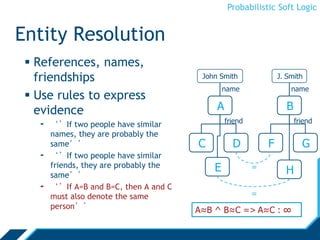
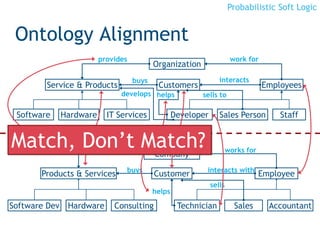
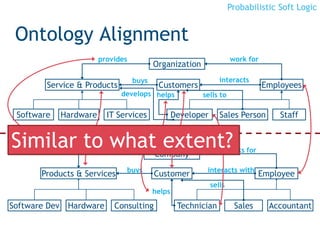
Rules
Atoms are real valued
- Interpretation I, atom A: I(A) [0,1]
- We will omit the interpretation and write A [0,1]
∨, ∧ are combination functions
- T-norms: [0,1]n →[0,1]
H1 ∨... Hm ← B1 ∧ B2 ∧ ... Bn
Ground Atoms
[Broecheler, et al., UAI ‘1](https://image.slidesharecdn.com/psloverview-talk-as-given-130614161140-phpapp02/85/PSL-Overview-23-320.jpg)









![Probabilistic Soft Logic
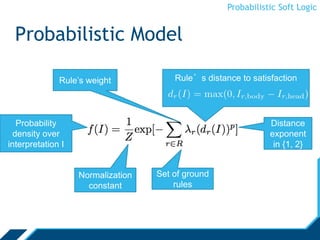
Alternating Direction Method of
Multipliers
• We perform inference using the alternating
direction method of multipliers (ADMM)
• Inference with ADMM
is fast, scalable,
and straightforward
• Optimize subproblems
(ground rules) independently, in parallel
• Auxiliary variables enforce consensus
across subproblems
[Bach et al., NIPS ’12]](https://image.slidesharecdn.com/psloverview-talk-as-given-130614161140-phpapp02/85/PSL-Overview-34-320.jpg)
![Probabilistic Soft Logic
Inference Algorithm
Initialize local copies
of variables and
Lagrange multipliers
Begin inference
iterations
Simple updates
solve subproblems
for each potential...
...and each
constraint
Average to update
global variables and
clip to [0,1]
[Bach, et al., Under revie](https://image.slidesharecdn.com/psloverview-talk-as-given-130614161140-phpapp02/85/PSL-Overview-35-320.jpg)
![Probabilistic Soft Logic
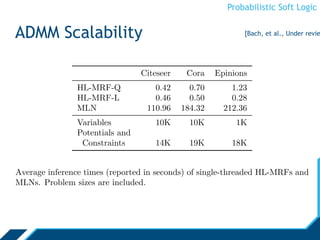
ADMM Scalability
0
100
200
300
400
500
600
125000 225000 325000
Timeinseconds
Number of potential functions and constraints
ADMM
Interior-point method
[Bach, et al., NIPS ‘12]](https://image.slidesharecdn.com/psloverview-talk-as-given-130614161140-phpapp02/85/PSL-Overview-36-320.jpg)
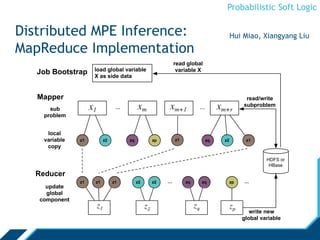
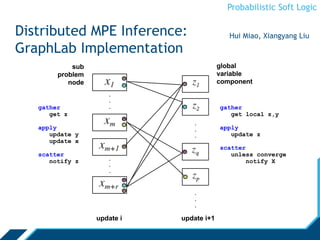

![Probabilistic Soft Logic
Weight Learning
Learn from training data
No need to hand-code rule-weights
Various methods:
- approximate maximum likelihood
[Broecheler et al., UAI ’10]
- maximum pseudolikelihood
- large-margin estimation
[Bach, et al., UAI ’13]](https://image.slidesharecdn.com/psloverview-talk-as-given-130614161140-phpapp02/85/PSL-Overview-41-320.jpg)
![Probabilistic Soft Logic
Weight Learning
State-of-the-art supervised-learning
performance on
- Collective classification
- Social-trust prediction
- Preference prediction
- Image reconstruction
[Bach, et al., UAI ’13]](https://image.slidesharecdn.com/psloverview-talk-as-given-130614161140-phpapp02/85/PSL-Overview-42-320.jpg)



![Probabilistic Soft Logic
Document Classification
2
2
2
2
2A
B
A or B?
A or B?
A or B?
Given a networked collection of documents
Observe some labels
Predict remaining labels using
link direction
inferred class label
[Bach, et al., UAI ’13]](https://image.slidesharecdn.com/psloverview-talk-as-given-130614161140-phpapp02/85/PSL-Overview-46-320.jpg)

![Probabilistic Soft Logic
Image Reconstruction
RMSE reconstruction error
[Bach, et al., UAI ’13]](https://image.slidesharecdn.com/psloverview-talk-as-given-130614161140-phpapp02/85/PSL-Overview-48-320.jpg)


![Probabilistic Soft Logic
Social Trust Prediction
Competing models from social
psychology of strong ties
- Structural balance [Granovetter ’73]
- Social status [Cosmides et al., ’92]
Leskovec, Huttenlocher, & Kleinberg,
[2010]: effects of both models present
in online social networks](https://image.slidesharecdn.com/psloverview-talk-as-given-130614161140-phpapp02/85/PSL-Overview-51-320.jpg)







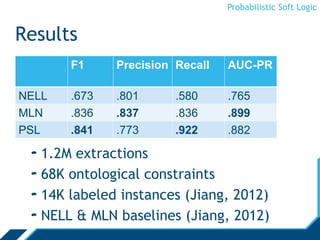
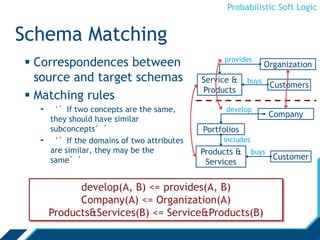
![Probabilistic Soft Logic
FilmTrust Experiment
Normalize [1,10] rating to [0,1]
Prune network to largest connected-component
1,754 users, 2,055 relationships
Compare mean average error, Spearman’s rank
coefficient, and Kendall-tau distance
* measured on only non-default predictions
• PSL-Status and PSL-Balance disagree on 514 relationships
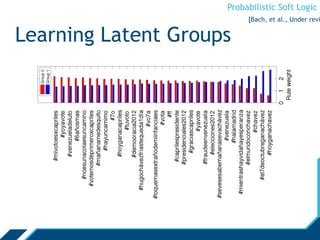
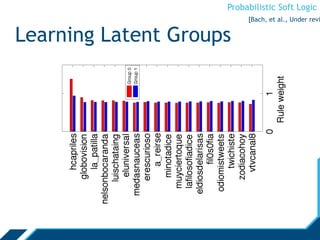
[Huang, et al., SBP ‘1](https://image.slidesharecdn.com/psloverview-talk-as-given-130614161140-phpapp02/85/PSL-Overview-59-320.jpg)







![Probabilistic Soft Logic
Other LINQS Projects
Drug-target interaction: Shobeir Fakhraei
MOOC user-role prediction and expert identification: Arti Ramesh
Semantic-role labeling: Arti Ramesh and Alex Memory
Optimal source selection for data integration: Theo Rekatsinas
Learning theory in non-I.I.D. settings: Ben London, Bert Huang
Collective stability [London et al, ICML13]
Scalable graph analysis using GraphLab: Hui Miao, Walaa Eldin
Moustafa
Uncertain graph models: Walaa Eldin Moustafa](https://image.slidesharecdn.com/psloverview-talk-as-given-130614161140-phpapp02/85/PSL-Overview-72-320.jpg)
































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)

















