Download to read offline











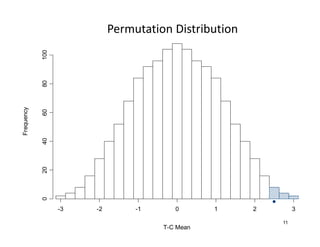



























1) Permutation tests condition on all data except treatment assignments and have a valid null distribution even if test statistics or aspects of the study design are adapted based on interim blinded data. 2) For a one-sample matched pairs design, the permutation distribution of the test statistic is normal with mean 0 and variance equal to the sum of squared differences between pairs. 3) The t-statistic calculated from such a design has the same null distribution as the permutation test statistic and remains valid for interim adaptations.








































![PERMUTATION APPROACH TO NON PARAMETRIC HYPOTHESIS TEST [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/permutationapproachtononparametrichypothesistestautosaved-240927025622-c8ea6cb7-thumbnail.jpg?width=640&height=640&fit=bounds)














































![CTEV [ clubfoot] DR ARUN LAL ,DR MOHAMED ASHRAF travancore medical college k...](https://cdn.slidesharecdn.com/ss_thumbnails/ctevclubfootdrarunlaldrmohamedashraftravancoremedicalcollegekollamkeralaindia-260208063247-18fc466c-thumbnail.jpg?width=640&height=640&fit=bounds)
