1. The document summarizes a capstone project on automatic text summarization using both extractive and abstractive techniques.
2. It discusses motivations for summarization, approaches to extractive and abstractive summarization, data collection and analysis, classification methods, and evaluation metrics.
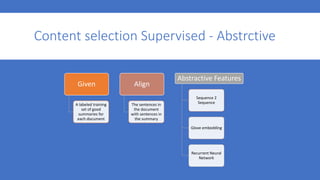
3. The project uses a BBC news dataset and develops sequence-to-sequence and GloVe embedding models to generate abstractive summaries that are evaluated using ROUGE scores against human-written references.





















![[poster] Detecting Incongruity Between News Headline and Body Text via a Deep...](https://cdn.slidesharecdn.com/ss_thumbnails/aaai2019-poster-190621122753-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[ ] uottawa_copeck.doc](https://cdn.slidesharecdn.com/ss_thumbnails/uottawacopeckdoc2704-thumbnail.jpg?width=640&height=640&fit=bounds)





















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


