Download as PDF, PPTX







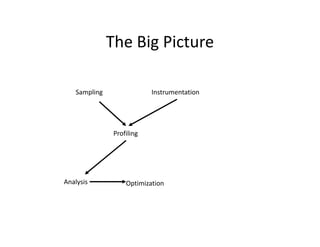



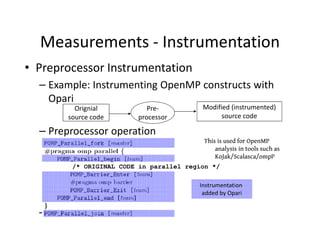










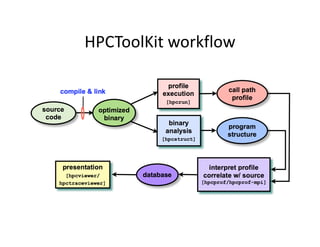








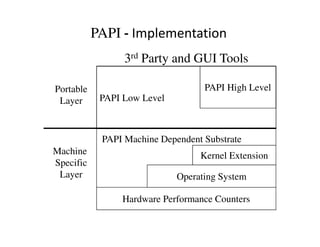










This document discusses application profiling and analysis. Profiling involves recording summary information during program execution to reflect performance behavior. It can expose bottlenecks and hotspots with low overhead. Profiling is implemented via sampling, which uses periodic interrupts, or instrumentation, which directly inserts measurement code. Tracing records significant execution points to reconstruct program behavior. Profiling provides summary statistics while tracing generates a large volume of event data. Tools like HPCToolkit use sampling and instrumentation to collect metrics that are correlated back to source code to analyze performance.












































![[ CNCF Q1 2024 ] Intro to Continuous Profiling and Grafana Pyroscope.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/cncfq12024introtocontinuousprofilingandgrafanapyroscope-240407162420-9c15afb7-thumbnail.jpg?width=640&height=640&fit=bounds)


