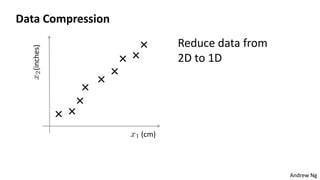
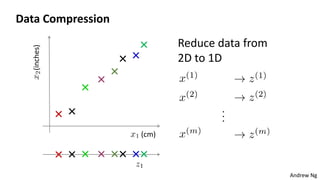
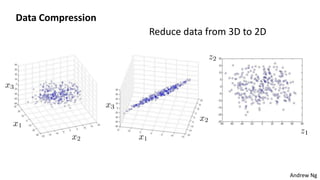
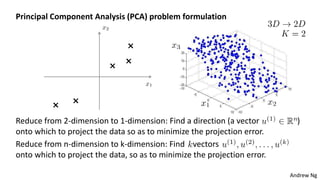
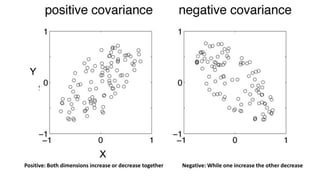
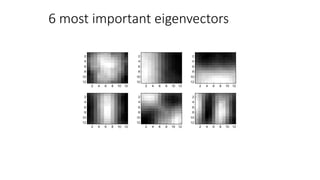
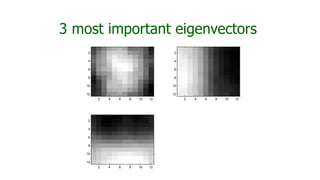
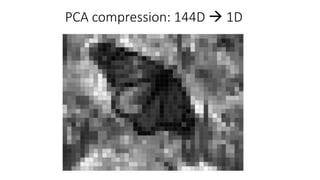
This document discusses dimensionality reduction techniques. It explains that dimensionality reduction can be used to simplify complex high-dimensional data by summarizing it with a lower dimensional real-valued vector while minimizing information loss. Principal component analysis (PCA) is described as a technique that finds the directions along which the variance of the data is maximized to reduce dimensionality. Examples of applying PCA to compress image data from high to lower dimensions are provided.