Download to read offline



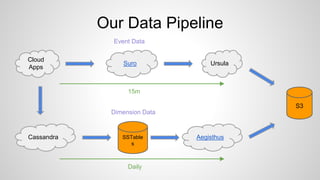






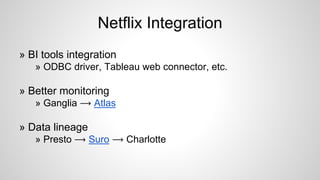



Presto is used at Netflix for interactive queries against their 10PB data warehouse stored in S3. Some key points: - Presto was chosen for its open source nature, speed, scalability on AWS, and integration with Hadoop. - Netflix contributes to Presto's development, including improvements to S3 support and Parquet integration. - Current work includes optimizations like vectorized reading and predicate pushdown, as well as integrating Presto with Netflix's BI tools and monitoring systems. - Future work includes improvements to resource management, data type support, and handling of large joins.








































































