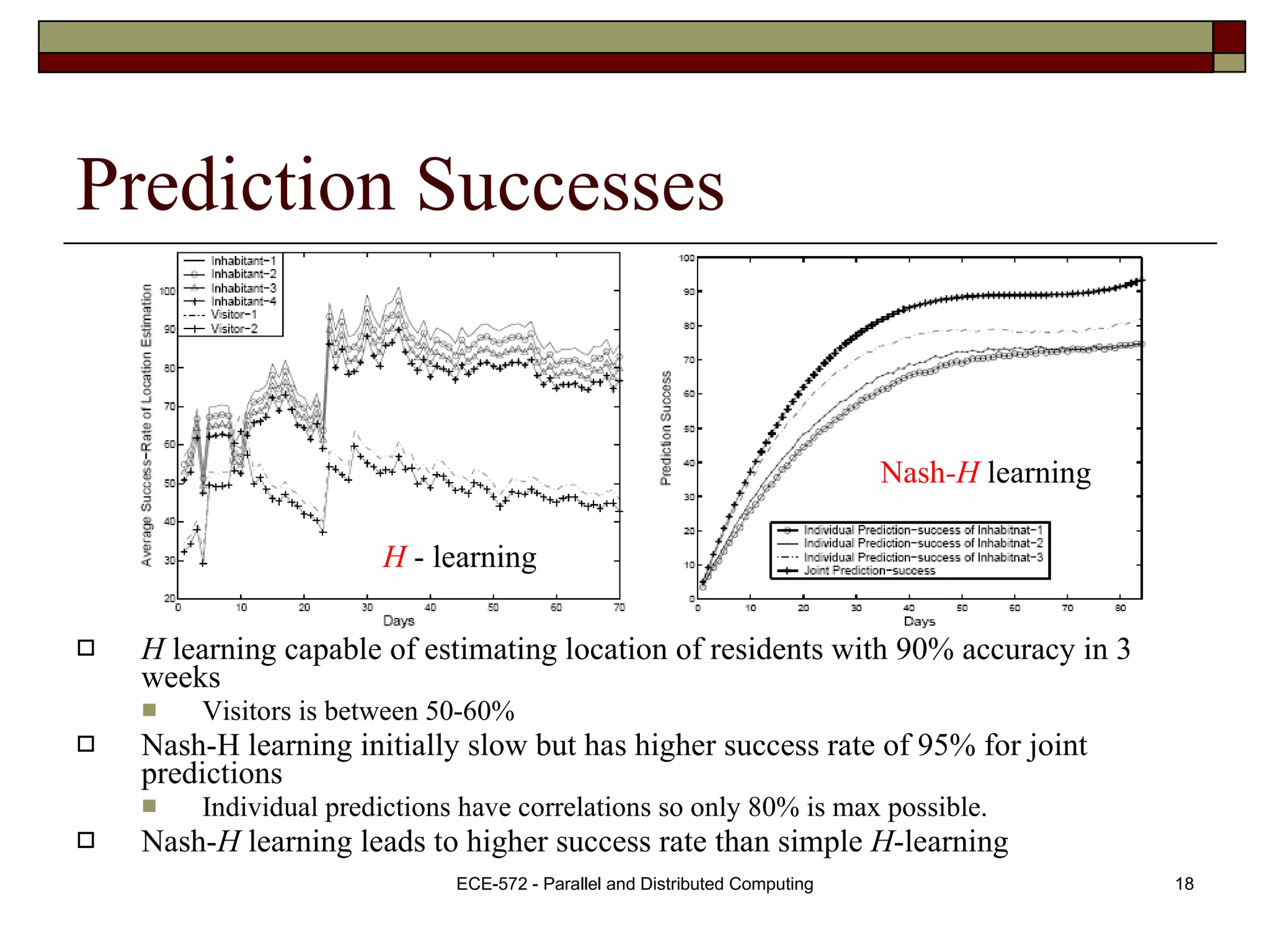
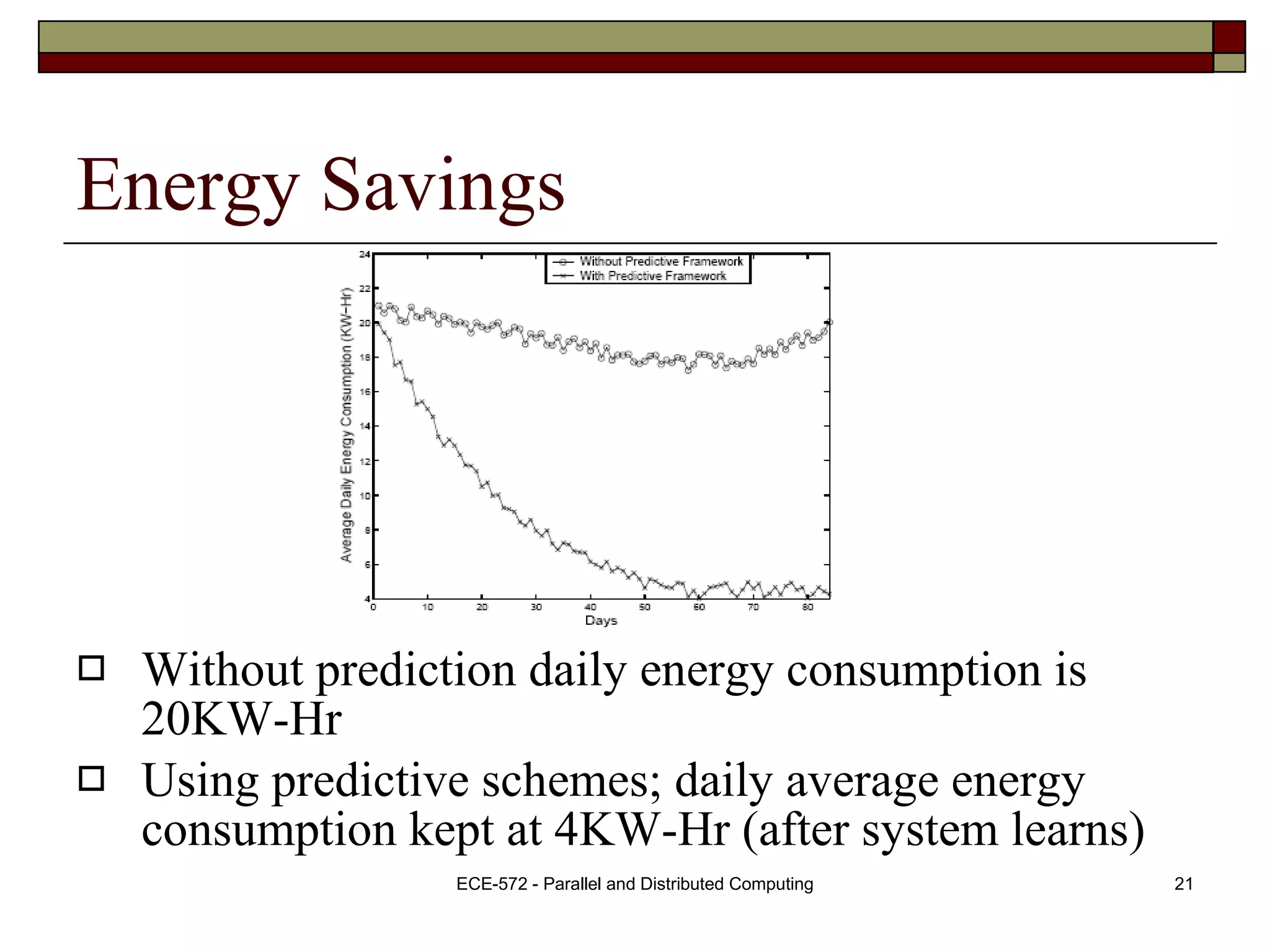
The document presents a Nash H-learning based approach for context-aware resource management in multi-inhabitant smart homes. It uses a predictive Nash-H learning framework to jointly predict the locations of multiple inhabitants to minimize overall uncertainty. This achieves better results than schemes optimized for individual predictions. Experiments show the approach can predict locations with over 90% accuracy, lower storage overhead, and reduce daily energy consumption by 80% compared to no prediction scheme.



![Entropy Entropy in information theory describes with how much randomness (or, alternatively, 'uncertainty') there is in a signal or random event. [ Shannon's entropy ] Entropy satisfies the assumptions : The measure should be proportional (continuous) changing the value of one of the probabilities by a very small amount should only change the entropy by a small amount. If all the outcomes are equally likely then increasing the samples should always increase the entropy. Entropy of the final result should be a weighted sum of the entropies.](https://image.slidesharecdn.com/presentation477/75/Presentation-4-2048.jpg)









































![Heuristic in AI (Rule of thumb) [what, why, how] What: Mental shortcuts that ...](https://cdn.slidesharecdn.com/ss_thumbnails/3-5-week-250901055018-f7c36e71-thumbnail.jpg?width=640&height=640&fit=bounds)



























