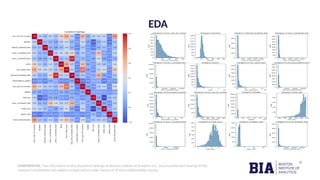
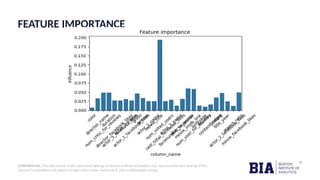
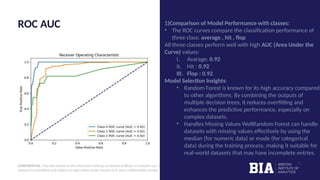
The document outlines a project aimed at predicting movie success using machine learning techniques based on IMDb scores, highlighting the significance of data analysis in making informed decisions in the film industry. It discusses various machine learning models employed to forecast box office performance and includes details on data preprocessing, model training, and performance metrics such as accuracy and ROC AUC. Overall, the presentation emphasizes the use of predictive modeling to determine the likelihood of a movie being a hit, average, or flop.