More Related Content

PDF

PDF

PDF
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料) 
PDF

PDF

PDF
PostgreSQLの運用・監視にまつわるエトセトラ 
PDF

PDF
アーキテクチャから理解するPostgreSQLのレプリケーション What's hot

PDF
PostgreSQLアーキテクチャ入門(PostgreSQL Conference 2012) 
PDF

PDF
Database Encryption and Key Management for PostgreSQL - Principles and Consid... 
PDF
PostgreSQLアーキテクチャ入門(INSIGHT OUT 2011) 
PDF

PDF
「今そこにある危機」を捉える ~ pg_stat_statements revisited 
PDF

PDF
PostgreSQLの新バージョン -PostgreSQL9.4- のご紹介 
PDF

PDF
perfを使ったPostgreSQLの解析(後編) 
PDF

PDF
perfを使ったPostgreSQLの解析(前編) 
PDF
外部データラッパによる PostgreSQL の拡張 
PDF
バックアップことはじめ JPUG第29回しくみ+アプリケーション分科会(2014-05-31) 
PDF

PDF
![[db tech showcase Tokyo 2017] D15: ビッグデータ x 機械学習の高速分析をVerticaで実現!by ヒューレット・パッ...](https://cdn.slidesharecdn.com/ss_thumbnails/d15-170912022443-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db tech showcase Tokyo 2017] D15: ビッグデータ x 機械学習の高速分析をVerticaで実現!by ヒューレット・パッ... 
ODP
PostgreSQL 9.2 新機能 - OSC 2012 Kansai@Kyoto 
PDF
PostgreSQL安定運用のコツ2009 @hbstudy#5 
PPTX
押さえておきたい、PostgreSQL 13 の新機能!!(Open Source Conference 2021 Online/Hokkaido 発表資料) Similar to 今秋リリース予定のPostgreSQL11を徹底解説

PDF
PostgreSQL 10 新機能 @オープンセミナー香川 2017 
PDF
PostgreSQL 10 新機能 @OSC 2017 Fukuoka 
PDF
各スペシャリストがお届け!データベース最新情報セミナー -PostgreSQL10- 
PPTX
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ... 
PDF
Postgre sql update_20170310 
PPTX
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料) 
PDF
YugabyteDBの実行計画を眺める(NewSQL/分散SQLデータベースよろず勉強会 #3 発表資料) 
PDF

PDF
Chugoku db 17th-postgresql-9.6 
PDF
PostgreSQL最新動向 ~カラムナストアから生成AI連携まで~ (Open Source Conference 2025 Tokyo/Spring ... 
PDF
PostgreSQL 11 New Features With Examples (Japanese) ![[db tech showcase Tokyo 2014] D21: Postgres Plus Advanced Serverはここが使える&9.4新機...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d21hppostgresplusadvancedserverv9-141120232610-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db tech showcase Tokyo 2014] D21: Postgres Plus Advanced Serverはここが使える&9.4新機... 
PDF
パーティションのATTACH時の注意ポイント (第49回PostgreSQLアンカンファレンス@東京 発表資料) 
PDF
PostgreSQL 9.2 新機能 - 新潟オープンソースセミナー2012 
PDF

PDF
PostgreSQL 11 New Features Japanese version (Beta 1) 
PDF

PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~ 
PDF

PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント More from Masahiko Sawada

PDF
行ロックと「LOG: process 12345 still waiting for ShareLock on transaction 710 afte... 
PDF

PDF

PDF
Transparent Data Encryption in PostgreSQL 
PDF
OSS活動のやりがいとそれから得たもの - PostgreSQLコミュニティにて - 
PDF
Transparent Data Encryption in PostgreSQL and Integration with Key Management... 
PDF
Bloat and Fragmentation in PostgreSQL 
PDF
Vacuum more efficient than ever 
PDF

PDF

PDF
OSS 開発ってどうやっているの? ~ PostgreSQL の現場から~ 
PDF
FDW-based Sharding Update and Future 
PDF
What’s new in 9.6, by PostgreSQL contributor 
PDF

PDF

PDF
Introduction VAUUM, Freezing, XID wraparound 
PDF

PPTX

PDF
Inside vacuum - 第一回PostgreSQLプレ勉強会 
PDF
今秋リリース予定のPostgreSQL11を徹底解説
- 1.
Copyright©2018 NTT Corp.All Rights Reserved.
今秋リリース予定のPostgreSQL 11を徹底解説
日本PostgreSQLユーザ会、NTT OSSセンタ
澤田 雅彦
2018/10/13 関西DB勉強会
- 2.
2Copyright©2018 NTT Corp.All Rights Reserved.
自己紹介
澤田 雅彦
sawada_masahiko
NTT OSSセンタ勤務
NTTデータ(2012年~)
NTTOSSセンタ(2016年~)
PostgreSQLの技術サポート
PostgreSQLの本体開発
Replication, Vacuum, Distributed Transaction、セキュリティ関連機
能
PostgreSQLの周辺ツール開発
pg_repack – オンラインメンテナンスツール
pg_bigm – 2-gram全文検索モジュール
講演
PGCon 2018@Ottawa
PostgresSQL Conference Japan (予定)
PGConf.ASIA@Tokyo (予定)
- 3.
3Copyright©2018 NTT Corp.All Rights Reserved.
• 5/24 beta1 リリース
• 6/28 beta2 リリース
• 8/9 beta3 リリース
• 9/20 beta4 リリース
• 10/11 RC リリース ← いまここ
• 10/18 GA リリース?
PostgreSQL 11
- 4.
4Copyright©2018 NTT Corp.All Rights Reserved.
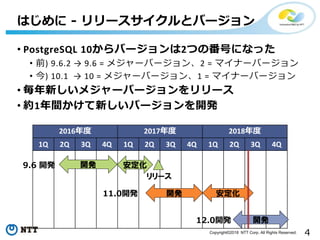
• PostgreSQL 10からバージョンは2つの番号になった
• 前) 9.6.2 → 9.6 = メジャーバージョン、2 = マイナーバージョン
• 今) 10.1 → 10 = メジャーバージョン、1 = マイナーバージョン
• 毎年新しいメジャーバージョンをリリース
• 約1年間かけて新しいバージョンを開発
はじめに - リリースサイクルとバージョン
2016年度 2017年度 2018年度
1Q 2Q 3Q 4Q 1Q 2Q 3Q 4Q 1Q 2Q 3Q 4Q
開発 安定化11.0開発
開発 安定化
リリース
9.6 開発
開発12.0開発
- 5.
5Copyright©2018 NTT Corp.All Rights Reserved.
• 最低限の機能を導入
→以降のリリースで少しずつ改善
• 例) レプリケーション
• 9.0 非同期レプリケーション
• 9.1 同期レプリケーション
• 9.2 カスケードレプリケーション
• 9.3 F/O高速化 など
○新機能を早い段階で使えるようになる
×各機能がどこまで使えるのかがわかりにくい
“出来ること”、”まだ出来ないこと”
をできるだけ分けて解説していきます
はじめに - PostgreSQLの開発スタイル
- 6.
6Copyright©2018 NTT Corp.All Rights Reserved.
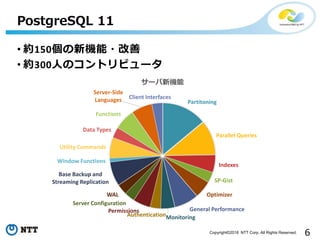
• 約150個の新機能・改善
• 約300人のコントリビュータ
PostgreSQL 11
Partitoning
Parallel Queries
Indexes
SP-Gist
Optimizer
General Performance
MonitoringAuthentication
Permissions
Server Configuration
WAL
Base Backup and
Streaming Replication
Window Functions
Utility Commands
Data Types
Functions
Server-Side
Languages Client Interfaces
サーバ新機能
- 7.
7Copyright©2018 NTT Corp.All Rights Reserved.
本日のお題 - PostgreSQL 11 新機能
• 性能
• テーブル・パーティショニ
ング
• パラレルクエリ
• JIT(Just In-Time)コンパイル
• カバリングインデックス
• 運用
• ALTER TABLE .. ADD COLUMN
• その他
• PROCEDURE
• オフラインでのファイル破
損検知
- 8.
- 9.
9Copyright©2018 NTT Corp.All Rights Reserved.
• 全150件中、約1割がテーブル・パーティショニングの改善
• Partition pruningの高速化
• 実行中のPartition pruning
• Hash partition
• Default partition
• Partition-wise join
• Partition-wise aggregation
• インデックス自動作成
• パーティションを跨いだ更新
• 外部子テーブルへの挿入
• 外部キーの対応
• FOR EACH TRIGGERの対応
テーブル・パーティショニングの機能改善が熱い
- 10.
10Copyright©2018 NTT Corp.All Rights Reserved.
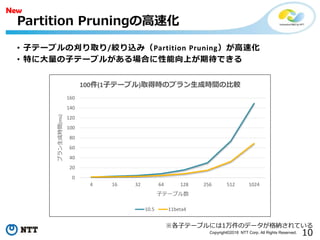
• 子テーブルの刈り取り/絞り込み(Partition Pruning)が高速化
• 特に大量の子テーブルがある場合に性能向上が期待できる
Partition Pruningの高速化
0
20
40
60
80
100
120
140
160
4 16 32 64 128 256 512 1024
プラン生成時間(ms)
子テーブル数
100件(1子テーブル)取得時のプラン生成時間の比較
10.5 11beta4
※各子テーブルには1万件のデータが格納されている
New
- 11.
11Copyright©2018 NTT Corp.All Rights Reserved.
• 実行中(Executionフェーズ)でもPartition Pruningが可能
になった
• 実行中に取得したデータを元に必要な子テーブルを絞り込む
• 実行計画作成時には子テーブルを絞り込めない場合に有用
• Prepared Statementの汎用プラン(generic plan)
• パーティション・テーブルとのNested loops join など
実行中のPartition pruning
New
- 12.
12Copyright©2018 NTT Corp.All Rights Reserved.
QUERY PLAN
-------------------------------------------------------------------------------------------
Nested Loop (actual time=0.038..0.375 rows=99 loops=1)
-> Index Only Scan using t_idx on t (actual time=0.012..0.036 rows=51 loops=1)
Heap Fetches: 51
-> Append (actual time=0.004..0.005 rows=2 loops=51)
-> Index Scan using tt0_i_idx on tt0 (actual time=0.003..0.003 rows=2 loops=51)
Index Cond: (i = t.i)
-> Index Scan using tt1_i_idx on tt1 (never executed)
Index Cond: (i = t.i)
-> Index Scan using tt2_i_idx on tt2 (never executed)
Index Cond: (i = t.i)
-> Index Scan using tt3_i_idx on tt3 (never executed)
Index Cond: (i = t.i)
-> Index Scan using tt4_i_idx on tt4 (never executed)
Index Cond: (i = t.i)
Nested loops join時のPartition pruning
• パーティション・テーブルと通常のテーブルを結合した時の
実行計画
• 結合に必要なInnerテーブルのみが使われていることがわかる
- 13.
13Copyright©2018 NTT Corp.All Rights Reserved.
=# EXPLAIN ANALYZE EXECUTE t(10);
QUERY PLAN
----------------------------------------------------------------
Append (actual time=0.023..0.047 rows=2 loops=1)
Subplans Removed: 9
-> Seq Scan on tt0 (actual time=0.022..0.045 rows=2 loops=1)
Filter: (i = $1)
Rows Removed by Filter: 195
Planning Time: 0.029 ms
Execution Time: 0.092 ms
(7 rows)
Prepared Statement時のPartition pruning
• Prepared Statementを使用してパーティション・テーブルへのスキャン
を実行した時の実行計画
• 汎用プラン(generic plan)では、実行計画作成時に子テーブルの絞り込み
は出来ないが、実行時に該当しない子テーブルへのスキャンは実行されない
• generic planの場合は、Filterの条件が「$N」になる
- 14.
14Copyright©2018 NTT Corp.All Rights Reserved.
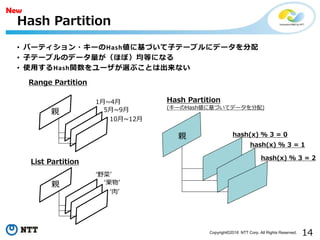
• パーティション・キーのHash値に基づいて子テーブルにデータを分配
• 子テーブルのデータ量が(ほぼ)均等になる
• 使用するHash関数をユーザが選ぶことは出来ない
Hash Partition
親
1月~4月
5月~9月
10月~12月
親
‘野菜’
‘果物’
‘肉’
親
Range Partition
List Partition
Hash Partition
(キーのHash値に基づいてデータを分配)
hash(x) % 3 = 0
hash(x) % 3 = 1
hash(x) % 3 = 2
New
- 15.
15Copyright©2018 NTT Corp.All Rights Reserved.
• CREATE TABLE ... PARTITION OF ... FOR VALUES WITH (
MODULUS n, REMAINDER i)
• n : 分割数
• i : (n - 1)以下の値で、各子テーブルに異なる値を指定する
• 例)4つの子テーブルを作成
• ... WITH ( MODULUS 4, REMAINDER 0);
• ... WITH ( MODULUS 4, REMAINDER 1);
• ... WITH ( MODULUS 4, REMAINDER 2);
• ... WITH ( MODULUS 4, REMAINDER 3);
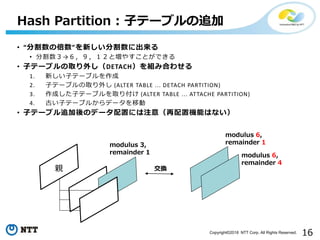
Hash Partition : 作成
- 16.
16Copyright©2018 NTT Corp.All Rights Reserved.
• “分割数の倍数”を新しい分割数に出来る
• 分割数3→6,9,12と増やすことができる
• 子テーブルの取り外し(DETACH)を組み合わせる
1. 新しい子テーブルを作成
2. 子テーブルの取り外し (ALTER TABLE ... DETACH PARTITION)
3. 作成した子テーブルを取り付け (ALTER TABLE ... ATTACHE PARTITION)
4. 古い子テーブルからデータを移動
• 子テーブル追加後のデータ配置には注意(再配置機能はない)
Hash Partition : 子テーブルの追加
modulus 3,
remainder 1
親
modulus 6,
remainder 4
modulus 6,
remainder 1
交換
- 17.
17Copyright©2018 NTT Corp.All Rights Reserved.
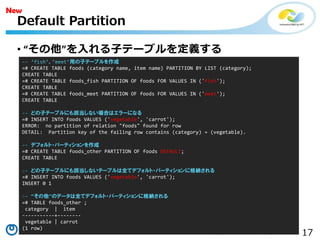
• “その他”を入れる子テーブルを定義する
Default Partition
-- ‘fish’、’meet’用の子テーブルを作成
=# CREATE TABLE foods (category name, item name) PARTITION BY LIST (category);
CREATE TABLE
=# CREATE TABLE foods_fish PARTITION OF foods FOR VALUES IN ('fish');
CREATE TABLE
=# CREATE TABLE foods_meet PARTITION OF foods FOR VALUES IN ('meet');
CREATE TABLE
-- どの子テーブルにも該当しない場合はエラーになる
=# INSERT INTO foods VALUES ('vegetable', 'carrot');
ERROR: no partition of relation "foods" found for row
DETAIL: Partition key of the failing row contains (category) = (vegetable).
-- デフォルト・パーティションを作成
=# CREATE TABLE foods_other PARTITION OF foods DEFAULT;
CREATE TABLE
-- どの子テーブルにも該当しないテーブルは全てデフォルト・パーティションに格納される
=# INSERT INTO foods VALUES ('vegetable', 'carrot');
INSERT 0 1
-- “その他”のデータは全てデフォルト・パーティションに格納される
=# TABLE foods_other ;
category | item
-----------+--------
vegetable | carrot
(1 row)
New
- 18.
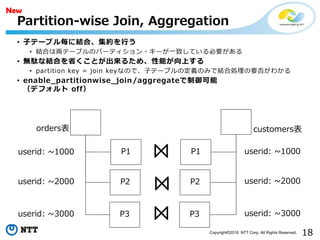
18Copyright©2018 NTT Corp.All Rights Reserved.
• 子テーブル毎に結合、集約を行う
• 結合は両テーブルのパーティション・キーが一致している必要がある
• 無駄な結合を省くことが出来るため、性能が向上する
• partition key = join keyなので、子テーブルの定義のみで結合処理の要否がわかる
• enable_partitionwise_join /aggregateで制御可能
(デフォルト off)
Partition-wise Join, Aggregation
P1
P2
P3
P1
P2
P3
⋈
⋈
⋈
orders表 customers表
userid: ~1000
userid: ~2000
userid: ~3000
userid: ~1000
userid: ~2000
userid: ~3000
New
- 19.
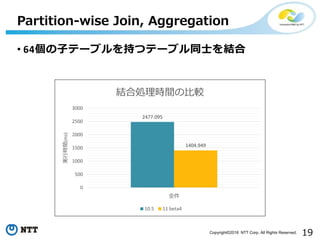
19Copyright©2018 NTT Corp.All Rights Reserved.
• 64個の子テーブルを持つテーブル同士を結合
Partition-wise Join, Aggregation
2477.095
1404.949
0
500
1000
1500
2000
2500
3000
全件
実行時間(ms)
結合処理時間の比較
10.5 11 beta4
- 20.
20Copyright©2018 NTT Corp.All Rights Reserved.
• PostgreSQL 11で大幅に改善!
• 性能面
• Partition pruningの高速化
• 実行時のPartition pruning
• Partition-wise Join/Aggregation
• 運用面
• Hash Partition
• Default Partition
• “パーティションを跨る更新”も出来るので、Default Partitionから新
しい子テーブルへのデータ移動も簡単
• その他、子テーブルでのインデックス自動作成など便利
な機能も導入されている
ここまでのまとめ - テーブル・パーティショニング -
- 21.
21Copyright©2018 NTT Corp.All Rights Reserved.
• パーティション・テーブル”への”外部キー制約は未サポート
• 基本的な機能は揃っている印象
• PostgreSQL 10 → 11でかなりパワーアップした
• 現在は性能改善がメインで開発が続けられている
PostgreSQL 11でできないこと
- 22.
- 23.
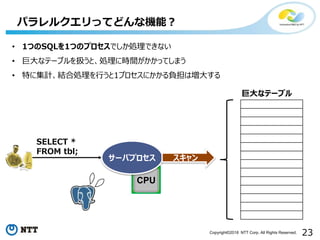
23Copyright©2018 NTT Corp.All Rights Reserved.
CPU
パラレルクエリってどんな機能?
サーバプロセス
巨大なテーブル
SELECT *
FROM tbl;
• 1つのSQLを1つのプロセスでしか処理できない
• 巨大なテーブルを扱うと、処理に時間がかかってしまう
• 特に集計、結合処理を行うと1プロセスにかかる負担は増大する
スキャン
- 24.
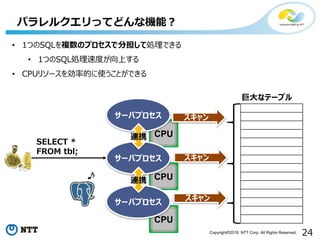
24Copyright©2018 NTT Corp.All Rights Reserved.
CPU
CPU
CPU
サーバプロセス
パラレルクエリってどんな機能?
巨大なテーブル
SELECT *
FROM tbl;
サーバプロセス
サーバプロセス
スキャン
スキャン
スキャン
連携
連携
• 1つのSQLを複数のプロセスで分担して処理できる
• 1つのSQL処理速度が向上する
• CPUリソースを効率的に使うことができる
- 25.
25Copyright©2018 NTT Corp.All Rights Reserved.
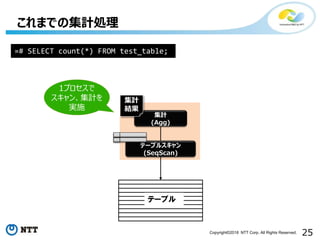
これまでの集計処理
集計
(Agg)
集計
結果
テーブルスキャン
(SeqScan)
テーブル
=# SELECT count(*) FROM test_table;
1プロセスで
スキャン、集計を
実施
- 26.
26Copyright©2018 NTT Corp.All Rights Reserved.
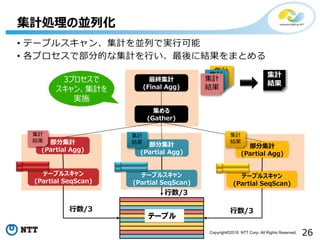
集計処理の並列化
部分集計
(Partial Agg)
部分集計
(Partial Agg)
部分集計
(Partial Agg)
集める
(Gather)
集計
結果
集計
結果
集計
結果
集計
結果
テーブルスキャン
(Partial SeqScan)
テーブルスキャン
(Partial SeqScan)
テーブルスキャン
(Partial SeqScan)
集計
結果
集計
結果
テーブル
集計
結果
• テーブルスキャン、集計を並列で実行可能
• 各プロセスで部分的な集計を行い、最後に結果をまとめる
行数/3
行数/3
行数/3
最終集計
(Final Agg)
3プロセスで
スキャン、集計を
実施
- 27.
27Copyright©2018 NTT Corp.All Rights Reserved.
QUERY PLAN
----------------------------------------------------------------------------------------------------
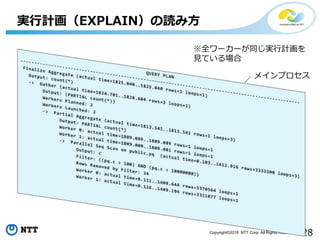
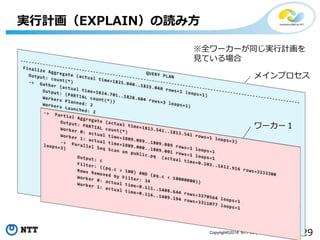
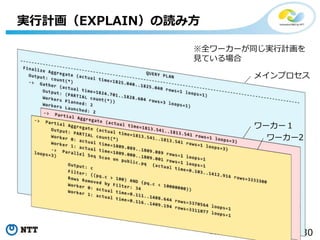
Finalize Aggregate (actual time=1825.040..1825.040 rows=1 loops=1)
Output: count(*)
-> Gather (actual time=1824.701..1828.604 rows=3 loops=1)
Output: (PARTIAL count(*))
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (actual time=1813.541..1813.541 rows=1 loops=3)
Output: PARTIAL count(*)
Worker 0: actual time=1809.089..1809.089 rows=1 loops=1
Worker 1: actual time=1809.000..1809.001 rows=1 loops=1
-> Parallel Seq Scan on public.pq (actual time=0.103..1412.916 rows=3333300 loops=3)
Output: c
Filter: ((pq.c > 100) AND (pq.c < 10000000))
Rows Removed by Filter: 34
Worker 0: actual time=0.111..1408.644 rows=3370564 loops=1
Worker 1: actual time=0.116..1409.194 rows=3311077 loops=1
実行計画(EXPLAIN)の読み方
- 28.
- 29.
- 30.
- 31.
31Copyright©2018 NTT Corp.All Rights Reserved.
• SQL
• CREATE INDEX
• UNION
• CREATE TABLE AS、SELECT INTO、CREATE MATERIALIZED VIEW
• LIMIT
• ノード
• Hash Join(強化された)
• Append
• “読み込み”が並列化されている
• 書き込みの並列化はまだ
PostgreSQL 11でサポートされた機能
- 32.
32Copyright©2018 NTT Corp.All Rights Reserved.
• max_parallel_maintenance_workersでワーカー数を指定
(デフォルト2)
• B-treeインデックスのみサポート
• テーブルの読み込み、ソートを並列で実行
• 並列度はテーブルサイズに応じて変化する
• 並列度の指定はテーブルに対して行う
ALTER TABLE ... SET (parallel_workers = 5);
Parallel CRAETE INDEX
New
- 33.
33Copyright©2018 NTT Corp.All Rights Reserved.
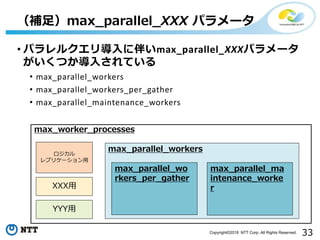
• パラレルクエリ導入に伴いmax_parallel_XXXパラメータ
がいくつか導入されている
• max_parallel_workers
• max_parallel_workers_per_gather
• max_parallel_maintenance_workers
(補足)max_parallel_XXX パラメータ
max_worker_processes
max_parallel_workers
max_parallel_wo
rkers_per_gather
max_parallel_ma
intenance_worke
r
ロジカル
レプリケーション用
XXX用
YYY用
- 34.
34Copyright©2018 NTT Corp.All Rights Reserved.
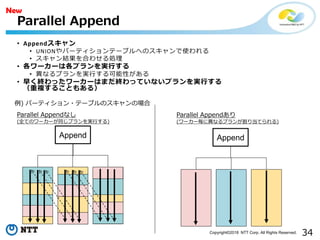
• Appendスキャン
• UNIONやパーティションテーブルへのスキャンで使われる
• スキャン結果を合わせる処理
• 各ワーカーは各プランを実行する
• 異なるプランを実行する可能性がある
• 早く終わったワーカーはまだ終わっていないプランを実行する
(重複することもある)
Parallel Append
Append Append
Parallel Appendなし
(全てのワーカーが同じプランを実行する)
Parallel Appendあり
(ワーカー毎に異なるプランが割り当てられる)
例) パーティション・テーブルのスキャンの場合
New
- 35.
35Copyright©2018 NTT Corp.All Rights Reserved.
QUERY PLAN
--------------------------------------------------------------------------------------------
Gather (actual time=0.963..1135.014 rows=4999999 loops=1)
Output: pa1.c
Workers Planned: 3
Workers Launched: 3
-> Parallel Append (actual time=0.086..624.560 rows=1250000 loops=4)
Worker 0: actual time=0.067..807.245 rows=1697612 loops=1
Worker 1: actual time=0.094..835.660 rows=1576250 loops=1
Worker 2: actual time=0.075..825.055 rows=1642969 loops=1
-> Parallel Seq Scan on public.pa1 (actual time=0.043..396.735 rows=999999 loops=1)
Output: pa1.c
Worker 2: actual time=0.043..396.735 rows=999999 loops=1
-> Parallel Seq Scan on public.pa2 (actual time=0.069..418.038 rows=1000000 loops=1)
Output: pa2.c
Worker 1: actual time=0.069..418.038 rows=1000000 loops=1
-> Parallel Seq Scan on public.pa3 (actual time=0.042..353.192 rows=1000000 loops=1)
Output: pa3.c
Worker 0: actual time=0.042..353.192 rows=1000000 loops=1
-> Parallel Seq Scan on public.pa4 (actual time=0.031..182.822 rows=500000 loops=2)
Output: pa4.c
Worker 0: actual time=0.028..197.608 rows=564096 loops=1
Worker 1: actual time=0.034..168.036 rows=435904 loops=1
-> Parallel Seq Scan on public.pa5 (actual time=0.038..85.501 rows=250000 loops=4)
Output: pa5.c
Worker 0: actual time=0.032..48.414 rows=133516 loops=1
Worker 1: actual time=0.031..48.337 rows=140346 loops=1
Worker 2: actual time=0.034..224.261 rows=642970 loops=1
Parallel Appendの実行計画
- 36.
36Copyright©2018 NTT Corp.All Rights Reserved.
PostgreSQL 11で出来ること
• SQL
• SELECT系
• CREATE INDEX
• CREATE MATERIALIZED VIEW
• INSERT INTO SELECT
• スキャン
• Seq Scan
• Index Scan
• Index Only Scan
• Bitmap Index Scan/Heap Scan
• Append
• 結合
• Nested Loops Join
• Merge Join
• Hash Join
- 37.
- 38.
- 39.
39Copyright©2018 NTT Corp.All Rights Reserved.
• ソフトウェアの実行時にコードのコンパイルを行い実行
速度の向上を図る
• 反復される処理を、インタプリタ形式→コンパイルして
バイナリを実行、にすることで高速化する
JITコンパイルとは?
- 40.
40Copyright©2018 NTT Corp.All Rights Reserved.
• 対応しているJITコンパイラ
• LLVM
• 他のJITコンパイラも利用可能な作りにはなっている
• 対象の処理
• 式の評価(WHERE句など)
• タプル(行)の変形
• インライン化
• CPUネック&長時間実行するクエリに有効な手法
• 分析、レポート作成など
• デフォルトはOFF
PostgreSQLのJITコンパイル
https://www.phoronix.com/scan.php?page=news_item&px=PostgreSQL-LLVM-JIT-Landing
New
- 41.
41Copyright©2018 NTT Corp.All Rights Reserved.
• llvm 3.9以上が推奨
• confiugreにて、--with-llvmを指定する
• llvmの他、clangやC++コンパイラも必要
• llvm_configとclangへのパスも指定する(LLVM_CONFIG, CLANG)
• llvm-configへPATHを通しておく
• 設定値
• jit : JITコンパイルを有効にするかどうか(デフォルト off)
• jit_above_cost : JITコンパイル機能を使う閾値
• jit_inline_aboce_cost : インライン化を使う閾値
• jit_optimize_aboce_cost : JITの最適化を使う閾値
• jit_provider : 使用するLLVMライブラリ
JITコンパイル(LLVM)を利用する
- 42.
42Copyright©2018 NTT Corp.All Rights Reserved.
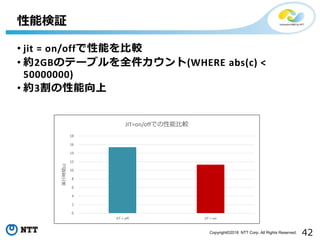
• jit = on/offで性能を比較
• 約2GBのテーブルを全件カウント(WHERE abs(c) <
50000000)
• 約3割の性能向上
性能検証
0
2
4
6
8
10
12
14
16
18
JIT = off JIT = on
実行時間(s)
JIT=on/offでの性能比較
- 43.
43Copyright©2018 NTT Corp.All Rights Reserved.
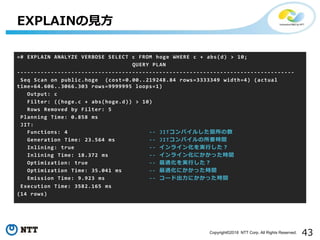
=# EXPLAIN ANALYZE VERBOSE SELECT c FROM hoge WHERE c + abs(d) > 10;
QUERY PLAN
----------------------------------------------------------------------------------
Seq Scan on public.hoge (cost=0.00..219248.84 rows=3333349 width=4) (actual
time=64.606..3066.303 rows=9999995 loops=1)
Output: c
Filter: ((hoge.c + abs(hoge.d)) > 10)
Rows Removed by Filter: 5
Planning Time: 0.858 ms
JIT:
Functions: 4 -- JITコンパイルした箇所の数
Generation Time: 23.564 ms -- JITコンパイルの所要時間
Inlining: true -- インライン化を実行した?
Inlining Time: 18.372 ms -- インライン化にかかった時間
Optimization: true -- 最適化を実行した?
Optimization Time: 35.041 ms -- 最適化にかかった時間
Emission Time: 9.923 ms -- コード出力にかかった時間
Execution Time: 3582.165 ms
(14 rows)
EXPLAINの見方
- 44.
- 45.
45Copyright©2018 NTT Corp.All Rights Reserved.
• クエリ処理において”インデックスのみのスキャン”は最
強の方法の一つ
• SQLに出てくる全ての列がインデックスに含まれている
ことを”カバリングインデックス”という
• PostgreSQL 11では、INCLUDE句を使うことでインデック
スキー値以外の列もインデックスに含めることができる
カバリング・インデックス(Covering Index)
New
- 46.
46Copyright©2018 NTT Corp.All Rights Reserved.
• INCLUDE句でインデックスに含める列を指定する
• INCLUDE句に指定した列は制約の対象にならない
インデックス・キーとは別の列を含める
=# CREATE TABLE users
(user_id int, dep_name text, name text)
=# CREATE UNIQUE INDEX idx
ON users (user_id) INCLUDE (dep_name, name);
=# INSERT INTO users VALUES (0, ‘総務部’, ‘澤田雅彦’),
(1, ‘人事部’, ‘澤田雅彦’)
-- name列はインデックスキーではないけど、Index Only Scanで処理可能
=# EXPLAIN SELECT user_id, dep_name, name
FROM users
WHERE user_id < 10;
QUERY PLAN
-----------------------------------------------------------------------
Index Only Scan using users_idx_normal on users (cost=0.13..4.15 rows=1
width=40)
Index Cond: (user_id = 10)
(2 rows)
- 47.
47Copyright©2018 NTT Corp.All Rights Reserved.
• バージョン11ではB-treeのみ対応
• B-treeインデックスのリーフノード(ツリーの末端)にのみデ
ータが保持される
• INCLUDE句に“式”は指定できない
• 大きい列を含める際はインデックスサイズに注意
• Index Only Scanでのみ有効
• Visibility Map等、Index Only Scanに関わるその他の条件にも気
をつける必要がある
使用上の注意点
- 48.
- 49.
49Copyright©2018 NTT Corp.All Rights Reserved.
• スキーマ変更のみ(一瞬で終わる)
• 列の削除
• DEFAULT NULLで列をテーブルの末尾に追加する※
• テーブルの書き換えが必要(時間かかる)
• DEFAULT NULL以外で列をテーブルの末尾に追加する
• 列を末尾以外に追加する(テーブルの作り直し)
※データ型にも依存する
これまでの列の追加と削除(~ver.10)
- 50.
50Copyright©2018 NTT Corp.All Rights Reserved.
• スキーマ変更のみ(一瞬で終わる)
• 列の削除
• DEFAULT NULLで列をテーブルの末尾に追加する※
• DEFAULT NULL以外で列をテーブルの末尾に追加する
• テーブルの書き換えが必要(時間かかる)
• 列を末尾以外に追加する(テーブルの作り直し)
ただし、ロックレベルは変わっていない(排他ロック)
ので注意が必要
※データ型にも依存する
これまでの列の追加と削除(ver.11~)
New
- 51.
- 52.
52Copyright©2018 NTT Corp.All Rights Reserved.
• 新しいオブジェクトPROCEDUREをサポート
• “戻り値のない関数”のようなもの
• CREATE PROCEDUREで作成し、CALLで使用する
• PROCEDURE内でトランザクション制御が可能
• PL/Perl, PL/Python, PL/Tcl、SPIでもトランザクション制
御が可能
CREATE PROCEDURE
New
- 53.
53Copyright©2018 NTT Corp.All Rights Reserved.
=# CREATE PROCEDURE test()
LANGUAGE plpgsql
AS $$
BEGIN
FOR i IN 0..9 LOOP
INSERT INTO test1 (a) VALUES (i);
IF i % 2 = 0 THEN
COMMIT;
ELSE
ROLLBACK;
END IF;
END LOOP;
END;
$$;
CREATE PROCEDURE
=# CALL test();
CALL
使ってみる
=# CREATE PROCEDURE test_python()
LANGUAGE plpython
AS $$
for i in range (0, 10);
plpy.execute(
“INSERT INTO test (a) VALUES (%d)” % i
)
if i % 2 == 0
plpy.commit()
else
plpy.rollback()
$$;
CREATE PROCEDURE
=# CALL test_python();
CALL
PL/pgSQL PL/python
- 54.
54Copyright©2018 NTT Corp.All Rights Reserved.
• ネストしたトランザクション制御も可能
• ただし、関数(FUNCTION)から呼び出されたPROCEDUREでは制御できない
• 挙動には”慣れ”が必要
ネストしたトランザクション制御
CREATE PROCEDURE tx1()
LANGUAGE plpgsql AS $$
BEGIN
INSERT INTO test1 VALUES(1);
CALL tx2();
INSERT INTO test1 VALUES (4);
ROLLBACK;
END; $$;
CREATE PROCEDURE tx2()
LANGUAGE plpgsql AS $$
BEGIN
INSERT INTO test1 VALUES(2);
COMMIT;
INSERT INTO test1 VALUES (3);
END; $$;
Q. 「CALL tx1();」を実行すると、テーブルtest1の中身はどうなる?
A: {2,3} B: {1,2} C: {}
- 55.
55Copyright©2018 NTT Corp.All Rights Reserved.
• ネストしたトランザクション制御も可能
• ただし、関数(FUNCTION)から呼び出されたPROCEDUREでは制御できない
• 挙動には”慣れ”が必要
ネストしたトランザクション制御
CREATE PROCEDURE tx1()
LANGUAGE plpgsql AS $$
BEGIN
INSERT INTO test1 VALUES(1);
CALL tx2();
INSERT INTO test1 VALUES (4);
ROLLBACK;
END; $$;
CREATE PROCEDURE tx2()
LANGUAGE plpgsql AS $$
BEGIN
INSERT INTO test1 VALUES(2);
COMMIT;
INSERT INTO test1 VALUES (3);
END; $$;
Q. 「CALL tx1();」を実行すると、テーブルtest1の中身はどうなる?
A: {2,3} B: {1,2} C: {}
- 56.
56Copyright©2018 NTT Corp.All Rights Reserved.
• SAVEPOINT、2相コミットは未対応
• 挙動の理解には”慣れ”が必要(?)
• 単純にSQLを順番に実行しているだけ、と考えることができる
注意点
CREATE PROCEDURE tx1()
LANGUAGE plpgsql AS $$
BEGIN
INSERT INTO test1 VALUES(1);
CALL tx2();
INSERT INTO test1 VALUES (4);
ROLLBACK;
END; $$;
CREATE PROCEDURE tx2()
LANGUAGE plpgsql AS $$
BEGIN
INSERT INTO test1 VALUES(2);
COMMIT;
INSERT INTO test1 VALUES (3);
END; $$;
BEGIN;
INSERT INTO test1 VALUES (1);
INSERT INTO test2 VALUES (2);
COMMIT;
BEGIN;
INSERT INTO test2 VALUES (3);
INSERT INTO test2 VALUES (4);
ROLLBACK;
CALL tx1();
- 57.
- 58.
58Copyright©2018 NTT Corp.All Rights Reserved.
• pg_verify_checksumコマンド
• 停止しているPostgreSQLに対して実行する
• チェックサムが有効になっている場合に利用可能
• チェックサムはinitdb時でのみ指定可能
• エラーがある場合は、正常なバックアップからの復旧が必要
オフラインでデータベースファイルの破損を検知
$ pg_verify_checksums -D pgdata
Checksum scan completed
Data checksum version: 1
Files scanned: 932
Blocks scanned: 2906
Bad checksums: 0
New
- 59.
59Copyright©2018 NTT Corp.All Rights Reserved.
• PostgreSQL 11視機能検証結果 (Beta 1)
• https://h50146.www5.hpe.com/products/software/oe/linux/mainstr
eam/support/lcc/pdf/PostgreSQL_11_New_Features_beta1_ja_2018
0525-1.pdf
• PostgreSQL 11 検証レポートレポート
• https://www.sraoss.co.jp/tech-blog/wp-
content/uploads/2018/07/pg11_report-6.pdf
• PostgreSQL11のJITコンパイリングを試す
• http://kkida-galaxy.blogspot.com/2018/04/postgresql11-with-jit-
01.html
• PostgreSQL 11: something for everyone
• https://lwn.net/Articles/764515/
• Partition Elimination in PostgreSQL 11
• https://blog.2ndquadrant.com/partition-elimination-postgresql-11/
• カスタムプランと汎用プラン
• https://www.slideshare.net/MasaoFujii/ss-84213090
参考資料
- 60.
- 61.
61Copyright©2018 NTT Corp.All Rights Reserved.
• パラレルクエリはどのように動く?
• 本日の講演で解説してみましたがいかがでしょうか?
• スキーマはpublicが初期値だけど、本番環境では変更し
て使う方が良い?
• 特におすすめのやり方はありませんが、同名のテーブル等があ
る場合は、新規にスキーマを使った方が良いと思います。
事前に頂いた質問
- 62.
- 63.
63Copyright©2018 NTT Corp.All Rights Reserved.
• Prepared Statementにおいて利用されるプランの種類
• カスタムプラン(cusom plan)
• バインド変数を実際の値を考慮して生成されるプラン
• プランキャッシュは出来ない
• 通常のSQL処理は常にカスタムプランを利用しているとも言える
• 見分け方:”Filter”に実際の値が入っている
例) a.id = 100
• 汎用プラン(generic plan)
• バインド変数を実際の値を考慮しないで生成されるプラン
• プランキャッシュが出来る
• バインド変数が不明なままプランを生成するので、実際のバイン値によ
っては、適切でないプランを選んでしまう可能性がある
• 例) Seq Scanのプランをキャッシュしたけど本当はIndex Scanが最適
• 見分け方:”Filter”に変数が入っている
例) a.id = $1
(補足) カスタムプランと汎用プラン
- 64.
64Copyright©2018 NTT Corp.All Rights Reserved.
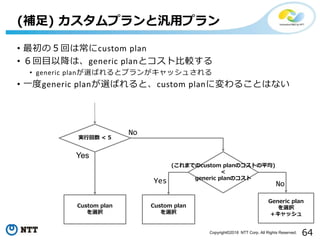
(補足) カスタムプランと汎用プラン
実行回数 < 5
Custom plan
を選択
Generic plan
を選択
+キャッシュ
Custom plan
を選択
(これまでのcustom planのコストの平均)
<
generic planのコスト
• 最初の5回は常にcustom plan
• 6回目以降は、generic planとコスト比較する
• generic planが選ばれるとプランがキャッシュされる
• 一度generic planが選ばれると、custom planに変わることはない
Yes
No
Yes
No
- 65.
65Copyright©2018 NTT Corp.All Rights Reserved.
(補足)サブトランザクション
CREATE or replace PROCEDURE tx1()
LANGUAGE plpgsql AS $$
BEGIN
INSERT INTO test1 VALUES(1);
BEGIN
CALL tx2();
END;
INSERT INTO test1 VALUES (4);
COMMIT;
END; $$;
CREATE or replace PROCEDURE tx2()
LANGUAGE plpgsql AS $$
BEGIN
INSERT INTO test1 VALUES(2);
INSERT INTO test1 VALUES (3);
ROLLBACK;
END; $$;
Q. 「CALL tx1();」を実行すると、テーブルtest1の中身はどうなる?
A: {4} B: {1,4} C: {}
• BEGIN .. ENDを使用してもサブトランザクションのようには動かない
• INSERT (1)はROLLBACKされる
- 66.
66Copyright©2018 NTT Corp.All Rights Reserved.
CREATE or replace PROCEDURE tx2()
LANGUAGE plpgsql AS $$
BEGIN
INSERT INTO test1 VALUES(2);
INSERT INTO test1 VALUES (3);
ROLLBACK;
END; $$;
(補足)サブトランザクション
CREATE or replace PROCEDURE tx1()
LANGUAGE plpgsql AS $$
BEGIN
INSERT INTO test1 VALUES(1);
BEGIN
CALL tx2();
EXCEPTION WHEN others THEN NULL;
END;
INSERT INTO test1 VALUES (4);
COMMIT;
END; $$;
tx2()でのROLLBACKをEXCEPTIONで補足することで、
INSERT (1)をコミット出来る
(上記の例では、{1,4}がテーブルに格納される)
• サブトランザクションのようにしたい場合は、BEGIN ... EXCEPTIONと組み
合わせる