Download as PDF, PPTX










































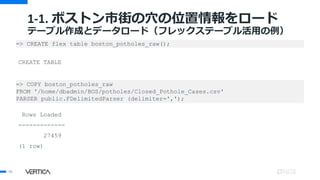
![ボストン市街の道路の「穴」
Block Pothole Density:
各ブロックの穴の密度を計算
46
potholes ph blocks_idx roads rd
Spatial Join
[ph.id, block_id]
Spatial Join
[rd.id, block_id]
Group By
[block_id, count(ph.id)]
Group By
[block_id, count(rd.id)]
Join
[block_id, count(ph.id)/count(rd.id)]
Query Result
x
x
x
x pothole road
Block Pothole Density = 3/2
# potholes
# roads
補修すべきボストン市街の道路を分析する](https://image.slidesharecdn.com/d15-170912022443/85/db-tech-showcase-Tokyo-2017-D15-Vertica-by-46-320.jpg)



























ビッグデータと叫ばれ始め早数年。蓄積した大規模データを活用するための一つの手段として、「機械学習(Machine Learning)」や「地理空間分析(Geospatial Analytics)」が注目されています。本セッションでは、ビッグデータ用データベースとしてのVerticaが備えているインデータベース機械学習機能や地理空間分析機能を使って、容易かつ高速に予知保全(Predictive Maintenance)をはじめとする予測分析を行えることを具体例を交えながら、時にディープに解説します。


![GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/20170906dbtsgpussdacceleratespostgresqljp-170906073226-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] D21: ついに Red Hat Enterprise Linuxで SQL Serverが使...](https://cdn.slidesharecdn.com/ss_thumbnails/d21-170912022444-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] D35: 何を基準に選定すべきなのか!? ~ビッグデータ×IoT×AI時代のデータベースのアー...](https://cdn.slidesharecdn.com/ss_thumbnails/d35-170912024713-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] E34: データベース・サービスを好きなところで動かそう Db2 Warehouse by 日...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase2017e34-170911070313-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] A15: レプリケーションを使用したデータ分析基盤構築のキモ(事例)by 株式会社インサイトテ...](https://cdn.slidesharecdn.com/ss_thumbnails/a15-170912020524-thumbnail.jpg?width=640&height=640&fit=bounds)



![[D13] Disaster Recovery環境をOracle Standard Editionでつくる by Miyuki Ohasi](https://cdn.slidesharecdn.com/ss_thumbnails/d13iti-140625204153-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[A23] Oracle移行を簡単に。レプリケーションテクノロジーを使いこなす by Keishi Miyachi](https://cdn.slidesharecdn.com/ss_thumbnails/a23iti-140625000518-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)








![[data analytics showcase] B16: Live Demo! データ分析基盤を支えるデータレプリケーション技術とデータワークロード分...](https://cdn.slidesharecdn.com/ss_thumbnails/waf1saonq7kghgwbprmc-signature-25a0ea6711cd6aa4d4a08a1137bfd90f9f8e7850cd850623d7101ef7c30a9b4c-poli-161007061148-thumbnail.jpg?width=640&height=640&fit=bounds)






![[db tech showcase Tokyo 2014] B33: 超高速データベースエンジンでのビッグデータ分析活用事例 by 株式会社日立製作所 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b33-141127184852-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)





















![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)










