







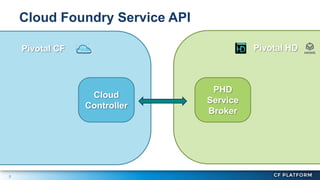

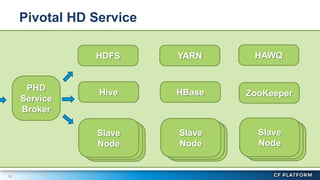
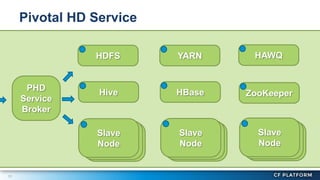


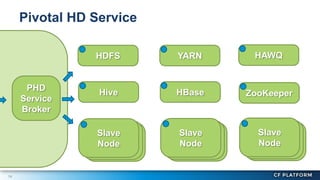

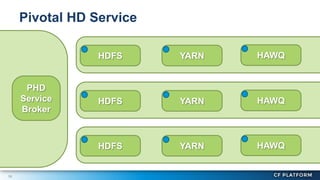
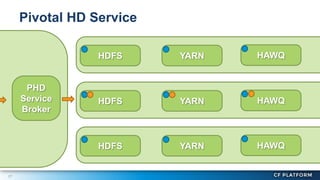

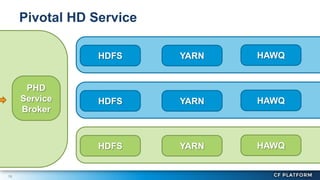
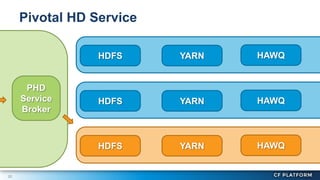


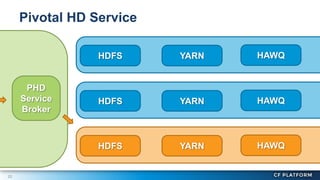



Pivotal Hadoop on Cloud Foundry (PHD) allows Hadoop resources to be provisioned for data-centric Cloud Foundry applications. PHD integrates Hadoop Distributed File System (HDFS), YARN, and HAWQ with Cloud Foundry through a service broker. This allows Cloud Foundry applications to leverage HDFS for storage, YARN for batch processing, and HAWQ for analytics on large datasets. PHD supports various deployment options including shared or exclusive clusters that can be dynamically provisioned on demand.






















































































