Downloaded 13 times





![How PHP Fits with My
SQLYou can use MySQL commands within PHP code.
Some of the more commonly used functions are:
◦ mysql_connect($host, $username, $password) : Connects to the
MySQL server and returns a resource which is used to reference the
connection.
◦ Mysql_pconnect():-
◦ mysql_select_db($database, $resource) : Equivalent to the MySQL
command USE and sets the active database.
◦ mysql_query($query, $resource) : Used to send any MySQL
command to the database server. In the case of SELECT queries, a
reference to the result set will be returned.
◦ mysql_fetch_array($result) : Return a row of data from the query ’
s result set as an associative array, numeric array or both.
◦ mysql_fetch_assoc($result) : Return a row of data from the query ’
s result set as an associative array.
◦ mysql_error([$resource]) : Shows the error message generated by
the previous query.
◦ die(<String> $msg)
die() prints message and exits the current script.](https://image.slidesharecdn.com/phplacture2-140707060718-phpapp02/85/Learn-PHP-Lacture2-6-320.jpg)




![Here is the "insert.php" page:
<?php
$con = mysql_connect('localhost', 'root', '') or
die ('Unable to connect. Check your connection
parameters.');
echo "Connection successfullyn";
// select database
mysql_select_db('student', $con) or die(mysql_error($con));
echo "Database activen";
//insert data
$sql="INSERT INTO Persons (FirstName, LastName, Age)
VALUES
('$_POST[firstname]','$_POST[lastname]','$_POST[age]')";
if (!mysql_query($sql,$con))
{
die('Error: ' . mysql_error());
}
echo "1 record added";
mysql_close($con);
?>](https://image.slidesharecdn.com/phplacture2-140707060718-phpapp02/85/Learn-PHP-Lacture2-11-320.jpg)
![Retrieve the Data From a Database
Table$result = mysql_query("select * from Persons ")
To retrive the data from the table we are using the
mysql_fetch_array() function.
When we pass $result into the mysql_fetch_array function --
mysql_fetch_array($result) -- an associative array (firstname,
lastname, age) is returned.
mysql_fetch_array() function to return the first row from the
recordset as an array.
In our MySQL table " Persons," there are only three fields that we
care about: firstname, lastname and age.
These names are the keys to extracting the data from our
associative array.
To get the firstname we use $row[‘firstname'] , to get the
lastname we use $row[‘lastnamr'] and to get the age we
use $row['age'].](https://image.slidesharecdn.com/phplacture2-140707060718-phpapp02/85/Learn-PHP-Lacture2-12-320.jpg)
![fetch array while
loopEach call to mysql_fetch_array() returns the next row
in the recordset.
$result = mysql_query("SELECT * FROM Persons");
while($row = mysql_fetch_array($result))
{
echo $row['FirstName'] . " " .
$row['LastName'].””.$row[‘age’];
echo "<br />";
}
The while loop loops through all the records in the
recordset.
To print the value of each row, we use the PHP $row
variable ($row['FirstName']
,$row['LastName'],$row[‘age’]).](https://image.slidesharecdn.com/phplacture2-140707060718-phpapp02/85/Learn-PHP-Lacture2-13-320.jpg)







![setcookie(name [,value [,expire [,path [,domain
[,secure]]]]])
name = cookie name
value = data to store (string)
expire = UNIX timestamp when the cookie expires.
Default is that cookie expires when browser is closed.
path = Path on the server within and below which the
cookie is available on.
domain = Domain at which the cookie is available for.
secure = If cookie should be sent over HTTPS
connection only. Default false.
Set a
cookie](https://image.slidesharecdn.com/phplacture2-140707060718-phpapp02/85/Learn-PHP-Lacture2-22-320.jpg)


![All cookie data is available through the
superglobal $_COOKIE:
$variable = $_COOKIE[‘cookie_name’]
or
$variable = $HTTP_COOKIE_VARS[‘cookie_name’];
e.g.
$age = $_COOKIE[‘age’]
Read cookie
data](https://image.slidesharecdn.com/phplacture2-140707060718-phpapp02/85/Learn-PHP-Lacture2-25-320.jpg)



![ $_SESSION
e.g., $_SESSION[“intVar”] = 10;
Testing if a session variable has been
set:
session_start();
if(!$_SESSION['intVar']) {...} //intVar is set or not
Session
variables](https://image.slidesharecdn.com/phplacture2-140707060718-phpapp02/85/Learn-PHP-Lacture2-29-320.jpg)
![Session
Example 1<?php
session_start();
if (!isset($_SESSION["intVar"]) ){
$_SESSION["intVar"] = 1;
} else {
$_SESSION["intVar"]++;
}
echo "<p>In this session you have accessed this
page " . $_SESSION["intVar"] . "times.</p>";
?>](https://image.slidesharecdn.com/phplacture2-140707060718-phpapp02/85/Learn-PHP-Lacture2-30-320.jpg)
![Ending
sessionsunset($_SESSION[‘name’])
–Remove a session variable
session_destroy()
– Destroys all data registered to a session
– does not unset session global variables and cookies
associated with the session
–Not normally done - leave to timeout](https://image.slidesharecdn.com/phplacture2-140707060718-phpapp02/85/Learn-PHP-Lacture2-31-320.jpg)

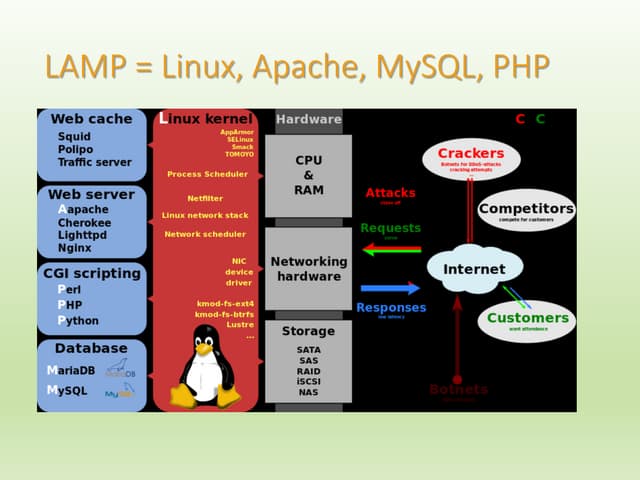
The document provides an overview of accessing and using MySQL with PHP. It discusses MySQL database structure and syntax, common MySQL commands, data types in MySQL, and how PHP fits with MySQL. It also covers topics like connecting to a MySQL database with PHP, creating and manipulating database tables, inserting and retrieving data, and maintaining state with cookies and sessions.