Download to read offline









![List of figures
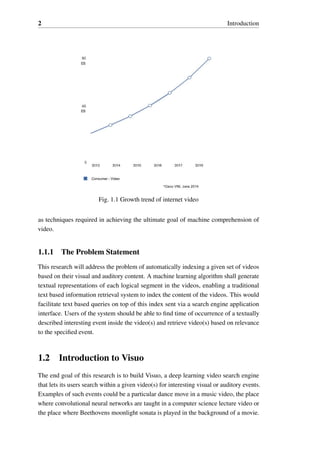
1.1 Growth trend of internet video . . . . . . . . . . . . . . . . . . . . . 2
2.1 Generic framework for visual content-based video indexing and re-
trieval. Image source [24] . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Hierarchical video representation. Image source [15] . . . . . . . . . 6
2.3 Alexnet CNN. Image source [30] . . . . . . . . . . . . . . . . . . . 13
2.4 Training DAEs. Image source [22] . . . . . . . . . . . . . . . . . . . 14
2.5 Spatio-temporal feature extraction using a 3D CNN. Multiple 3D convo-
lutions can be applied to contiguous frames to extract multiple features.
The sets of connections are color-coded so that the shared weights are
in the same color. Image source [26] . . . . . . . . . . . . . . . . . . 16
2.6 Spatio-temporal feature extraction using a multi stream CNN. Image
source [47] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.7 LRCN architecture which is a combination of CNNs for individual
frame processing and an LSTM RNN for sequence learning. Image
source [12] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.8 LSTM-YT architecture described in [54] which includes a mean pooling
layer between the CNNs and the LSTMs. Image source [54] . . . . . 19
3.1 Visuo Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . 23](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-9-320.jpg)





![Chapter 1
Introduction
1.1 The Significance of Understanding Video Content
According to statistics 100 hours of video are uploaded to YouTube.com every minute
while over 6 billion hours of video are watched each month on it [4]. With the general
availability of high quality video recording technology as well as the rapid adoption of
smartphone around the world, more and more users are creating and consuming video
content instead of more traditional forms of content such as text and images on the
internet. Video is the main form of storage of human knowledge at present with the
trend set to continue for even more video content creation in the future(Fig. 1.1).
Humans embrace video content because of brains capacity to process visual informa-
tion extremely fast [43]. But the computers which help transfer and consume this huge
amount of video data are mostly oblivious to the actual content they are transferring.
Though machine vision field has made rapid advances in recent years it still lags behind
when it comes to processing large amounts of video data to extract meaning when
compared to humans. As the second chapter of this report reveals traditional machine
vision techniques are mostly dependent on hand designed features and generally not
scalable enough to be applied to the problem of understanding video content. But the
benefits of machines being able to learn from the most comprehensive source of human
knowledge can be extensive. From automatic transcription for hearing or visually im-
paired to robot vision, from video search engines to automatic surveillance and internet
video content filtering, possibilities are enormous. Also understanding video content
might be a stepping stone for one of the ultimate goals of computing - Artificial General
Intelligence.
Our ambition in conducting this research is to put a step in the right direction in
machine comprehension of video content. Therefore it will focus on understanding
a video enough to be able to index it for a video search engine. Though this seems
somewhat simpler than the original problem of machine comprehension of video,
Solving the indexing problem may lead to better understanding of complexities as well](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-15-320.jpg)


![Chapter 2
Literature Survey
2.1 Content Based Video Retrieval
Content based video retrieval has attracted lots of interest among researchers because
of its importance in many applications of computer science. Videos are very dense
in information, a feature that makes content based video retrieval a hard research
problem, leaving a trail of research that spans more than two decades. Therefore this
section would be dedicated to covering conventional knowledge in video processing and
retrieval acquired over a long time that doesn’t involve DL approaches. According to
the in depth survey by Hu et al. on the subject [24] videos have following characteristics
1) much richer content than individual images; 2) huge amount of raw data; and 3) very
little prior structure. They further introduce a generic framework for visual content-
based video indexing and retrieval(Fig. 2.1) components of which is used to guide the
discussion on this section.
2.1.1 Structure Analysis
First step in the video processing pipeline is the structure analysis in which each video to
be indexed is logically segmented into manageable chunks. These chunks can be defined
as a hierarchy of structures namely video clips, scenes, shots and frames(Fig. 2.2). A
frame is the smallest unit of this hierarchy which represents a single still image in a
sequence that creates a shot, scene or a video clip. Shots are a sequence of frames
captured by a single camera within a single start and stop operation. They represent
a natural boundary from which the segmentation can begin. Scenes capture the most
semantic meaning in this hierarchy. A Scene is a sequence of semantically related and
temporally adjacent shots depicting a high-level concept or story [10].
Video segmentation using shot boundary detection is a heavily researched area in
video processing field as evidenced by [5, 24, 48, 49]. According to [24] shot boundary
detection involves three steps 1) feature extraction where several features useful for
shot boundary detection such as color histogram, edge change ratio, motion vectors,](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-19-320.jpg)
![6 Literature Survey
Fig. 2.1 Generic framework for visual content-based video indexing and retrieval. Image
source [24]
Fig. 2.2 Hierarchical video representation. Image source [15]](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-20-320.jpg)
![2.1 Content Based Video Retrieval 7
scale invariant feature transform, corner points, information saliency map could be
extracted. In step 2) similarity measurement - the extracted features are compared using
different measures such as 1-norm cosine dissimilarity, the Euclidean distance, the
histogram intersection, and the chi-squared similarity. In final step 3) detection - the
shot boundaries can be detected by utilizing two strategies. First is the threshold based
approach where similarity measurements are compared with a predefined threshold to
detect shots and the second is to use machine learning to identify shot boundaries using
aforementioned features as input vectors. A more recent treatment of shot detection
subject is [25] where the authors discuss shot detection under gradual transition as well
as using multiple features for detection.
Next the key frame extraction can be performed on segmented shots to extract
representative frames off the set of frames in the shot that would minimize error rate and
maximize compression ratio for the shot [24]. According to [24] available approaches to
key frame extraction can be classified in to six categories. In 1) sequential comparison-
based approach sequence of frames in a shot are compared with last extracted key frame
for the shot to extract the next key frame. In 2) global comparison-based approach
the key frames are extracted based on minimizing a global objective function for all
extracted key frames of the shot. In 3) reference frame-based approach a single reference
frame is generated for the given shot and all available shots for the frame are compared
with the reference frame. Key frames are extracted when the comparison method
reaches a certain threshold. In 4) clustering based approached all frames in shot are
clustered based on a clustering algorithm and frames closer to the centers of the clusters
are chosen as the key frames. In 5) curve simplification-based approach represent each
frame in a shot as a point in a feature space and try to find a set of points that best
describe the curve. In 6) object/event-based approach key frame extraction and object
event detection is combined together to find key frames that contain interesting objects
or events. A summary of advantages, disadvantages and implementations of all of these
key frame extraction approaches is provided in Table 2.1.
Generally once shot detection and key frame extraction is complete the next step in
structure analysis is the scene detection. Scene detection methods can be categorized
in to three approaches according to [24]. In 1) key frame based approach shots are
organized into scenes based on features extracted from key frames within temporally
close shots. More similar those key frames are more likely two shots are from the same
scene. In 2) audio and vision integration-based approach the shots are categorized into
scenes considering both visual and audio features. If in particular shot boundary both
audio and visual features change dramatically then the shot boundary is considered
as a scene boundary as well. This kind of scene segmentation approach is further
expanded upon by [15] where the authors categorize scene segmentation approaches
using features used such as visual-based, audio-based and text-based. In 3) Background-
based approach scenes are segmented based on detecting similar backgrounds in key](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-21-320.jpg)
![8 Literature Survey
frames. For a more recent look at scene segmentation subject as well as evaluation
strategies [15] serves as a good resource.
2.1.2 Feature Extraction
After structure analysis and various segmentation steps the generated segments needs
to be analyzed to extract various features in order to index a video. According to [24]
these features can be broadly classified into three categories. 1) Key frame features
which are static, 2) Object features and 3) motion features.
Key frame features can be further categorized into 1) color based features which
include color histograms, color moments, color correlograms, a mixture of Gaussian
models, etc. Extraction of these features depends on the application dependent color
space selection such as RGB, HSV, YCbCr etc. These can be used on entire images
or on parts of it and they are easy to extract in terms of computational complexity.
But they lack the capability to describe texture and shape of a key frame. [6] is an
example of a video search engine that uses color based features for indexing. 2) Texture
based features describe different surfaces of objects in a key frame. 3) Shape based
features describe shapes of different objects in key frame. Object features include the
dominant color, texture, size, etc., of the image regions corresponding to the objects.
For example the objects could be human faces. These are computationally expensive to
extract and largely limited to detecting several predefined object types such as faces
or humans. Motion features are features resulting from either camera movement or
object movement in a video. Object movement features can be further divided into
statistics-based, trajectory-based, and objects’ spatial relationships-based features.
A general observation that can be made about different categories of features
described based on [24] is that most of them are computationally expensive, hand
designed and mostly application/domain/object specific. When implementing a general
purpose video search engine those limitations may make it harder to scale because of
effort involved in extracting features. Therefore this survey do not go into much detail
about these traditional methods of feature extraction. A recent trend in machine learning
community is to automatically learn useful features instead of hand designing them [3].
Section 2.2 explores these novel approaches in feature extraction for video.](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-22-320.jpg)
![2.1 Content Based Video Retrieval 9
ApproachAdvantagesDisadvantagesMajorimplementations
Sequentialcomparison-basedsimplicity,intuitiveness,low
computationalcomplexity,adap-
tationofthenumberofkey
framestothelengthoftheshot
keyframesrepresentlocalproper-
tiesoftheshot,Theirregulardis-
tributionanduncontrollednum-
berofkeyframes,Redundancy
whensamecontentsareappear-
ingrepeatedlyinthesameshot
[36,58,60,61]
Globalcomparison-basedKeyframesreflecttheglobal
characteristicsoftheshot,Con-
trollablenumberofkeyframes,
Moreconciseandlessredundant
keyframes
computationallyexpensive[9,11,14,32,42]
Referenceframe-basedeasytounderstandandimple-
ment
dependenceonthereference
frame
[16,51]
Clustering-basedusegenericclusteringalgorithms,
globalcharacteristicsofashot
isreflectedintheextractedkey
frames
acquisitionofsemanticmeaning-
fulclustersisdifficult,sequential
natureoftheshotcannotbenatu-
rallyutilized
[17,18,59]
Curvesimplification-basedsequentialinformationiskepthighcomputationalcomplexity[8]
Object/event-basedextractedkeyframesaresemanti-
callyimportant
object/eventdetectionstrongly
reliesonheuristicrulesspecified
accordingtotheapplication
[29,34,35,50]
Table2.1Keyframeextractionapproaches-summary](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-23-320.jpg)
![10 Literature Survey
2.1.3 Learning from Video
The most important part of the video retrieval process is the automatic mining, classifica-
tion and annotation of the videos that are to be retrieved from based on user queries. All
of these tasks are heavily dependent on the earlier steps of structure analysis and feature
extraction. According to [24] Video mining refers to the process of automatically
identifying patterns in structure, objects and events in a video using machine learning
techniques. There are few strategies to go about mining videos. Object mining refers
to identifying the same object in different scenes, shots or key frames of a video. This
requires identifying objects under different visual transformations in different frames of
the video which is hard. A more recent development computer vision area, supervoxel
methods [57] allows efficient segmentation of video based on objects which makes
mining for objects easier. Other strategies for video mining include special pattern
detection such as human actions, pattern discovery, association mining between objects
or events and tendency mining.
Video classification refers to automatic categorization of videos based on their con-
tent. In [24] classification can be further categorized into edit effect classification, genre
classification, event classification, and object classification. Genre based classification
is particularly difficult because of the semantic gap between the low level feature of
the video and the semantic class it belongs to. To overcome this problem a rule based
or machine learning approach can be utilized. A recent convolutional neural network
based approach [28] achieved significant results over existing benchmarks for video
classification. Which hints at the ability of DL approaches to overcome semantic gap.
Video annotation is classification or labeling of individual segments of a video
into different semantic classes such as person, cat, walking, dancing etc. With different
features extracted during the feature extraction phase classifiers or detectors are trained
to detect each higher order semantic concept from the extracted features. A recent
study [27] on the subject explores the possibility of deploying different detectors at
different locations of video or segment to reduce computational cost.
2.1.4 Querying
According to [49] there are three main types of queries that a user can execute on a
content based video search engine. 1) Query by keyword is the most intuitive method
for human to interact with a search engine as it allows to express concepts with complex
semantics. But this is also the most difficult type of query to support because of the
semantic gap between the systems knowledge of the low level features and the user
query with complex semantics. Because of this reason most of the commercial video
search engines such as blinkx [2] support keyword type queries based on an index built
using audio transcribed text of videos. The newer methods which generate textual
representations of various objects, events and patterns in a video based on DL has](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-24-320.jpg)
![2.2 Deep Learning for Video 11
been proposed and will be covered in section 2.2. 2) Query by example technique
allows a user to submit a sample video, image or a sketch to the search engine which in
turn transforms the sample into a feature representation which it can compare with the
already built feature index. 3) In Query by concept paradigm the user is allowed to
select between predefined concepts already available to the search engine through its
index.
2.1.5 Semantic Gap
Human representations of certain concepts are generalized to a level where even with
ambiguous natural language descriptions of those concepts can convey meaning to
another human being. But when those concepts are transformed into a machine level
description the generic nature as well as the information content is lost most of the
time. In machine learning literature this is known as semantic gap [13]. For example
in [13] the authors try to address the problem of semantic richness of user queries
executed on simple feature(shape, color, patterns) based representations of multimedia
retrieval systems. Because the rich queries negatively affect the retrieval accuracy and
performance.
The recent resurgence in the field of neural networks and DL has provided computer
science a new path to explore in minimizing semantic gap [1]. The ability of deep neural
network architectures to automatically learn features instead of being hand crafted as
well as their ability to generalize has meant that now more and more of traditional
computer vision and machine learning benchmarks are being won by these kind of
algorithms instead of techniques such as SVMs [46]. Many neural network architec-
tures have been explored in research literature for different kinds of machine learning
problems from convolutional neural networks that learn higher order representations of
images to recurrent neural networks that detect complex patterns in temporally varying
data.
Next section explores this trend towards deep architectures in relation to video
retrieval space. Our intention is to explore novel ideas in video(multimedia) indexing
using deep neural network architectures.
2.2 Deep Learning for Video
This section explores scientific literature to understand DL techniques as well as their
application towards learning from video and indexing them. The subsection 2.2.1
surveys DL techniques in general to provide the necessary background as well as to
highlight the state of the field. Next the subsection 2.2.2 studies significant contributions
in recent research literature for the application of DL techniques to process and under-
stand video. Finally subsection 2.2.3 studies DL techniques which allow translation](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-25-320.jpg)
![12 Literature Survey
of visual/auditory representations to text as this is an important task for indexing in a
search engine.
2.2.1 A Brief Survey of Deep Learning Techniques
According to a recent survey by Schmidhuber [46] first inspirations of DL structures
span as far back as 1962 when Hubel et al investigated the visual cortex of cats explore
its cell structure. Then the most important milestone for learning in DNNs occurred
with the invention of back-propagation(BP) algorithm in [33]. But the term back-
propagation in the context of neural networks only gets coined in [44]. BP is a dynamic
programming solution where the weight of particular neuronal connection is updated
using the backward propagated error(difference between the expected and the obtained
output) using chain rule and error derivatives. The advantage of this technique is that
global contribution of a particular weight towards the error in output of the network can
be calculated with the use of local gradients. [44] also serves as an early example and
interpretation of representation learning or automatic feature learning in FNNs. Another
important technique a convolutional neural network(CNN) was trained using BP by
Lecun et al in [31] to achieve state of the art results in handwriting recognition for
postal zip codes back in 1989. Key features of a CNN are the weight sharing based
kernels and under sampling layers that help in optimal feature extraction. At the time of
writing CNNs trained using BP [30, 53] continues to dominate various image processing
benchmarks and competitions such as ImageNet classification competition which used
to be dominated by traditional pattern recognition techniques [45]. The trend was started
by Krizhevsky et al with a neural network now known as alexnet(Fig. 2.3), which has
60 million parameters and 500,000 neurons, consists of five convolutional layers, some
of which are followed by max-pooling layers, and two globally connected layers with a
final 1000-way softmax [30]. Important fact to note here is that this renaissance of DL
is actually inspired by the exponential improvement in parallel processing hardware i.e.
GPUs which has helped in achieving speedups of as much as 50 times when training a
large scale neural network [46]. GPUs provide excellent processing medium for DNNs
because of their extreme parallel processing capabilities as well as lower cost compared
to other high end alternatives.
Though FNNs has seen good results with limited set of tasks in the 1980s, it was
known that recurrent neural networks(RNN) had the most computational power
if trained properly with ability to model any kind of computation [46]. But deep
RNNs had problems in training using the two most common techniques to train them,
back-propagation through time(BPTT) and Real Time Recurrent Learning(RTRL). In
1991 fundamental problem with training deep RNNs, the problem of vanishing and
exploding gradients was observed according to [46]. The solution to this problem
was the invention of long short term memory(LSTM) [23] networks. LSTMs solve
the exploding or vanishing gradient problem by introducing the concept of a LSTM](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-26-320.jpg)
![2.2 Deep Learning for Video 13
Fig. 2.3 Alexnet CNN. Image source [30]
memory cell which is constructed using a combination of linear and multiplicative
units. It allows constant error propagation through what is called a constant error
carousal(CEC) within it. The memory cell also has an input gate which controls when a
signal is allowed to affect the internal state of the cell and an output gate which controls
which error signals are allowed to propagate within the cell. These gates allow a LSTM
cell to learn when to modify, pass on or forget a memory. LSTM based RNNs are good
at sequence modeling tasks which require the use of short term internal state. The first
remarkable results achieved with LSTMs are reported in [19] where an LSTM based
RNN trained on faster hardware of 2009 set the state of the art in connected handwriting
recognition overtaking existing HMM based approaches. They have also been utilized
in speech recognition and statistical machine translation tasks with some achieving
state of the art [52] performance. Use of LSTMs in language generative models will be
further discussed in sub section 2.2.3.
Two other techniques which are of interest in DL are Deep Belief Networks(DBN) [21]
and Deep Auto Encoders(DAE) [22]. DBNs are constructed by stacking layers of re-
stricted Boltzmann machines(RBM) to form a deep architecture. RBMs are a particular
form of energy based learning model where the learning corresponds to modifying its
energy function so that the functions shape has desirable properties. By training each
layer of RBM in a DBN using the efficient unsupervised training algorithm known
as contrastive divergence [20] the DBN can be initialized in a good neighborhood
before final supervised fine tuning of the whole network [21] starts. DAEs are stacks of
denoising autoencoders that help in constructing low dimensional representations of
input data. Because the training of DAEs heavily depends on good initial weights, [22]
suggests an initialization strategy based on layer-wise unsupervised pre-training of a
deep net of RBMs after which the layers of RBMs are unrolled to form a DAE(Fig. 2.4).
The DAE then can be fine tuned using BP for the desired task.
2.2.2 Deep Learning from Video
Although there has been previous attempts at using neural networks [39] to mine and
classify video, the first truly representation learning [7] DNN trained for video mining](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-27-320.jpg)
![14 Literature Survey
Fig. 2.4 Training DAEs. Image source [22]
we could find was presented by Mobahi et al in [38] referred to as the videoCNN. As
the name suggests videoCNN is a CNN trained to identify objects in images by first
pre-training it in a supervised manner on temporal coherence based objective. Temporal
coherence refers to the similarity between successive frames in a video. In videoCNN
the authors help the network learn pose invariant features by training it on pose varying
videos of the objects to be identified and forcing the representations of successive frames
to be closer together as the supervisory signal during training. Then the videoCNN
achieves good classification performance comparable to prevaili state of the art methods
such as SVM and VTU [56] which use hand designed features instead of learned deep
representations on COIL100 image dataset. Though this method extracts useful features
from video it still isn’t good example of mining objects or events in a given video as it
only uses video for training.
A more influential paper, multimodal deep learning [40] by Ngiam et al serves as
an excellent resource in explaining how to train models that learn good audio/visual
representations of video using deep learning. The authors train different models based
on DBN and DAE architectures for an audio/visual classification task using CUAVE [41]
and AVLetters [37] datasets. Here the audio for the datasets are processed into their
spectrograms with temporal derivatives, resulting in a 100 dimension vector with PCA
whitening. The video for the datasets were preprocessed to extract only the region-of-
interest (ROI) encompassing the mouth. Each mouth ROI was re-scaled to 60 × 80 pixels
and further reduced to 32 dimensions using PCA whitening. In the first phase of training,](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-28-320.jpg)
![2.2 Deep Learning for Video 15
separate RBMs are trained for separate audio, video and bimodel input of the set of
training videos. Then these are unrolled [22] to form three DAEs which reconstruct
original video and audio input given video only, audio only and both audio/video inputs.
Then the shared representation obtained in the DAE is used with a linear SVM classifier
to do the final classification of input video or audio. This setup results in excellent state
of the art performance for number/letter classification on the datasets using video/audio
where the network learns to make use of audio representation favorably in the video
classification task. The network learns to use shared representation to better classify
audio under noise as well. Though the training phase seems more complicated with
additional steps to extract ROI and do PCA whitening, this model proves that DL
based representations are far superior than using hand designed features for machine
understanding of multimedia.
As evidenced by [30, 53], at the time of writing CNNs are the dominating DL
technique for large scale image recognition tasks. The advantage of CNNs over con-
ventional image processing techniques such as SIFT as well as some of the other DL
techniques is that a single CNN can be trained to learn useful features from raw images
while also making classification judgments by itself at a scale of millions of param-
eters. This kind of end to end train-ability reduces the complexity of training while
increasing computational cost, which is advantages because computational power is
increasingly becoming a less expensive commodity. Therefore a lot of recent research
literature [12, 26, 28, 47] has been dedicated to the problem of extending CNNs to the
domain of video processing with the additional temporal dimension. According to our
own review results, the approaches taken for adapting CNNs for the temporal dimension
can be classified into three types.
1. In 3D convolution based approach the temporal dimension is handled in the
same way as the other dimensions of width and height of a frame(Fig. 2.5).
Convolution is performed on an extracted 3D feature map of a desired region
of the video using a 3D kernel. [26] presents a 3D CNN which is evaluated on
a task of human action recognition. Here the authors extract initial region of
interest using human detectors and generate multi channel 3D feature maps of
the extracted region. Then multiple layers of 3D convolution is performed on the
extracted feature maps separately using a 7x7x3 kernel with 2x2 sub-sampling
layers between the convolutional layers. The model achieves state of the art
performance on TRECVID dataset. The advantage of this approach seem to be
the way it naturally fits the 3 dimensional video data as a direct interpolation of
2D CNNs to the third dimension of video with very little modification to training
algorithm. However further study may be required to understand actual benefits
and practicality of this approach versus the other approaches available.](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-29-320.jpg)
![16 Literature Survey
Fig. 2.5 Spatio-temporal feature extraction using a 3D CNN. Multiple 3D convolutions
can be applied to contiguous frames to extract multiple features. The sets of connections
are color-coded so that the shared weights are in the same color. Image source [26]
2. In multi stream convolution based approach two or more separate CNNs are
trained to mutually or individually learn a representation for the temporal infor-
mation between frames of a video. For example in [28] Karpathy et al train two
networks of this type. In late fusion network there are two columns of CNNs
training on frames 15 frames apart from each other combined at the fully con-
nected layer. In slow fusion network there are multiple CNN columns training on
overlapping four frame areas in combined area 10 frames wide combined slowly
at several layers of the network which each upper layer having access to more
information in the temporal dimension than the layer below. The slow fusion
model works well on the UCF101 dataset with classification accuracy 65% as
well as on the sports1m dataset the authors have prepared with a classification
accuracy of 60.9%. In another example for multi stream convolution based ap-
proach in [47] Simonyan et al train two CNNs one to learn spatial features of each
single frame and another to learn temporal features between consecutive frames
using feature vectors obtained through optical flow technique(Fig. 2.6). The
learned representations are fused together using the average or an SVM classifier
to obtain final classification. SVM fusion model achieves state of the art on the
UCF101 dataset overtaking hand designed models as well as the aforementioned
slow fusion model.
3. In CNN+RNN based approach a CNN is used to obtain representations of indi-
vidual frames a task for which they are good at, while the temporal representation
for the sequence of frames is learned by a specialized sequence processing mod-](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-30-320.jpg)
![2.2 Deep Learning for Video 17
Fig. 2.6 Spatio-temporal feature extraction using a multi stream CNN. Image source
[47]
Fig. 2.7 LRCN architecture which is a combination of CNNs for individual frame
processing and an LSTM RNN for sequence learning. Image source [12]
ule - an RNN using the representations generated by the CNN. These have the
advantage of being deep in spatial dimension as well as the temporal dimension
compared to the previous two approaches which are limited only to a select win-
dow of frames at a time step. [12] presents an excellent example of this kind of
network named long-term recurrent convolutional networks(LRCN)(Fig. 2.7). It
achieves classification accuracy of 82.9% on UCF101. Besides being a classifier
this network is able to perform as a generative model of video descriptions as
well. Therefore LRCN architecture is further discussed in sub section 2.2.3.
Compared to DAE based architecture presented by Ngiam et al in [40] CNN based
techniques have the advantage of being able to extract, process and classify features
using the same DL network without requiring any other technique in the feature extrac-
tion phase or classification phase. CNNs are less complicated in training while also](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-31-320.jpg)
![18 Literature Survey
providing more accuracy in classification. Considering these merits we decided to base
the DL architecture of Visuo on CNNs. In the very dynamic DL field there may be
many other combinations of networks possible for use in DL from video. Our intention
was to present the state of the art in summary to be useful for developing a content
based video retrieval system.
2.2.3 Visual Representations to Text Translation
Another area of research that has experienced a resurgence because of deep learning
techniques is visual-auditory data to text transcription/translation. This area of research
is in part driven by its usefulness for supporting text queries on multimedia search
engines. Here we review two very recent inter-related breakthrough papers on the
subject that present a CNN+RNN based DL technique(LRCN) for visual/auditory
representations to text translation task.
As discussed in sub section 2.2 Donahue et al in [12] present their LRCN archi-
tecture which is a DL model in spatial using CNNs as well as temporal dimensions
using LSTM RNNs. They evaluate this architecture on three tasks activity recognition
in video, image description generation and video description generation for which they
use a CRF generator in place of a CNN. In a followup paper [54] published by the
same research group, they suggest and extension to the architecture used for the video
description generation task where the CRF generator in [12] is replaced by a set of
CNNs and a mean pooling layer. The CNNs are provided with a sample of frames
from the input video. Then mean pooling layer generates a fixed length one hot vector
representation of the entire video taking the mean of output of the second fully con-
nected layer of each CNN. This vector is then fed to the text generating LSTM net to get
the final video description text. The final architecture which they call LSTM-YT(Fig.
2.8) is trained using combinations of Flickr30k and COCO2014 image description
datasets or without them and fine tuned on the Microsoft Research Video Description
Corpus that contains thousands of clips of youtube videos with descriptions. The trained
network outperforms previous models based on BLEU and METEOR scores and human
evaluation, setting the state of the art.
Considering the DL merits of CNNs as well as the performance facts presented here
about LSTM-YT architecture, We are of the opinion that a LSTM-YT based architecture
would work well for the task of feature extraction and text generation phases of Visuo.](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-32-320.jpg)
![2.2 Deep Learning for Video 19
Fig. 2.8 LSTM-YT architecture described in [54] which includes a mean pooling layer
between the CNNs and the LSTMs. Image source [54]](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-33-320.jpg)


![22 Research Methodology
and development in a suitable key frame extraction technique. We also believe that
this would be one of the differentiating factors between our approach and the current
research in DL techniques for video processing. 2) Implement the integration between
CNN developed earlier and the video processing engine with key frame extraction to
complete VVCE.
3.1.3 Develop and Train the Visuo Video Description Generator
Another high complexity component of our research is the Visuo Video Description
Generator(VVDG). This component will be implemented on top of VVCE with two
modifications to its architecture. 1) Modify the VLSCNN to match the design presented
in Fig. 2.8. 2) Build, Integrate and train the additional LSTM based RNN(Visuo RNN)
required to complete the LSTM-YT architecture.
3.1.4 Develop the Visuo Video Indexing Engine With Query UI
Visuo Video Indexing Engine(VVIE) and Visuo Query UI(VQUI) should be simpler to
implement as there are plenty of open source indexing and query engines available to
index simplified text based representations of video produced by VVDG.
3.1.5 Large Scale Deployment of Visuo Video Indexing Engine With
Query UI
This should require some time and effort because of the complexities involved in
supporting a server runtime with automated indexing support and many number of
users at a time. A cloud computing environment would be ideal as it provides the most
flexibility.
3.1.6 Develop the Visuo Speech Recognition Engine
Developing Visuo Speech Recognition Engine(VSRE) should be easier given that there
are few good open source libraries available for speech recognition such as CMU
Sphinx [55]. This component should generate textual representation of the audio track
of the video to be indexed by Visuo.
3.1.7 Add Audio Indexing Support for the Visuo Video Indexing
Engine
After developing VSRE its textual representation of audio track of a given video can be
indexed by VVIE.](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-36-320.jpg)

![References
[1] (2013). Improving photo search: A step across the semantic gap. http:
//googleresearch.blogspot.com/2013/06/improving-photo-search-step-across.html.
Accessed: 2015-01-31.
[2] (2015). Blinkx multimedia search engine. http://www.blinkx.com/. Accessed:
2015-01-31.
[3] (2015). Stanford deep learning. http://deeplearning.stanford.edu/. Accessed:
2015-01-20.
[4] (2015). Youtube.com statistics. https://www.youtube.com/yt/press/en-GB/statistics.
html. Accessed: 2015-01-20.
[5] A, C. S., Telang, R. B., and G, A. S. (2014). A review on cooperative shot boundary
detection.
[6] Adcock, J., Girgensohn, A., Cooper, M., Liu, T., and Wilcox, L. (2004). FXPAL
Experiments for TRECVID 2004. In TREC Video Retrieval Evaluation.
[7] Bengio, Y., Courville, A., and Vincent, P. (2013). Representation learning: A review
and new perspectives. Pattern Analysis and Machine Intelligence, IEEE Transactions
on, 35(8):1798–1828.
[8] Calic, J. and Izuierdo, E. (2002). Efficient key-frame extraction and video analysis.
In International Conference on Information Technology: Coding and Computing,
2002. Proceedings, pages 28–33.
[9] Chang, H. S., Sull, S., and Lee, S. U. (1999). Efficient video indexing scheme
for content-based retrieval. IEEE Transactions on Circuits and Systems for Video
Technology, 9(8):1269–1279.
[10] Cour, T., Jordan, C., Miltsakaki, E., and Taskar, B. (2008). Movie/script: Align-
ment and parsing of video and text transcription. In Proceedings of the 10th European
Conference on Computer Vision: Part IV, ECCV ’08, pages 158–171, Berlin, Heidel-
berg. Springer-Verlag.
[11] Divakaran, A., Radhakrishnan, R., and Peker, K. (2002). Motion activity-based
extraction of key-frames from video shots. In 2002 International Conference on
Image Processing. 2002. Proceedings, volume 1, pages I–932–I–935 vol.1.
[12] Donahue, J., Hendricks, L. A., Guadarrama, S., Rohrbach, M., Venugopalan, S.,
Saenko, K., and Darrell, T. (2014). Long-term recurrent convolutional networks for
visual recognition and description. arXiv:1411.4389 [cs]. arXiv: 1411.4389.
[13] Dorai, C. and Venkatesh, S. (2003). Bridging the semantic gap with computational
media aesthetics. IEEE MultiMedia, 10(2):15–17.](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-39-320.jpg)
![26 References
[14] Ejaz, N., Tariq, T. B., and Baik, S. W. (2012). Adaptive key frame extraction for
video summarization using an aggregation mechanism. Journal of Visual Communi-
cation and Image Representation, 23(7):1031–1040.
[15] Fabro, M. D. and Böszörmenyi, L. (2013). State-of-the-art and future challenges
in video scene detection: a survey. Multimedia Systems, 19(5):427–454.
[16] Ferman, A. and Tekalp, A. (2003). Two-stage hierarchical video summary extrac-
tion to match low-level user browsing preferences. IEEE Transactions on Multimedia,
5(2):244–256.
[17] Gibson, D., Campbell, N., and Thomas, B. (2002). Visual abstraction of wildlife
footage using gaussian mixture models and the minimum description length criterion.
In Pattern Recognition, International Conference on, volume 2, page 20814, Los
Alamitos, CA, USA. IEEE Computer Society.
[18] Girgensohn, A. and Boreczky, J. (1999). Time-constrained keyframe selection
technique. In IEEE International Conference on Multimedia Computing and Systems,
1999, volume 1, pages 756–761 vol.1.
[19] Graves, A., Liwicki, M., Fernández, S., Bertolami, R., Bunke, H., and Schmid-
huber, J. (2009). A novel connectionist system for unconstrained handwriting
recognition. Pattern Analysis and Machine Intelligence, IEEE Transactions on,
31(5):855–868.
[20] Hinton, G. (2002). Training products of experts by minimizing contrastive diver-
gence. Neural computation, 14(8):1771–1800.
[21] Hinton, G., Osindero, S., and Teh, Y.-W. (2006). A fast learning algorithm for
deep belief nets. Neural computation, 18(7):1527–1554.
[22] Hinton, G. E. and Salakhutdinov, R. R. (2006). Reducing the dimensionality of
data with neural networks. Science, 313(5786):504–507.
[23] Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural
computation, 9(8):1735–1780.
[24] Hu, W., Xie, N., Li, L., Zeng, X., and Maybank, S. (2011). A survey on visual
Content-Based video indexing and retrieval. Systems, Man, and Cybernetics, Part C:
Applications and Reviews, IEEE Transactions on, 41(6):797–819.
[25] Huo, Y. (2014). Adaptive threshold video shot boundary detection algorithm
based on progressive bisection strategy. Journal of Information and Computational
Science, 11(2):391–403.
[26] Ji, S., Xu, W., Yang, M., and Yu, K. (2013). 3d convolutional neural networks
for human action recognition. Pattern Analysis and Machine Intelligence, IEEE
Transactions on, 35(1):221–231.
[27] Karasev, V., Ravichandran, A., and Soatto, S. (2014). Active frame, location,
and detector selection for automated and manual video annotation. In The IEEE
Conference on Computer Vision and Pattern Recognition (CVPR).
[28] Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., and Fei-Fei, L.
(2014). Large-scale video classification with convolutional neural networks. In The
IEEE Conference on Computer Vision and Pattern Recognition (CVPR).](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-40-320.jpg)
![References 27
[29] Kim, C. and Hwang, J.-N. (2001). Object-based video abstraction using cluster
analysis. In 2001 International Conference on Image Processing, 2001. Proceedings,
volume 2, pages 657–660 vol.2.
[30] Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Imagenet classifica-
tion with deep convolutional neural networks. In Advances in neural information
processing systems, pages 1097–1105.
[31] LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard,
W., and Jackel, L. D. (1989). Backpropagation applied to handwritten zip code
recognition. Neural computation, 1(4):541–551.
[32] Lee, H.-C. and Kim, S.-D. (2003). Iterative key frame selection in the rate-
constraint environment. Signal Processing: Image Communication, 18(1):1–15.
[33] Linnainmaa, S. (1976). Taylor expansion of the accumulated rounding error. BIT
Numerical Mathematics, 16(2):146–160.
[34] Liu, L. and Fan, G. (2005). Combined key-frame extraction and object-based video
segmentation. IEEE Transactions on Circuits and Systems for Video Technology,
15(7):869–884.
[35] Liu, T., Zhang, H.-J., and Qi, F. (2003). A novel video key-frame-extraction
algorithm based on perceived motion energy model. IEEE Transactions on Circuits
and Systems for Video Technology, 13(10):1006–1013.
[36] Luo, X., Xu, Q., Sbert, M., and Schoeffmann, K. (2014). F-divergences driven
video key frame extraction. In 2014 IEEE International Conference on Multimedia
and Expo (ICME), pages 1–6.
[37] Matthews, I., Cootes, T. F., Bangham, J. A., Cox, S., and Harvey, R. (2002). Ex-
traction of visual features for lipreading. Pattern Analysis and Machine Intelligence,
IEEE Transactions on, 24(2):198–213.
[38] Mobahi, H., Collobert, R., and Weston, J. (2009). Deep learning from temporal
coherence in video. In Proceedings of the 26th Annual International Conference on
Machine Learning, pages 737–744. ACM.
[39] Montagnuolo, M. and Messina, A. (2009). Parallel neural networks for multimodal
video genre classification. Multimedia Tools and Applications, 41(1):125–159.
[40] Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., and Ng, A. Y. (2011). Mul-
timodal deep learning. In Proceedings of the 28th International Conference on
Machine Learning (ICML-11), pages 689–696.
[41] Patterson, E. K., Gurbuz, S., Tufekci, Z., and Gowdy, J. (2002). Cuave: A new
audio-visual database for multimodal human-computer interface research. In Acous-
tics, Speech, and Signal Processing (ICASSP), 2002 IEEE International Conference
on, volume 2, pages II–2017. IEEE.
[42] Porter, S. V., Mirmehdi, M., and Thomas, B. T. (2003). A shortest path representa-
tion for video summarisation. In In Proceedings of the 12th International Conference
on Image Analysis and Processing, pages 460–465.
[43] Potter, M., Wyble, B., Hagmann, C., and McCourt, E. (2014). Detecting meaning
in rsvp at 13 ms per picture. Attention, Perception, Psychophysics, 76(2):270–279.](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-41-320.jpg)
![28 References
[44] Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1988). Learning representa-
tions by back-propagating errors. Cognitive modeling, 5.
[45] Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang,
Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., and Fei-Fei, L. (2014).
ImageNet Large Scale Visual Recognition Challenge.
[46] Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural
Networks, 61:85–117. arXiv: 1404.7828.
[47] Simonyan, K. and Zisserman, A. (2014). Two-stream convolutional networks for
action recognition in videos. In Advances in Neural Information Processing Systems,
pages 568–576.
[48] Singh, R. D. and Aggarwal, N. (2015). Novel research in the field of shot
boundary detection – a survey. In El-Alfy, E.-S. M., Thampi, S. M., Takagi, H.,
Piramuthu, S., and Hanne, T., editors, Advances in Intelligent Informatics, number
320 in Advances in Intelligent Systems and Computing, pages 457–469. Springer
International Publishing.
[49] Snoek, C. G. M. and Worring, M. (2009). Concept-based video retrieval. Found.
Trends Inf. Retr., 2(4):215–322.
[50] Song, X. and Fan, G. (2005). Joint key-frame extraction and object-based video
segmentation. In Seventh IEEE Workshops on Application of Computer Vision, 2005.
WACV/MOTIONS ’05 Volume 1, volume 2, pages 126–131.
[51] Sun, Z., Jia, K., and Chen, H. (2008). Video key frame extraction based on spatial-
temporal color distribution. In IIHMSP ’08 International Conference on Intelligent
Information Hiding and Multimedia Signal Processing, 2008, pages 196–199.
[52] Sutskever, I., Vinyals, O., and Le, Q. V. (2014). Sequence to sequence learning
with neural networks. In Advances in Neural Information Processing Systems, pages
3104–3112.
[53] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D.,
Vanhoucke, V., and Rabinovich, A. (2014). Going deeper with convolutions. CoRR,
abs/1409.4842.
[54] Venugopalan, S., Xu, H., Donahue, J., Rohrbach, M., Mooney, R., and Saenko, K.
(2014). Translating videos to natural language using deep recurrent neural networks.
arXiv:1412.4729 [cs]. arXiv: 1412.4729.
[55] Walker, W., Lamere, P., Kwok, P., Raj, B., Singh, R., Gouvea, E., Wolf, P.,
and Woelfel, J. (2004). Sphinx-4: A flexible open source framework for speech
recognition. Technical report, Mountain View, CA, USA.
[56] Wersing, H. and Körner, E. (2003). Learning optimized features for hierarchical
models of invariant object recognition. Neural computation, 15(7):1559–1588.
[57] Xu, C. and Corso, J. J. (2012). Evaluation of Super-Voxel Methods for Early Video
Processing.
[58] Xu, Q., Li, X., Yang, Z., Wang, J., Sbert, M., and Li, J. (2012). Key frame selection
based on jensen-r #x00e9;nyi divergence. In 2012 21st International Conference on
Pattern Recognition (ICPR), pages 1892–1895.](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-42-320.jpg)
![References 29
[59] Yu, X.-D., Wang, L., Tian, Q., and Xue, P. (2004). Multilevel video representation
with application to keyframe extraction. In Multimedia Modelling Conference, 2004.
Proceedings. 10th International, pages 117–123.
[60] Zhang, H. J., Wu, J., Zhong, D., and Smoliar, S. W. (1997). An integrated system
for content-based video retrieval and browsing. Pattern Recognition, 30(4):643–658.
[61] Zhang, X.-D., Liu, T.-Y., Lo, K.-T., and Feng, J. (2003). Dynamic selection and
effective compression of key frames for video abstraction. Pattern Recognition
Letters, 24(9–10):1523–1532.](https://image.slidesharecdn.com/833b5090-3774-4d65-aa60-34d72da284d6-160623163828/85/pgdip-project-report-final-148245F-43-320.jpg)


This document describes the development of Visuo, a deep learning video search engine. It begins with an introduction discussing the importance of machine understanding of video content as video becomes a primary form of storing human knowledge. It then provides an outline of the report and introduces Visuo as the goal of the research. The document contains sections on literature review of content-based video retrieval and deep learning techniques for video as well as the proposed research methodology and architecture for Visuo.












































