Download as PDF, PPTX



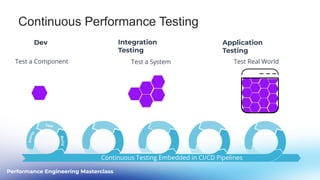
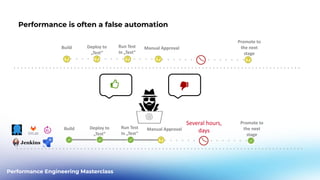




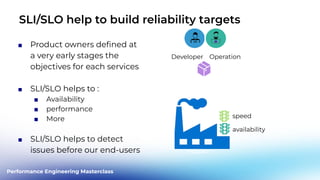

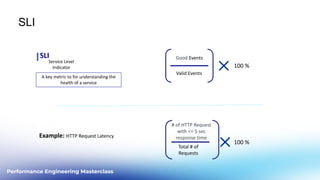

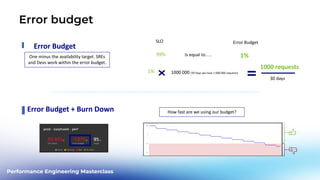
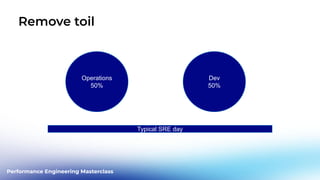


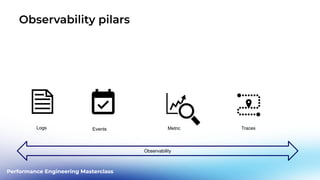




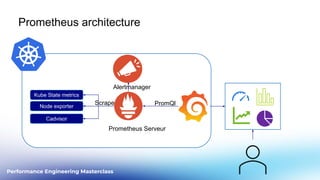





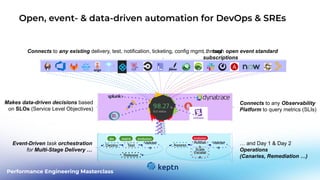


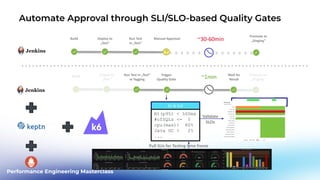
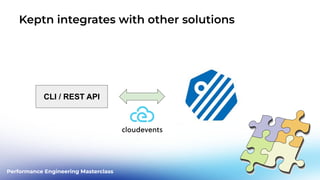

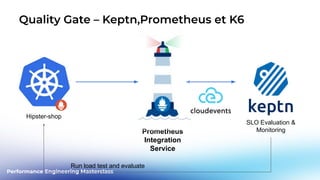


This document outlines a performance engineering masterclass led by Henrik Rexed, focusing on integrating Site Reliability Engineering (SRE) concepts to enhance automation and performance testing. Key topics include Service Level Indicators (SLIs) and Service Level Objectives (SLOs), observability, and using tools like Keptn for orchestrating SLO-driven automation in DevOps practices. The session aims to highlight the importance of measuring and improving service reliability while reducing manual errors through efficient CI/CD processes.












































![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)










































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)