The document discusses the "Data, Transformations, Resources" pattern in Terraform for organizing code. It introduces new data types and features in Terraform versions 12 and 13 for working with structured data. These include lists, maps, objects, and for expressions for mapping data into resources. The pattern advocates separating data collection and normalization, data transformations using the new functions, and defining each resource once to make the code understandable, easy to change, and efficient.





![list(string)
list(tuple[string,number,bool])
map(string)
map(object({ id=string, cidr_block=string }))
composition of data types](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-6-320.jpg)

![variable people {
type = list(object({ name=string, age=number }))
default = [
{
name = "John"
age = 32
}
]
}
type checking (continued)](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-8-320.jpg)
![~/Devel/devops-tools (rblumen) $ /opt/hashi/terraform-0.12.20
apply -var 'people=[ { name="Job", age=71 } ]'
Apply complete! Resources: 0 added, 0 changed, 0 destroyed.
~/Devel/devops-tools (rblumen) $ /opt/hashi/terraform-0.12.20
apply -var 'people=[ { name="Job", age=true } ]'
Error: Invalid value for input variable
The argument -var="people=..." does not contain a valid value for variable
"people": element 0: attribute "name": string required.](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-9-320.jpg)
![groups = [
{
"key" : "value"
},
{
"key-2": "value-2"
}
]
all_groups = merge(local.groups...)
###
{
"key": "value",
"key-2": "value"
}
python-style splatting](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-10-320.jpg)

![terraform 11 - indexed lists
resource providerX web_thing {
count = var.num_servers
name = element(var.server_names,count.index)
}
#####
web_thing[0]
web_thing[1]
web_thing[2]
web_thing[3]](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-12-320.jpg)
![locals {
server_names = [ "db", "front-end", "back-end" ]
}
terraform 12+ - maps
web_srv["db"]
web_srv["front-end"]
web_srv["back-end"]
resource providerY web_srv {
for_each = toset(var.server_names)
name = each.value
}](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-13-320.jpg)
![old - (count based):
aws_iam_policy.aws_admin_access[3]
new - (for_each):
aws_iam_policy.aws_admin_access["AmazonS3FullAccess"]
indexing](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-14-320.jpg)
![locals {
administrator_policies = [
"AmazonEC2FullAccess",
"AmazonS3FullAccess",
"AWSKeyManagementServicePowerUser",
"AWSLambdaFullAccess",
]
}
data aws_iam_policy aws_admin_access {
for_each = toset(local.administrator_policies)
arn = "arn:aws:iam::aws:policy/${each.value}"
}
for_each - iterating over a list](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-15-320.jpg)

![data aws_iam_policy_document access {
for_each = toset(local.groups)
statement {
effect = "Allow"
actions = ["s3:PutObject", ]
resources = data.aws_s3_bucket.devel.arn
}
}
chaining iteration
resource aws_iam_policy access {
for_each = data.aws_iam_policy_document.access
name = "${each.key}Access"
policy = each.value.json
}
resource aws_iam_group_policy_attachment group_access {
for_each = aws_iam_policy.access
group = each.key
policy_arn = each.value.arn
}](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-17-320.jpg)



![locals {
all_groups = toset([ "dev", "core", "admin", "ops", "chat" ])
some_groups = toset(["dev", "voice"])
other_groups = setsubtract(all_groups, some_groups) # in 12.21
}
resource aws_iam_group groups {
for_each = local.all_groups
name = each.value
}
resource aws_thing thing_one {
for_each = local.some_groups
group = aws_iam_group.groups[each.value]
}
resource aws_thing thing_two {
for_each = local.other_groups
group = aws_iam_group.groups[each.value]
}
implementing conditionals with sets](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-21-320.jpg)
![locals {
test_envs = [ "test1", "test2" ]
}
resource saas_thing_one test_only {
foreach = setintersection(toset([var.environment]), local.test_envs)
…
}
conditionals (2)](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-22-320.jpg)

![for expressions
users = [ "achman", "aziss", "bwong", "cshah", ]
# list
emails = [
for u in local.users : "${replace(u, "-", ".")}@pagerduty.com"
]
# map
emails_by_user = {
for u in local.users :
u => "${replace(u, "-", ".")}@pagerduty.com"
}](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-24-320.jpg)
![[for s in var.list :
upper(s)
if s != ""]
for expressions - conditionals](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-25-320.jpg)
![var user_email_assn {
type = map(string)
default = { ... }
}
local {
labels = [ for user, email in var.user_email_assn: "${user}:${email} ]
}
for expressions - map](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-26-320.jpg)
![{
for s in [ "abc", "def", "aef", "dps" ] :
substr(s, 0, 1) => s...
}
{
"a" = [
"abc",
"aef",
]
"d" = [
"def",
"dps",
]
}
for expressions - group by](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-27-320.jpg)




![locals {
on_call_teams = {
tier_1 = [ "abe", "jaxel", "beldon" ]
tier_2 = [ "abe", "janpax", "fanlo" ]
escalation = [ "adam", "shefty", "fanlo" ]
}
}
terraform solution](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-32-320.jpg)

![locals {
team_user_pairs = [
for team, users in local.on_call_teams: [
for for user in users: {
user: user
team: team
}
]
]
team_users = {
for pair in flatten(local.team_user_pairs):
"${pair.team}-${pair.user}" => {
team_id: pagerduty_team[pair.team].id,
user_id: pagerduty_user[pair.user].id
}
}
}
resource pagerduty_team_membership membership {
for_each = local.team_users
team_id = each.value.team_id
user_id = each.value.user_id
}](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-34-320.jpg)
![locals {
on_call_teams = {
tier_1 = [ "abe", "jaxel", "beldon" ]
tier_2 = [ "abe", "janpax", "fanlo" ]
escalation = [ "adam", "shefty", "fanlo" ]
}
}
###
resource saas_team_membership membership {
for_each = ??
user = each.key
groups = each.value
}
one:many inverting](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-35-320.jpg)
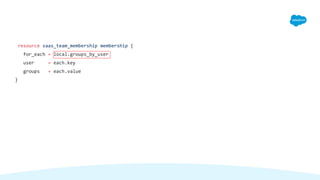
![user_group_pairs = flatten([
for group, members in local.group_memberships : [
for user in members : {
user = user
group = group
}
]
])
groups_by_user = {
for pair in local.user_group_pairs :
pair.user => pair.group...
}
}](https://image.slidesharecdn.com/hashi2021talkv2blumen-210218051123/85/Patterns-in-Terraform-12-13-Data-Transformations-and-Resources-36-320.jpg)