Image Classification
• Automaticallycategorize all pixels in an image
into land use/cover classes or themes.
• A process of thematic information extraction
• A process of pattern recognition
• process of arranging raw data DNs into
information classes.
Image classification
• Imageclassification refers to a process in computer vision
that can classify an image according to its visual content.
• For example, an image classification algorithm may be
designed to tell if an image contains a human face or not.
• While detecting an object is trivial for humans, robust
image classification is still a challenge in computer vision
applications.
• Image classification is the process of assigning land cover
classes to pixels. For example, classes include water,
urban, forest, agriculture and grassland.
Concept of Classification
•Image classification is a process of mapping
numbers to
• symbols
• f(x): x D; x R
∈ n, D = {c1, c2, …, cL}
• Number of bands = n;
• Number of classes = L
• f(.) is a function assigning a pixel vector x to
• a single class in the set of classes D
Image classification
• Imageclassification refers to the task of
extracting information classes from a multiband
raster image.
• The resulting raster from image classification
can be used to create thematic maps.
• Depending on the interaction between the
analyst and the computer during classification,
there are two types of classification: supervised
and unsupervised.
20.
Image classification
• Imageclassification is assigning pixels in the
image to categories or classes of interest .
• The pixels of the digital image are taken and
grouped into what we know as “classes.”
• Examples: builtup areas, water body, green
vegetation, bare soil, rocky areas, cloud, shadow
etc. in order to classify a set of data into different
classes or categories.
Image classification
• Therelationship between the data and the
classes into which they are classified must be well
understood.
• To achieve this by computer, the computer must
be
• (i) trained –
• (ii) Classification techniques were originally
developed
• (iii) Pattern Recognition
23.
Image classification
• Computerclassification of remotely sensed images
involves the process of the computer program
learning (training) the relationship between the data
and the information classes.
• Image classification is a procedure to automatically
categorize all pixels in an Image of a terrain into land
cover classes.
• Normally, multispectral data are used to Perform the
classification of the spectral pattern present within
the data for each pixel and is used as the numerical
basis for categorization- Pattern Recognition .
24.
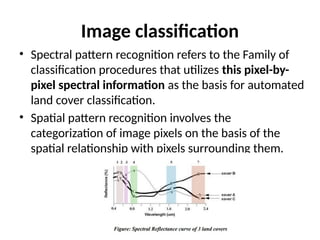
Image classification
• Spectralpattern recognition refers to the Family of
classification procedures that utilizes this pixel-by-
pixel spectral information as the basis for automated
land cover classification.
• Spatial pattern recognition involves the
categorization of image pixels on the basis of the
spatial relationship with pixels surrounding them.
25.
Types of imageclassification
•
Binary: Binary classification takes an either-or logic to label
images, and classifies unknown data points into two
categories.
• When your task is to categorize benign or malignant tumors,
analyze product quality to find out whether it has defects or
not, and many other problems that require yes/no answers are
solved with binary classification.
• Multiclass: While binary classification is used to distinguish
between two classes of objects, multiclass, as the name
suggests, categorizes items into three or more classes.
• It's very useful in many domains like NLP (sentiment analysis
where more than two emotions are present), medical
diagnosis(classifying diseases into different categories), etc.
26.
Types of imageclassification
• Multilabel: Unlike multiclass classification,
where each image is assigned to exactly one
class, multilabel classification allows the item
to be assigned to multiple labels.
• For example, you may need to classify image
colors and there are several colors.
• A picture of a fruit salad will have red, orange,
yellow, purple, and other colors depending on
your creativity with fruit salads. As a result,
one image will have multiple colors as labels.
27.
Types of imageclassification
• Hierarchical: Hierarchical classification is the
task of organizing classes into a hierarchical
structure based on their similarities, where a
higher-level class represents broader
categories and a lower-level class is more
concrete and specific. Let's get back to our
fruits and understand the concept based on a
juicy example.
29.
Steps in ImageClassification
Image captured by Digital Camera
Improvement of Image Data
30.
Steps in ImageClassification
Image captured by Digital Camera
Improvement of Image Data
Calculating / Detecting the features from the image samples
31.
Steps in ImageClassification
Image captured by Digital Camera
Improvement of Image Data
Calculating / Detecting the features from the image samples
Selection of the particular attribute - best describes
the pattern
32.
Steps in ImageClassification
Image captured by Digital Camera
Improvement of Image Data
Calculating / Detecting the features from the image samples
Selection of the particular attribute - best describes
the pattern
Categorizes detected objects into predefined classes by using
suitable method that compares the image patterns with the
target patterns
33.
Steps in ImageClassification
Image captured by Digital Camera
Improvement of Image Data
Calculating / Detecting the features from the image samples
Selection of the particular attribute - best describes
the pattern
Categorizes detected objects into predefined classes by using
suitable method that compares the image patterns with the
target patterns
34.
Steps in ImageClassification
• Step 1: Definition of Classification Classes
• Depending on the objective and the characteristics of the
image data, the classification classes should be clearly defined.
• Fruits , animals
• Step 2: Selection of Features to discriminate between the
classes should be established using multispectral or multi-
temporal characteristics, colour, textures etc.
• Step 3: Sampling of Training Data Training data should be
sampled in order to determine appropriate decision rules.
• Classification techniques such as supervised or unsupervised
learning will then be selected on the basis of the training data
sets.
35.
Steps in ImageClassification
• Step 4: Finding of proper decision rule Various
classification techniques will be compared with the
training data, so that an appropriate decision rule is
selected for subsequent classification.
• Step 5: Classification depending upon the decision rule,
all pixels are classified in a single class.
• There are two methods of pixel by pixel classification and
per-field classification, with respect to segmented areas.
• Step 6: Verification of Results The classified results
should be checked and verified for their accuracy and
reliability
36.
How image classificationworks
• The image is made up of hundreds to thousands of tiny pixels.
• Before computer vision can determine and label the image as
a whole, it needs to analyze the individual components of the
image to make an educated assumption.
• Image classification techniques analyze a given image in the
form of pixels and accomplish this by treating the picture as
an array of matrices, the size of which is determined by the
image resolution.
• The pixels of the digital image are taken and grouped into
what we know as “classes.”
• The chosen algorithm will transform the image into a series of
key attributes and those attributes help the classifier
determine what the image is about and which class it belongs
to.
37.
Steps of ImageClassification – Image
Preprocessing
• Image pre-processing -> feature extraction -> object classification
• Image pre-processing
• Image resizing: Image resizing is changing the image's dimensions(width and
height) to make them computationally less complex for further processing.
• Image cropping: Whenever there are irrelevant or unnecessary parts in an
image that may affect the model performance (such as background or
borders) it's better to crop the image and leave only the needed parts.
• Image normalization: Image normalization is used to adjust image pixel
values to a standard distribution , rescaling pixel values to a fixed range, or
using histogram equalization techniques to adjust the image parameters(like
brightness or contrast) to make it more suitable for analysis.
• Noise reduction: Noise can affect model accuracy and performance. This
requires image filtering techniques like Gaussian filtering, median filtering, or
Weiner filtering to improve image quality.
• Data augmentation: Data augmentation is the process of creating new
variations of the images by creating image transformations, such as rotation,
zooming, flipping, and changing the brightness and contrast.
38.
Steps of ImageClassification -Feature
Extraction
• Features are attributes of the data elements
based on which the elements are assigned to
various classes.
• E.g., in satellite remote sensing, the features
are measurements made by sensors in
different wavelengths of the electromagnetic
spectrum – visible/ infrared / microwave …
39.
Steps of ImageClassification -Feature
Extraction
• In medical diagnosis, the features may be the
temperature, blood pressure, lipid profile,
blood sugar, and a variety of other data
collected through pathological investigations
• The features may be qualitative (high,
moderate, low) or quantitative.
• The classification may be presence of heart
disease (positive) or absence of heart disease
(negative)
40.
Steps of ImageClassification -Feature
Extraction
• Feature extraction
• Feature extraction is a substantial process in image classification for
identifying visual patterns within an image that will be used to
distinguish one object from another.
• The patterns are typically exclusive to the specific class of images
which results in distinct class differentiation.
• Once the computer has learned these important image features and
recognizes them in the training data, it can use them to classify new
images that it has never seen before.
• Ex : In the case of classifying dog and cat pictures, there are some
patterns that can be used as features to differentiate the two classes,
like fur texture and color, ear shape and position, nose/eye shape
and color, and body shape and size.
• This procedure of learning the features from the dataset is called
model training, which plays a crucial role in image analysis.
41.
Steps of ImageClassification
• Edge detection refers to spotting boundaries
between regions in an image, which is then
used to acquire information about objects'
shape and structure.
• There are several edge detection methods like
derivation, gradient operators, and several
more advanced techniques.
42.
Steps of ImageClassification
• Texture analysis is the procedure of finding
repeating patterns within an image, which can be
used to identify the presence of texture and
distinguish between different materials or surfaces
of objects.
• A famous practical application of texture analysis is
identifying tumors in medical imaging -- the texture
of cancerous tissue may differ from that of healthy
tissue, assisting doctors in diagnosing tumor type.
43.
Algorithm for ImageClassification
• The learning algorithms for classification are
broadly classified into
–supervised and unsupervised
learning techniques.
• The distinction is drawn from how the learner
classifies data.
44.
Supervised & UnsupervisedLearning
• Supervised Learning
• Learning process designed to form a mapping from
one set of variables (data) to another set of
variables (information classes).
• A teacher is involved in the learning process
• Unsupervised learning
• Learning happens without a teacher
• Exploration of the data space to discover the
scientifc laws underlying the data distribution
45.
Supervised Classification
• Theclassifier has the advantage of an analyst or domain
knowledge using which the classifier can be guided to learn
the relationship between the data and the classes.
• The number of classes, prototype pixels for each class can be
identified using this prior knowledge.
• The image analyst “supervises’ the pixel categorization process
specifying, to the computer algorithm, numerical descriptors
of the various land cover types present in a scene.
• Representative sample sets of known data type, called
training areas, are used to compile a numerical
“interpretation key” that describes the spectral attributes for
feature type of interest.
46.
Partially Supervised Classification
•When prior knowledge is available for some
classes, and not for others in a multi temporal
dataset
• Combination of supervised and unsupervised
methods can be employed for partially
supervised classification of images
47.
Unsupervised Classification
• Whenaccess to domain knowledge or the
experience of an analyst is missing, the data
can still be analyzed by numerical exploration,
whereby
• the data are grouped into subsets or clusters
based on statistical similarity.
• The analyst then labels and combines the
spectral clusters into information classes.
Supervised learning
• Supervisedlearning is famous for its self-explanatory name - it
is like a teacher guiding a student through a learning process.
• The algorithm is trained on a labeled image dataset, where
the mapping between inputs and correct outputs is already
known and the images are assigned to their corresponding
classes.
• The algorithm is the student, learning from the teacher (the
labeled dataset) to make predictions on new, unlabeled test
data.
• After the supervision phase is completed, the algorithm refers
to the trained data and draws similarities between that data
and the new input.
• Since it has already learned from the labeled data, it can
implement the knowledge gained from patterns of that data
and predict the classes of the new images based on that.
Supervised Classification
• Example:
•Let’s say you have a fruit basket that you want to identify.
• The machine would first analyze the image to extract features such as
its shape, color, and texture. Then, it would compare these features to
the features of the fruits it has already learned about.
• If the new image’s features are most similar to those of an apple, the
machine would predict that the fruit is an apple.
• For instance, suppose you are given a basket filled with different kinds
of fruits. Now the first step is to train the machine with all the different
fruits one by one like this:
• If the shape of the object is rounded and has a depression at the top, is
red in color, then it will be labeled as –Apple.
• If the shape of the object is a long curving cylinder having Green-Yellow
color, then it will be labeled as –Banana.
52.
Supervised Classification
• Nowsuppose after training the data, you have given a new
separate fruit, say Banana from the basket, and asked to
identify it.
• Since the machine has already learned the things from
previous data and this time has to use it wisely.
• It will first classify the fruit with its shape and color and
would confirm the fruit name as BANANA and put it in the
Banana category.
• Thus the machine learns the things from training
data(basket containing fruits) and then applies the
knowledge to test data(new fruit).
53.
Supervised Classification
• Supervisedalgorithms can be divided into single-label
classification and multi-label classification.
• As the name suggests, single-label classification refers
to a singular label that is assigned to an image as a
result of the classification process.
• If single-label classification generalized the image and
assigned it a single class, then the number of classes an
image can be assigned with multi-label classification is
uncountable.
• In the field of medicine, for example, medical imaging
may show several diseases or anomalies present in a
single image for the patient.
Supervised Classification- Steps
Supervisedclassification is based on the idea
that a user can select sample pixels in an image
that are representative of specific classes and
then direct the image processing software to use
these training sites as references for the
classification of all other pixels in the image.
Training sites (also known as testing sets or input
classes) are selected based on the knowledge of
the user.
The user also sets the bounds for how similar
other pixels must be to group them together.
These bounds are often set based on the
spectral characteristics of the training area, plus
or minus a certain increment (often based on
“brightness” or strength of reflection in specific
spectral bands).
56.
Supervised Classification- Steps
•The user also designates the number of classes that the image is
classified into.
• Many analysts use a combination of supervised and unsupervised
classification processes to develop final output analysis and classified
maps.
• In supervised classification the user or image analyst “supervises”
the pixel classification process.
• The user specifies the various pixels values or spectral signatures
that should be associated with each class.
• This is done by selecting representative sample sites of a known
cover type called Training Sites or Areas.
• The computer algorithm then uses the spectral signatures from
these training areas to classify the whole image.
• Ideally, the classes should not overlap or should only minimally
overlap with other classes.
Supervised Classification- Algorithm
•There are many techniques for assigning pixels to informational
classes
e.g.:
• Minimum Distance from Mean (MDM)
• Parallel piped
• Maximum Likelihood (ML)
• Support Vector Machines (SVM)
• Artificial Neural Networks (ANN)
• k-nearest neighbors
• decision trees
• Iso cluster
• linear and logistic regressions.
59.
Supervised Classification- Algorithm
•The classifier learns the characteristics of
different thematic classes – forest, marshy
vegetation, agricultural land, turbid water, clear
water, open soils,manmade objects, desert etc.
• This happens by means of analyzing the statistics
of small sets of pixels in each class that are
reliably selected by a human analyst through
experience or with the help of a map of the area.
60.
Supervised Classification- Algorithm
•Typical characteristics of classes
1. Mean vector
2. Covariance matrix
3. Minimum and maximum gray levels within each
band
4. Conditional probability density function p(Ci|x)
where Ci is the ith class and x is the feature vector
• Number of classes L into which the image is to be
classified should be specified by the user
61.
Parallelepiped Classifier -Example of a
Supervised Classifier
• Assign ranges of values for each class in each band
• Really a “feature space” classifier
• Training data provide bounds for each feature for each Class
• Results in bounding boxes for each class
• A pixel is assigned to a class only if its feature vector falls within the
corresponding box
62.
Supervised learning
• ParallelepipedClassification
• The parallelepiped classifier uses the class limits and stored in each
class signature to determine if a given pixel falls within the class or
not.
• The class limits specify the dimensions (in standard deviation units)
of each side of a parallelepiped surrounding the mean of the class in
feature space.
• If the pixel falls inside the parallelepiped, it is assigned to the class.
However, if the pixel falls within more than one class, it is put in the
overlap class (code 255). If the pixel does not fall inside any class, it is
assigned to the null class (code 0).
• The parallelepiped classifier is typically used when speed is required.
• The drawback is (in many cases) poor accuracy and a large number
of pixels classified as ties (or overlap, class 255).
63.
Parallelepiped Classifier
Using thetraining data for
each class the limits of the
parallelepiped subspace can
be defined either by the
minimum and maximum pixel
values in the given class, or by
a certain number of standard
deviations on either side of
the mean of the training data
for the given class.
The pixels lying inside the
parallelepipeds are tagged to
this class.
64.
Supervised learning
• Parallelepipedclassification, sometimes also known as
box decision rule, or level-slice procedures, are based
on the ranges of values within the training data to
define regions within a multidimensional data space.
• The spectral values of unclassified pixels are projected
into data space; those that fall within the regions
defined by the training data are assigned to the
appropriate categories.
• In this method a parallelepiped-like (i.e., hyper-
rectangle) subspace is defined for each class.
65.
Advantages/Disadvantages of
Parallelpiped Classifier
•Does NOT assign every pixel to a class. Only
the pixels that fall within ranges.
• Fastest method computationally
• Good for helping decide if you need additional
classes (if there are many unclassified pixels)
• Problems when class ranges overlap—must
develop rules to deal with overlap areas.
66.
Supervised learning
Minimum Distance
•Minimum Distance Classification for supervised classification,
these groups are formed by values of pixels within the training
fields defined by the analyst.
• Each cluster can be represented by its centroid, often defined as
its mean value.
• As unassigned pixels are considered for assignment to one of the
several classes, the multidimensional distance to each cluster
centroid is calculated, and the pixel is then assigned to the
closest cluster.
• Thus the classification proceeds by always using the “minimum
distance” from a given pixel to a cluster centroid defined by the
training data as the spectral manifestation of an informational
class.
67.
Minimum Distance Classifier
•Simplest kind of supervised classification
Steps:
1. Calculate the mean vector for each class
2. Calculate the statistical (Euclidean) distance
from each pixel to class mean vector
3. Assign each pixel to the class it is closest to
68.
Minimum Distance Classifier
•Algorithm
• Normally classifies every pixel no matter how far it is from a class mean (still
picks closest class) unless the T min condition is applied
• Distance between X and mi can be computed in different ways – Euclidean,
Mahalanobis, city block
Supervised classifier
• Logisticregression: Logistic regression is actually a
binary classification task, and is used in image
classification to predict whether an image belongs to
a certain category or not.
• It constructs a logistic function to model the
relationship between input features and class
probabilities.
• The final predictions are made by assigning a
probability value to each input, which is then
thresholded to make the final binary classification
decision.
Supervised learning
• Knearest neighbors:
• KNN is referred to as a
"lazy learner" because it
does not train itself when
given training data;
instead, it memorizes the
entire dataset, leading to
longer prediction times
and increased
computational complexity
when new data points are
encountered.
74.
K nearest neighbors
•For a pixel to be classified, find the K closest training samples (in
terms of feature vector similarity or smallest feature vector
distance)
• Among the K samples, find the most frequently occurring class Cm
• Assign the pixel to class Cm
• Let ki be number of samples for class Ci (out of K closest samples),
i=1,2,…,L (number of classes)
• Note that
• The discriminant for K-NN classifier is gi(x) = ki
The classifier rule is
• Assign x to class Cm if gm(x) > gi(x), for all i, i≠m
75.
Nearest-Neighbor Classifier
• Non-parametricin nature
The algorithm is:
• Find the distance of given feature
vector x from ALL the training samples
• x is assigned to the class of the
nearest training sample (in the
feature space)
• This method does not depend on the
class statistics like mean and
covariance.
76.
Supervised learning
• Supportvector machines:
• In simple terms, support vector machine separates
classes by a line or a boundary (called hyperplane).
• They use hyperplanes to maximally separate data
points of one class from another; i.e, maximize the
distance between the hyperplane and the closest
data points of each class.
77.
Supervised learning –SVM
• If we're trying to classify image as either "cat" or
"dog" , support vector machine would come up
with a line that separates these two.
• To do this, SVM takes the features of each
image(like color, texture, shape of image) and tries
to find the best hyperplane that separates the two
classes of images with the largest possible margin
(i.e. as we said, the distance between the
hyperplane and the closest data points).
78.
Supervised learning –Decision Tree
• Decision trees: Decision tree is another easily interpretable
technique widely used in image classification.
• It's like a flowchart that your model creates to make decisions
based on the features of the data.
• Imagine you're trying to guess which fruit someone is thinking
of, but you can only ask yes or no questions about its features.
• You start with a broad question like "Is it round?", and then
narrow it down with more specific questions like "Is it red or
green?" or "Is it sweet or sour" until you've guessed the fruit.
• Decision trees work the same way - they ask questions about
the features of the data until they can make a prediction.
UnSupervised learning
• Unsupervisedlearning is a type of machine learning that
learns from unlabeled data. This means that the data does
not have any pre-existing labels or categories.
• The goal of unsupervised learning is to discover patterns
and relationships in the data without any explicit guidance.
• Unsupervised learning is the training of a machine using
information that is neither classified nor labeled and
allowing the algorithm to act on that information without
guidance.
• Here the task of the machine is to group unsorted
information according to similarities, patterns, and
differences without any prior training of data.
81.
UnSupervised learning
• Unlikesupervised learning, no teacher is provided that
means no training will be given to the machine. Therefore
the machine is restricted to find the hidden structure in
unlabeled data by itself.
• You can use unsupervised learning to examine the animal
data that has been gathered and distinguish between
several groups according to the traits and actions of the
animals.
• These groupings might correspond to various animal
species, providing you to categorize the creatures without
depending on labels that already exist.
83.
Unsupervised learning
• Thebasic task of unsupervised learning is to develop
classification labels automatically.
• Unsupervised algorithms seek out similarity between pieces
of data in order to determine whether that can be
characterized as forming a group. These groups are termed
clusters.
• Unsupervised classification, often called as clustering, the
system is not informed how the pixels are grouped.
• The task of clustering is to arrive at some grouping of the data.
• One of the very common of cluster analysis is K-means
clustering.
84.
Unsupervised learning
Key Points
•Unsupervised learning allows the model to discover patterns and relationships in
unlabeled data.
• Clustering algorithms group similar data points together based on their inherent
characteristics.
• Feature extraction captures essential information from the data, enabling the
model to make meaningful distinctions.
• Label association assigns categories to the clusters based on the extracted
patterns and characteristics.
85.
Unsupervised learning
• Example
•Imagine you have a machine learning model trained on a large dataset of
unlabeled images, containing both dogs and cats. The model has never
seen an image of a dog or cat before, and it has no pre-existing labels or
categories for these animals. Your task is to use unsupervised learning to
identify the dogs and cats in a new, unseen image.
• Thus the machine has no idea about the features of dogs and cats so we
can’t categorize it as ‘dogs and cats ‘. But it can categorize them according
to their similarities, patterns, and differences, i.e., we can easily categorize
the above picture into two parts.
• The first may contain all pics having dogs in them and the second part may
contain all pics having cats in them. Here you didn’t learn anything before,
which means no training data or examples.
• It allows the model to work on its own to discover patterns and information
that was previously undetected. It mainly deals with unlabelled data.
86.
Types of UnsupervisedLearning
• Unsupervised learning is classified into two
categories of algorithms:
• Clustering: A clustering problem is where you want
to discover the inherent groupings in the data, such
as grouping customers by purchasing behavior.
• Association: An association rule learning problem is
where you want to discover rules that describe
large portions of your data, such as people that buy
X also tend to buy Y.
87.
Unsupervised Classifier
Clustering Types:-
•Hierarchical clustering
• K-means clustering
• Principal Component Analysis
• Singular Value Decomposition
• Independent Component Analysis
• Gaussian Mixture Models (GMMs)
• Density-Based Spatial Clustering of Applications with
Noise (DBSCAN)
88.
Unsupervised Classifier
• Clustering
•Clustering is a type of unsupervised learning
that is used to group similar data points
together.
• Clustering algorithms work by iteratively
moving data points closer to their cluster
centers and further away from data points in
other clusters.
89.
Unsupervised Classifier
• K-means(unsupervised)
• A set number of cluster centers are positioned
randomly through the spectral space.
• Pixels are assigned to their nearest cluster.
• The mean location is re-calculated for each cluster.
• Repeat 2 and 3 until movement of cluster centres
is below threshold.
• Assign class types to spectral clusters.
Unsupervised Classifier
• Associationrule learning
• Association rule learning is a type of unsupervised
learning that is used to identify patterns in a data.
• Association rule learning algorithms work by finding
relationships between different items in a dataset.
• Some common association rule learning algorithms
include:
• Apriori Algorithm
• Eclat Algorithm
• FP-Growth Algorithm
92.
Chain Method
• Operatesin two pass mode ( it passes through the registered
multispectral dataset two times).
• In the first pass, the program reads through the dataset and
sequentially builds clusters.
• A mean vector is associated with each cluster.
• In the second pass, a minimum distance to means classification
algorithm is applied to whole dataset on a pixel by pixel basis
whereby each pixel is assigned to one of the mean vectors
created in pass 1.
• The first pass automatically creates the cluster signatures to be
used by supervised classifier.
94.
Variance • TheVariance is defined as: • The average of
the squared differences from the Mean.
• Which is the square of the standard deviation, ie: σ2
97.
Pass 1: ClusterBuilding
• During the first pass, the analyst is required to supply four types
of information-
• R, the radius distance in spectral space used to determine when a
new cluster should be formed.
• C, a spectral space distance parameter used when merging
clusters when N is reached.
• N, the number of pixels to be evaluated between each major
merging of clusters.
• Cmax , maximum no. of clusters to be identified.
Pass 2: Assignment of pixels to one of the Cmax clusters using
minimum distance classification logic.
102.
Pass 2: Assignmentof Pixels to one of the Cmax Clusters
using Minimum Distance Classification Logic
• The final cluster mean data vectors are used in a
minimum distance to means classification algorithm
to classify all the pixels in the image into one of the
Cmax clusters.
103.
Application of Unsupervisedlearning
• Anomaly detection: Unsupervised learning can identify unusual patterns
or deviations from normal behavior in data, enabling the detection of
fraud, intrusion, or system failures.
• Scientific discovery: Unsupervised learning can uncover hidden
relationships and patterns in scientific data, leading to new hypotheses
and insights in various scientific fields.
• Recommendation systems: Unsupervised learning can identify patterns
and similarities in user behavior and preferences to recommend
products, movies, or music that align with their interests.
• Customer segmentation: Unsupervised learning can identify groups of
customers with similar characteristics, allowing businesses to target
marketing campaigns and improve customer service more effectively.
• Image analysis: Unsupervised learning can group images based on their
content, facilitating tasks such as image classification, object detection,
and image retrieval.
104.
Advantages of Unsupervisedlearning
• It does not require training data to be labeled.
• Dimensionality reduction can be easily accomplished
using unsupervised learning.
• Capable of finding previously unknown patterns in data.
• Unsupervised learning can help you gain insights from
unlabeled data that you might not have been able to get
otherwise.
• Unsupervised learning is good at finding patterns and
relationships in data without being told what to look for.
This can help you learn new things about your data.
105.
Disadvantages of Unsupervisedlearning
• Difficult to measure accuracy or effectiveness due to
lack of predefined answers during training.
• The results often have lesser accuracy.
• The user needs to spend time interpreting and label
the classes which follow that classification.
• Unsupervised learning can be sensitive to data quality,
including missing values, outliers, and noisy data.
• Without labeled data, it can be difficult to evaluate the
performance of unsupervised learning models, making
it challenging to assess their effectiveness.