Download to read offline










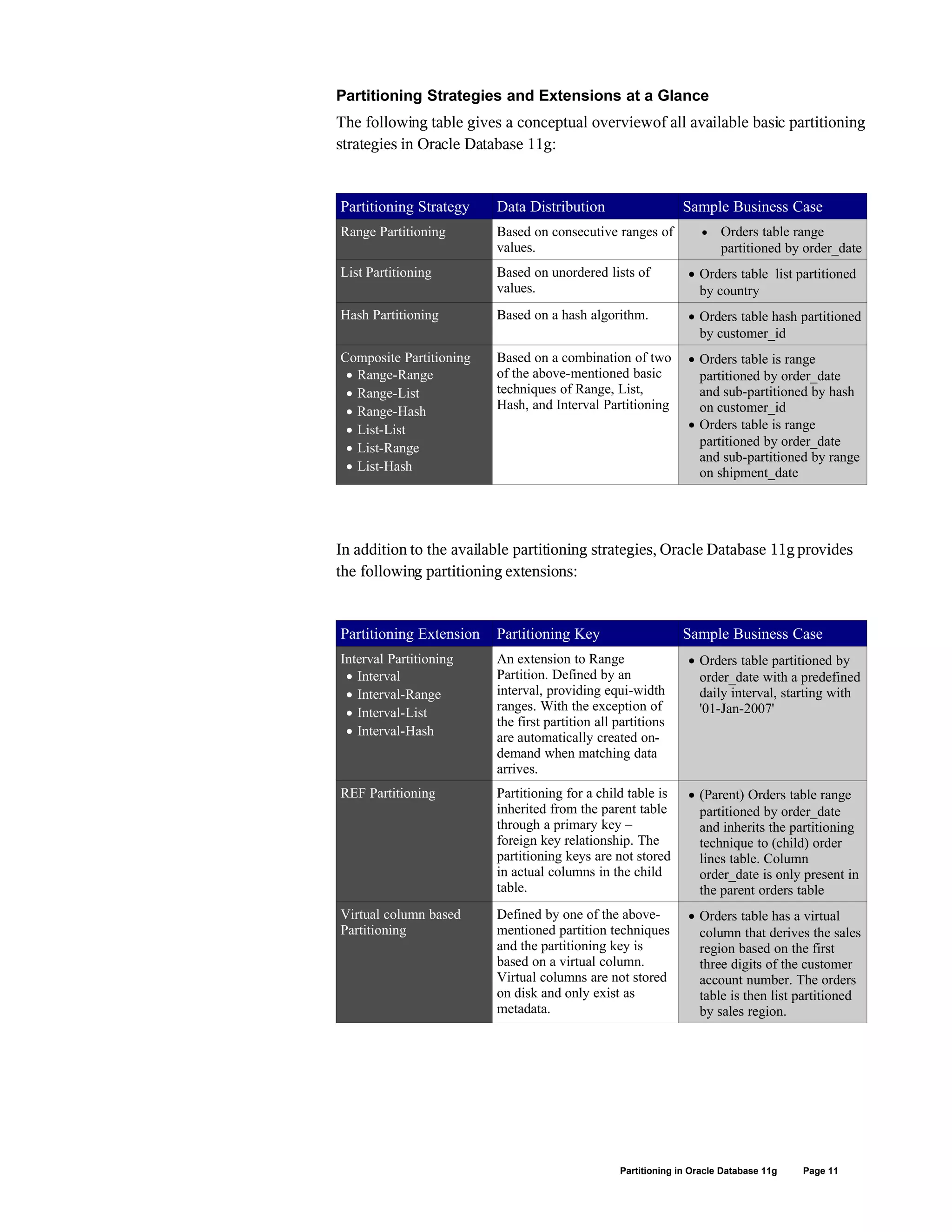



This document discusses partitioning in Oracle Database 11g. It introduces partitioning concepts and strategies including range, list, hash, interval and reference partitioning. It describes how partitioning can improve performance through pruning and partition-wise joins. It also explains how partitioning enhances manageability through maintenance operations on individual partitions and improves availability through partition independence. The document outlines Oracle Database 11g's extensions to partitioning including interval partitioning, reference partitioning, and virtual column-based partitioning.















































































![Computer Networks 01[1 using all terms].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/computernetworks011-251214040533-327dd9f8-thumbnail.jpg?width=640&height=640&fit=bounds)


