






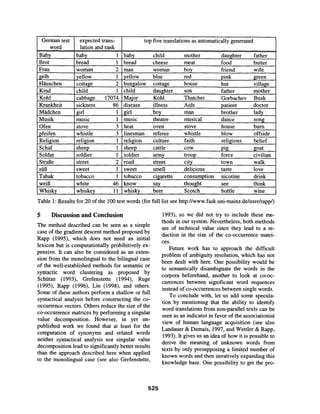


This document summarizes an approach for identifying word translations from non-parallel (unrelated) English and German corpora. It uses a co-occurrence clue, assuming words that frequently co-occur in one language will have translations that co-occur frequently in the other language. The approach computes association vectors for words based on log-likelihood ratios of co-occurrence counts within a 3-word window. It determines the translation of an unknown German word by finding the most similar association vector in an English co-occurrence matrix. Evaluation on 100 test words showed an accuracy of around 72%, a significant improvement over previous methods for non-parallel texts.


























































