Download to read offline




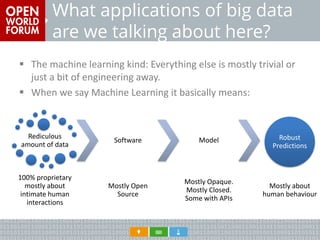
















Ori Pekelman discusses combining big data and open source strategies. He is the founder of several data meetups in Paris focused on functional programming languages and big data. He notes that big data applications predominantly use open source software but rely on proprietary data sources and opaque predictive models. Pekelman argues for greater collaboration on open data and models to avoid overdependence on external predictive APIs and ensure privacy and fairness in how data is used.

















![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























































![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)




