Download to read offline





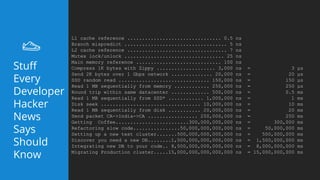
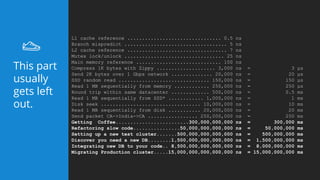


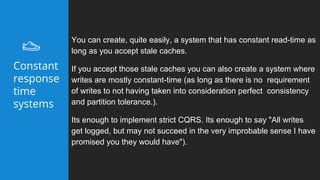


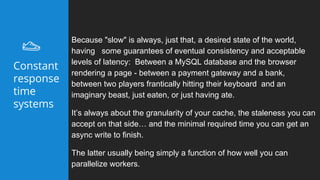

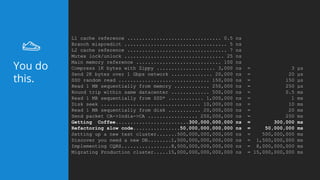
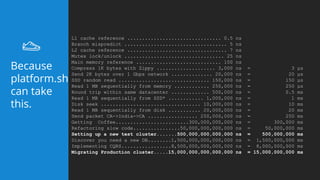
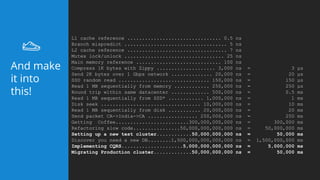




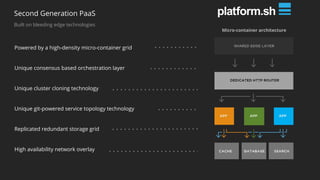


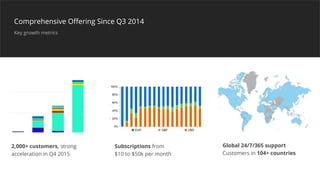






This document summarizes a presentation about latency optimization and constant response time systems. It discusses where execution time latencies come from and compares execution time to code time. It presents that given infinite latency, any desired quality of a distributed system can be achieved. It also discusses how constant read and write times can be achieved through caching and eventual consistency. It promotes focusing on solving new problems rather than solved problems. It presents Platform.sh and Blackfire.io as tools that can help optimize tight loops and achieve constant response times by automating infrastructure tasks.





























































