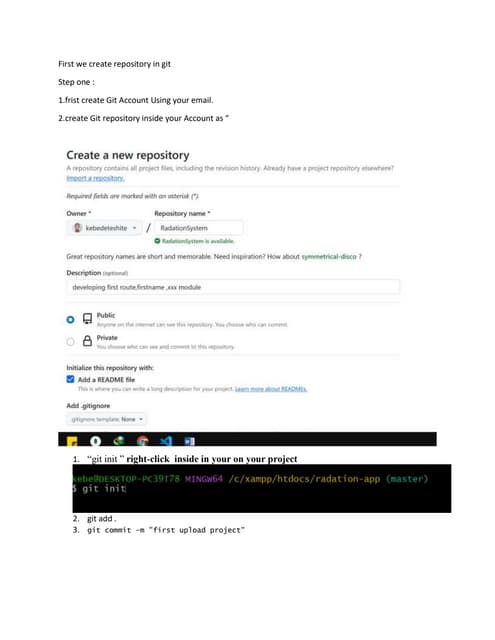
Download to read offline


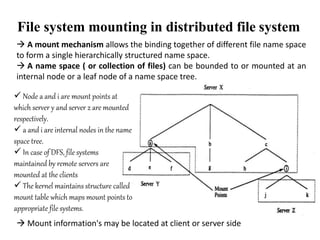





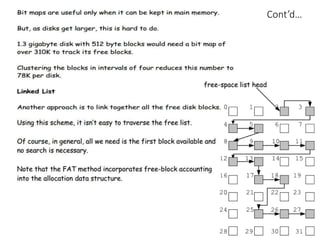




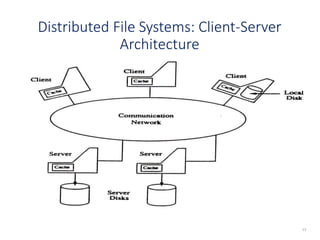

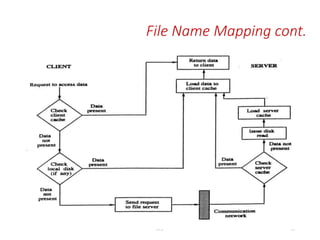


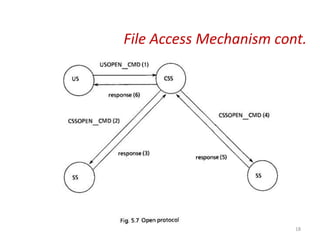
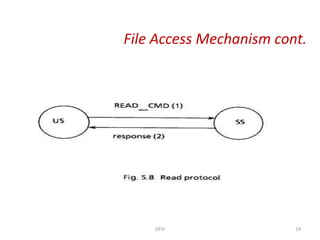
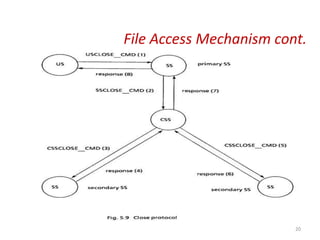






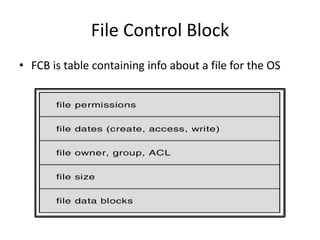








The document discusses several aspects of file and directory structure in operating systems. It describes different approaches to implementing directories, including linear lists and hash tables. It also discusses file access mechanisms in distributed file systems, including how file name mapping, caching, and various protocols for open, read, and close operations work. The key components of a file system structure, such as the logical file system, file organization module, and layers of an application program, logical file system, and file organization are also summarized.