Downloaded 11 times














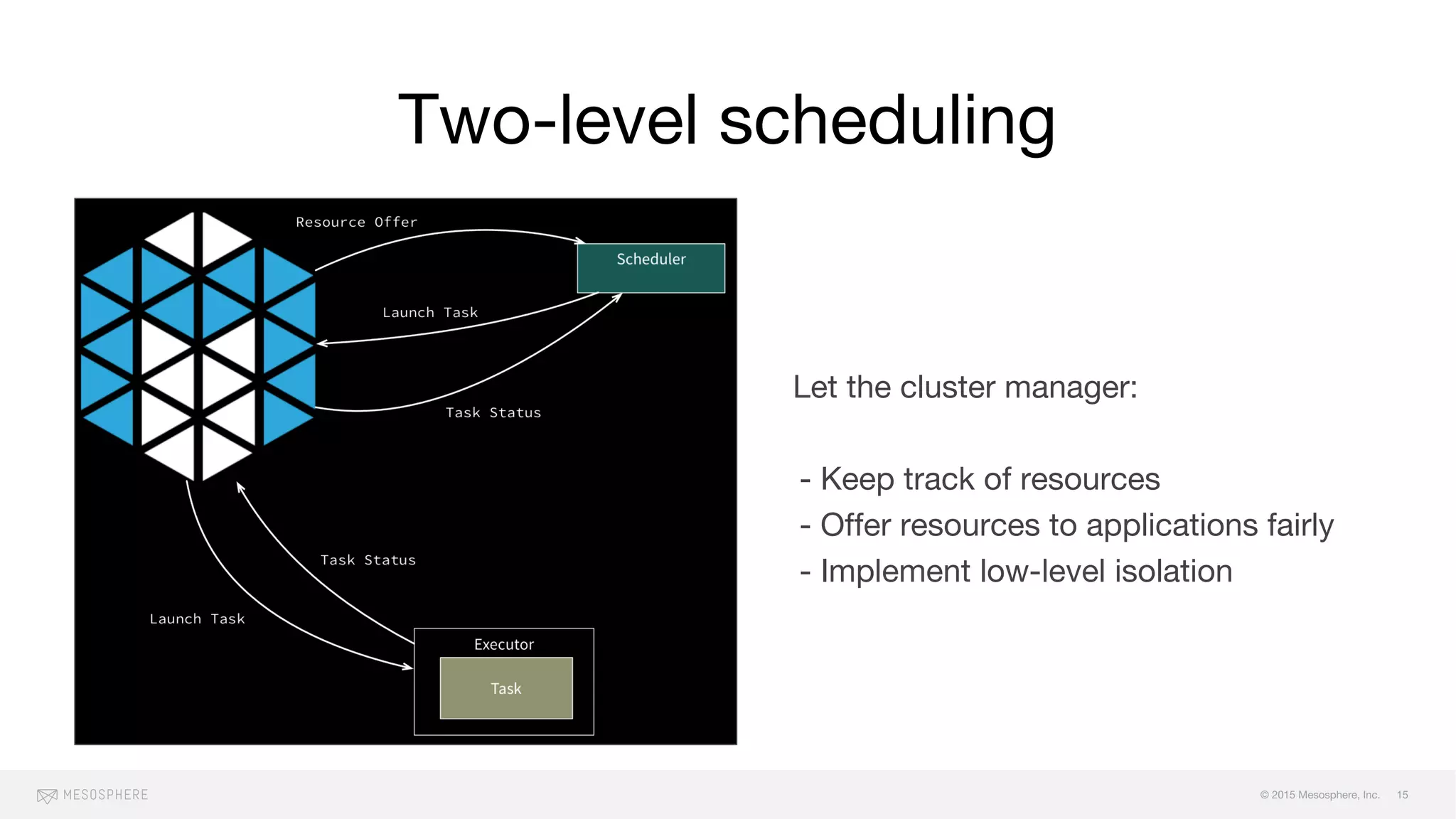
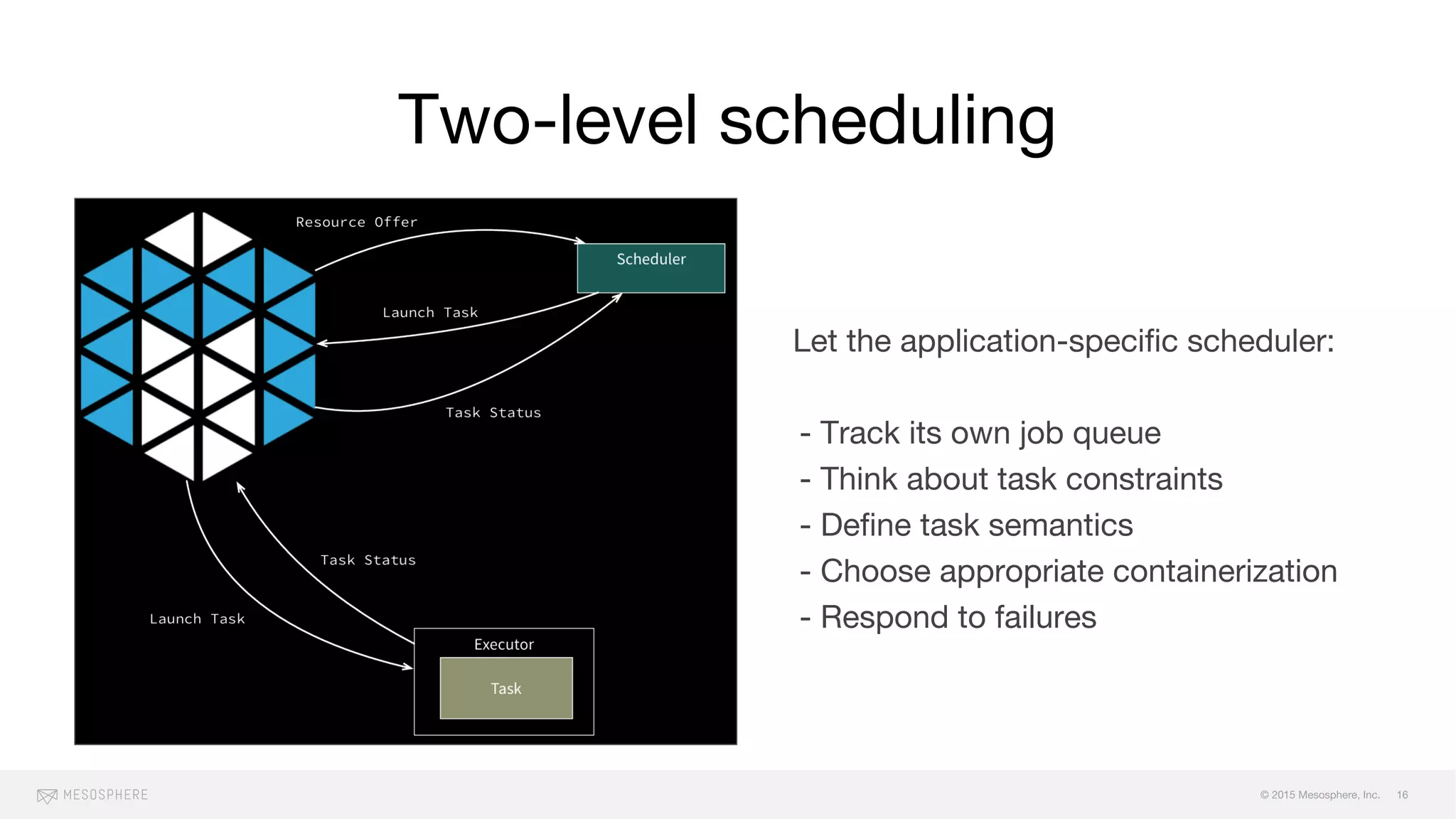

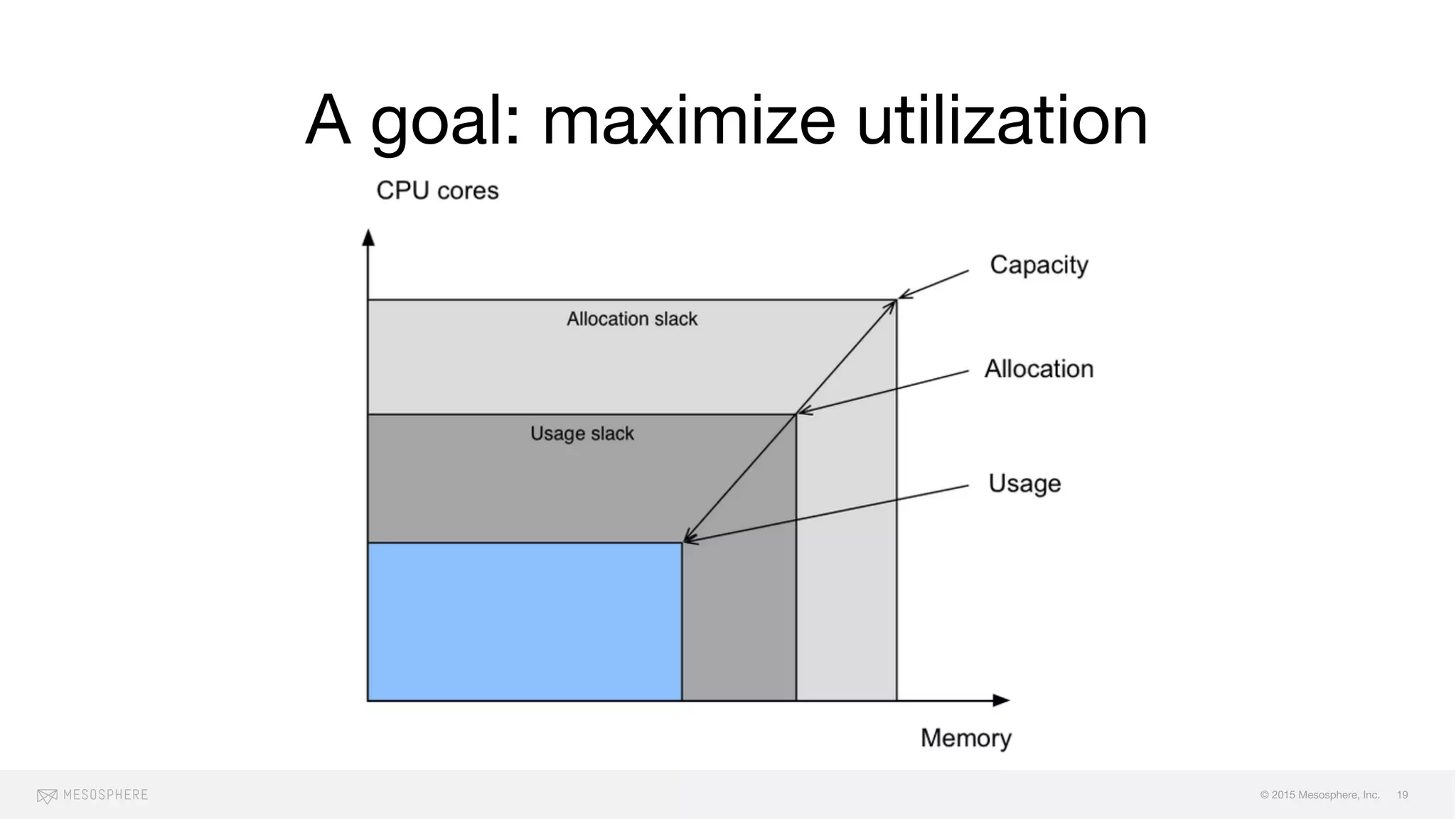



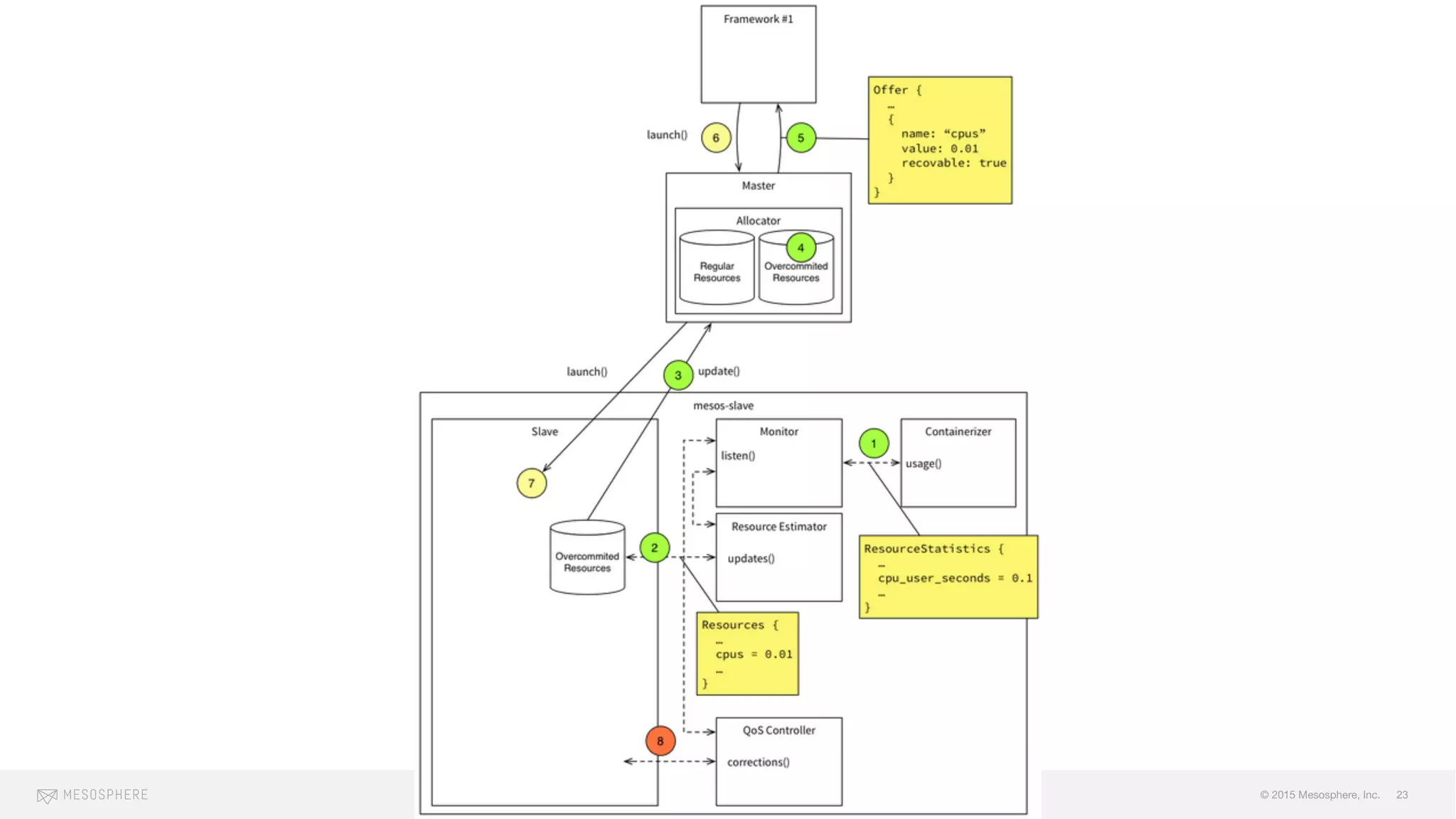
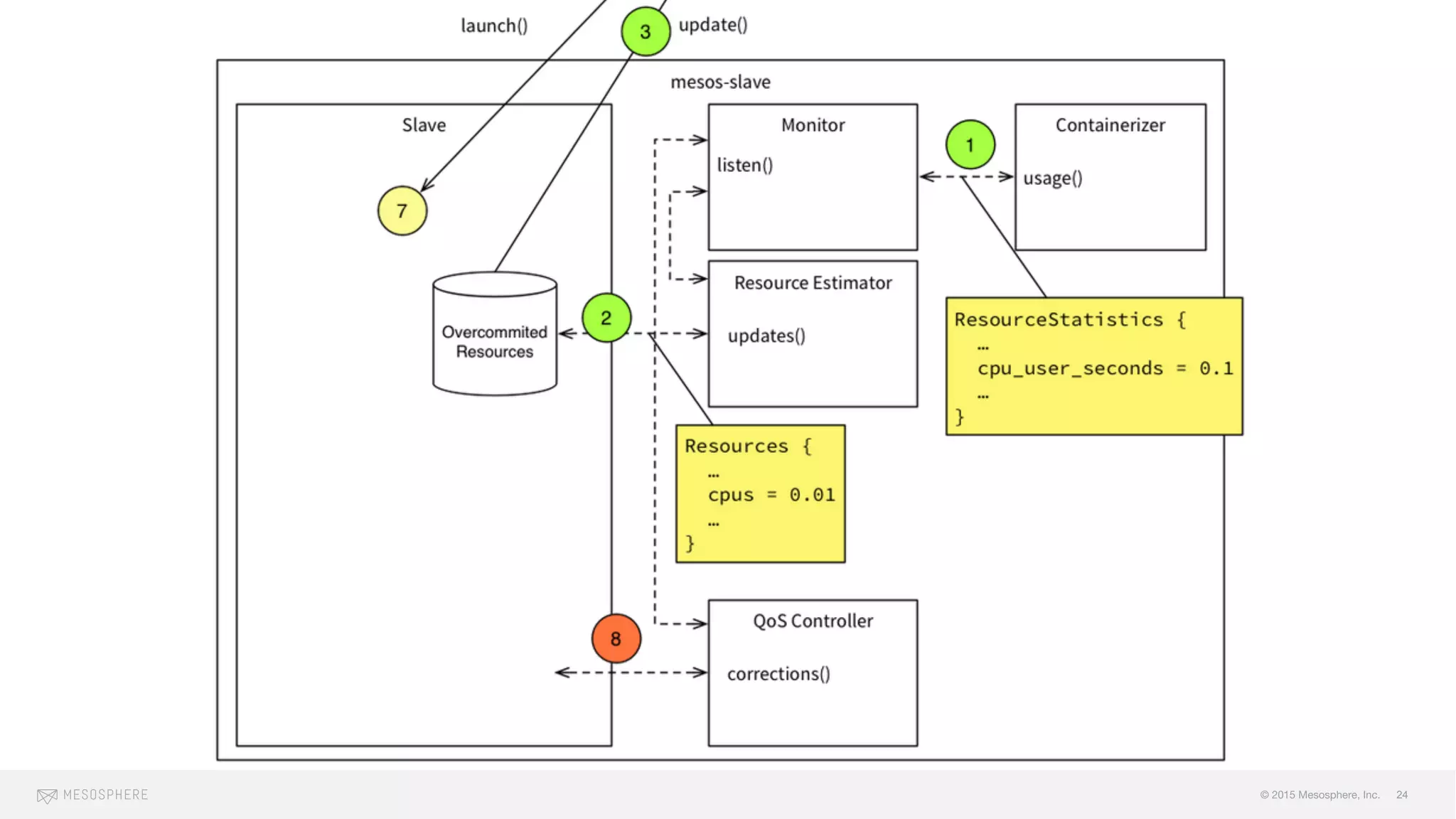





The document discusses the challenges and opportunities associated with container orchestration, emphasizing the importance of scheduling in achieving stability, performance, and flexibility. It explores various scheduling models, including centralized, decentralized, and two-level scheduling, highlighting the need for effective resource management and handling of failures. Additionally, it addresses issues related to scaling, resource contention, and orderly downtime in clusters.






















































































