



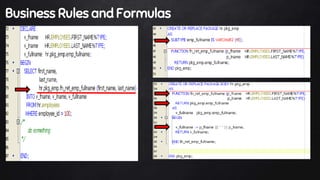
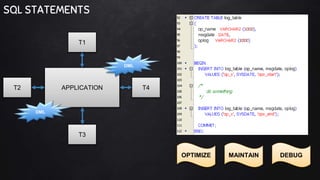
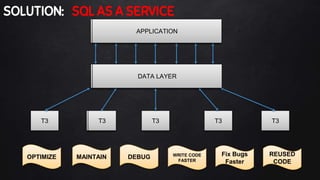



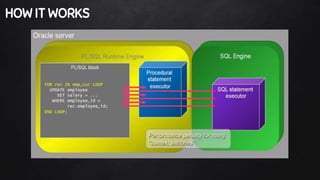
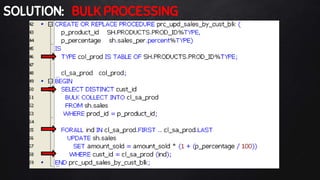
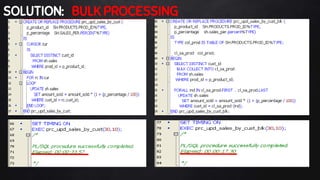
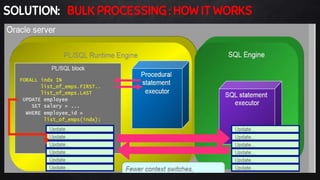



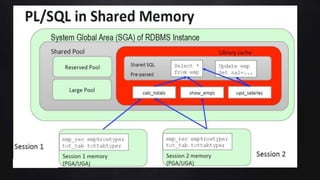





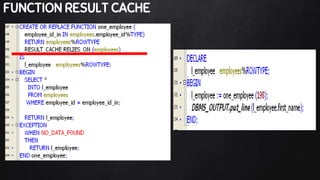
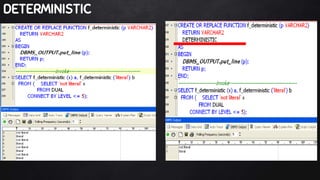
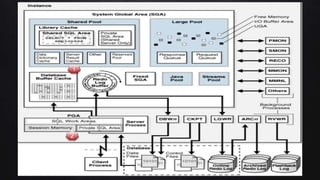


This document discusses best practices for PL/SQL including avoiding hard coding, row-by-row processing, and memory management. It recommends using SQL as a service, bulk processing, bulk collect with limit clause, and NOCOPY hint for memory. It also discusses data caching techniques like deterministic functions, PGA caching, and function result cache to improve performance.




































































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)














