Download to read offline











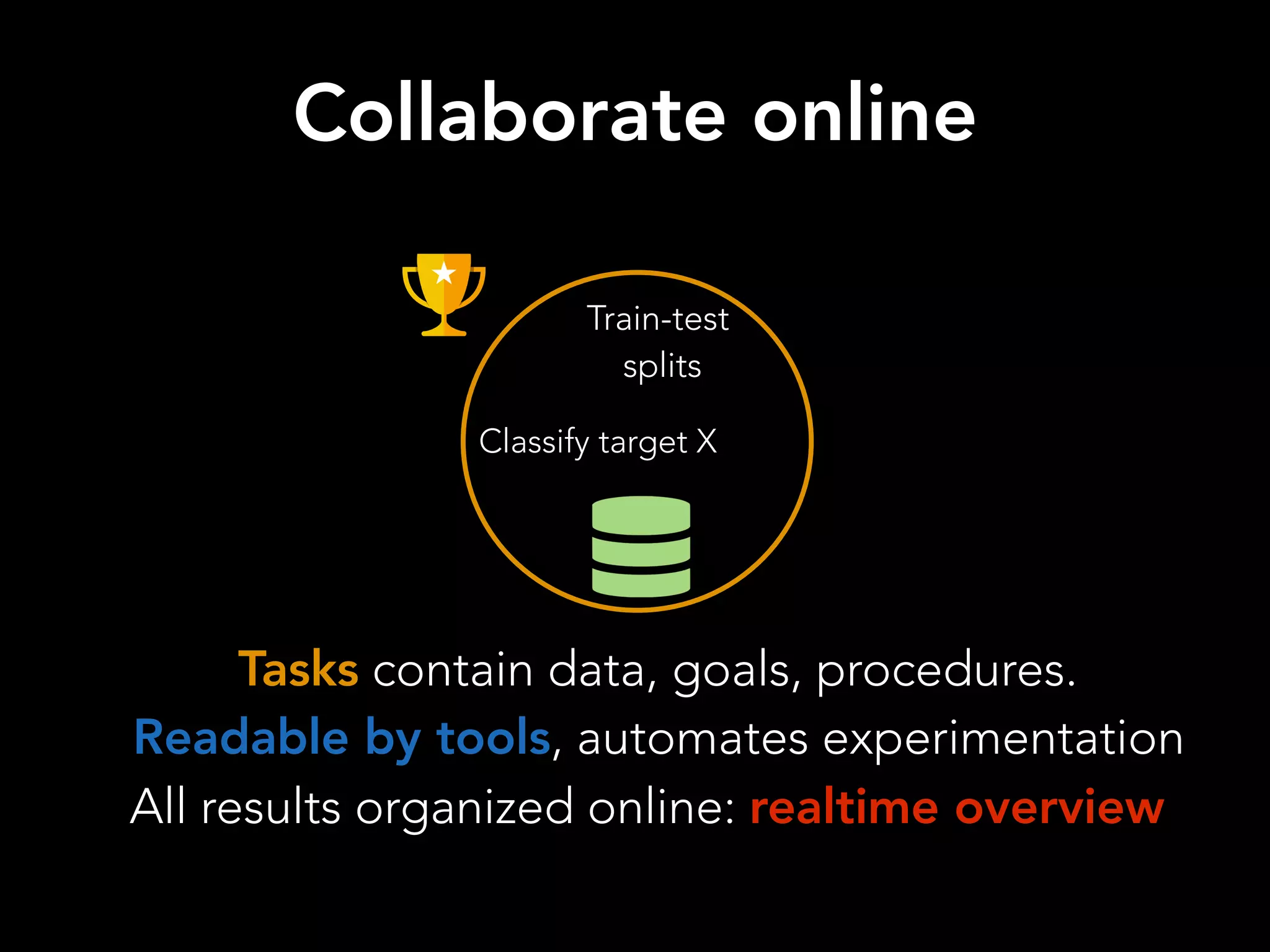
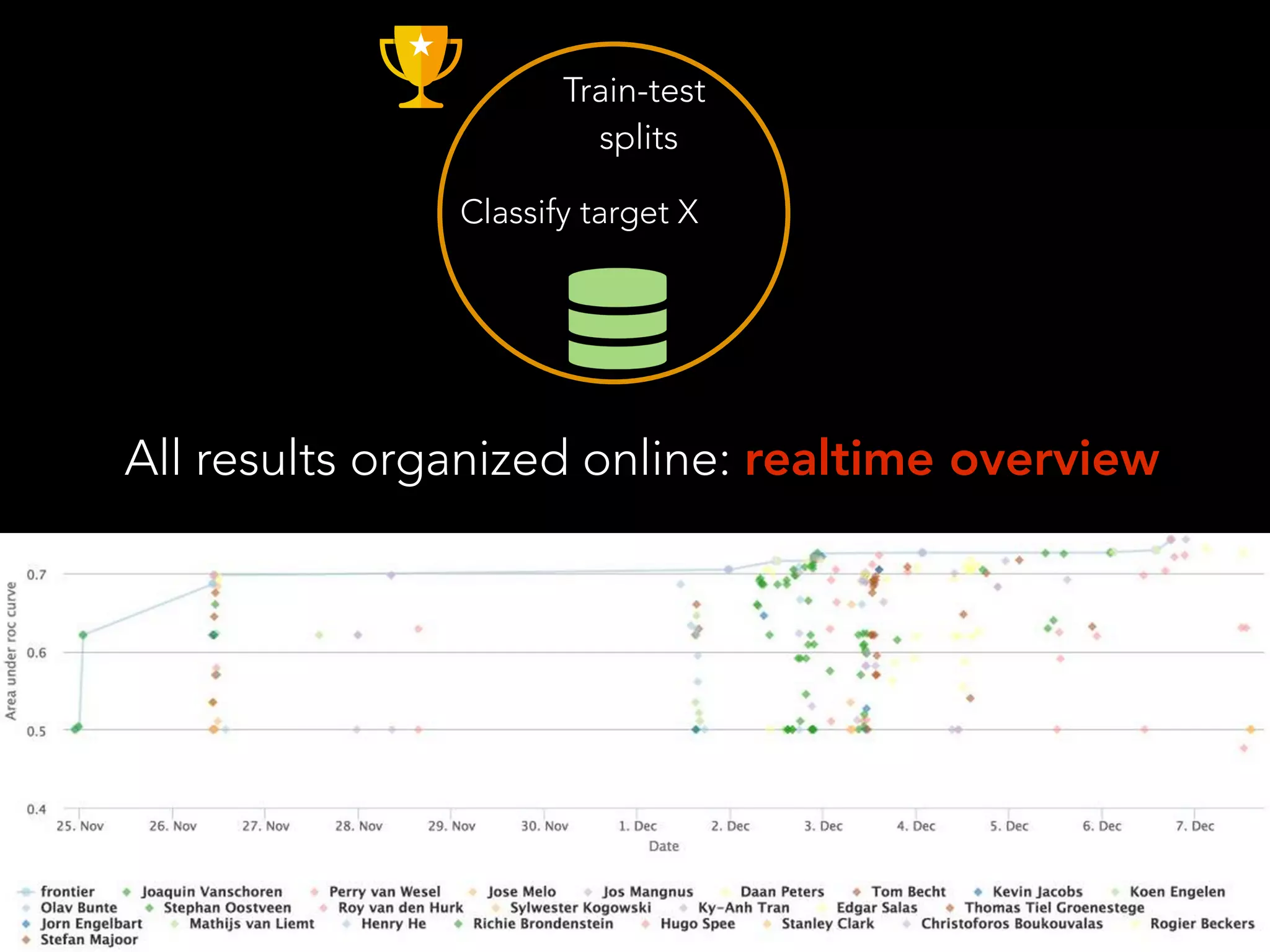

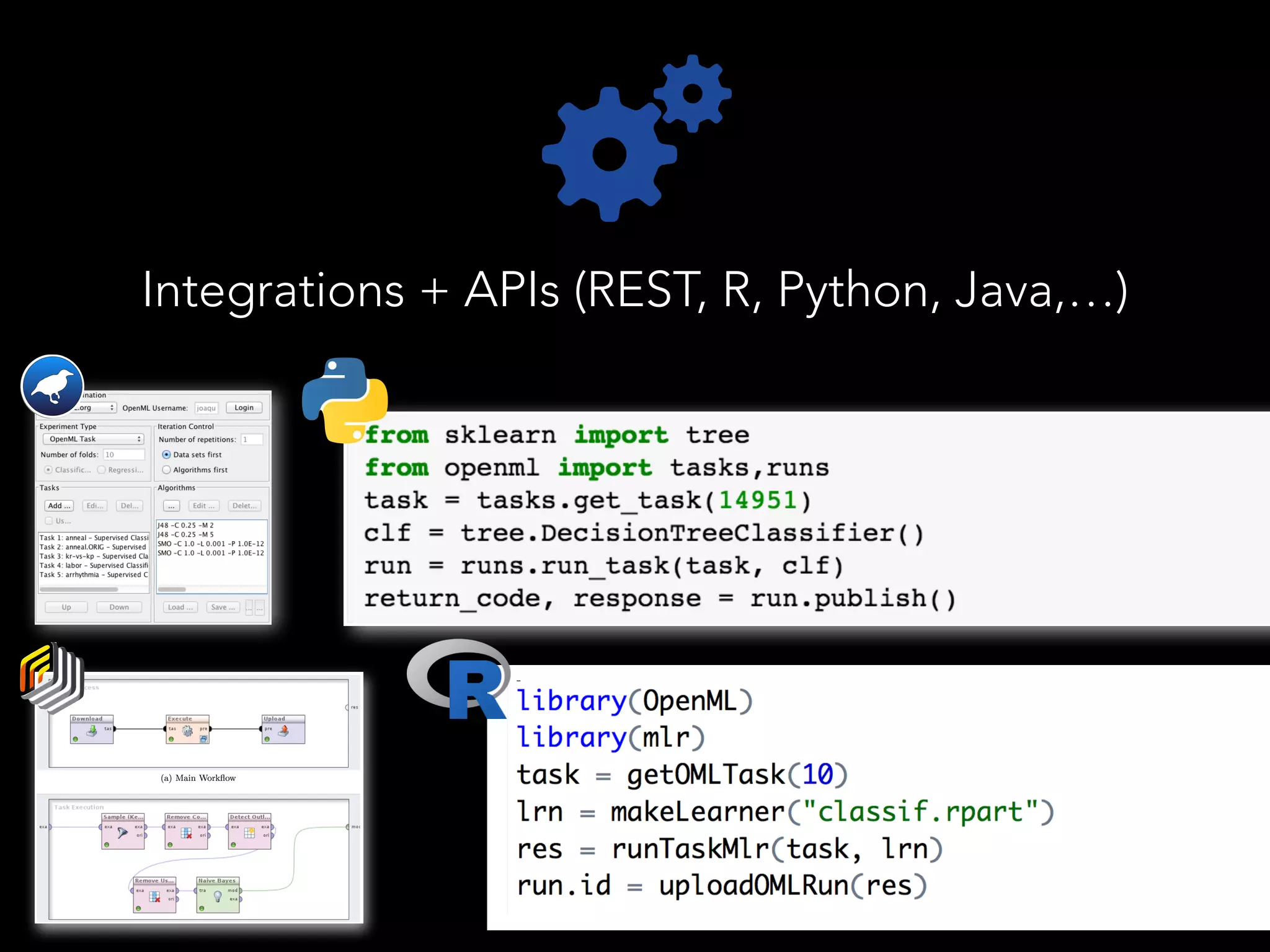


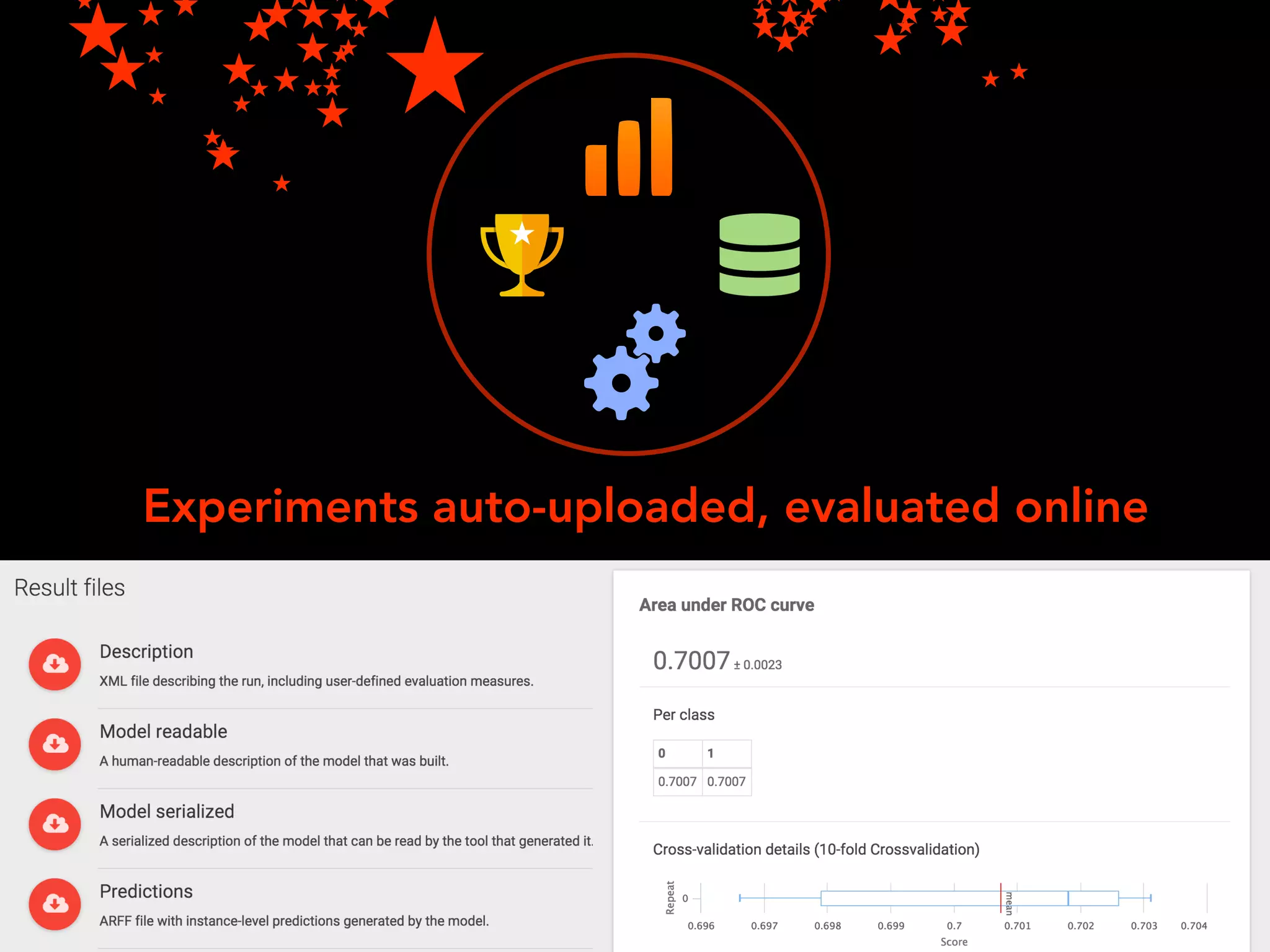
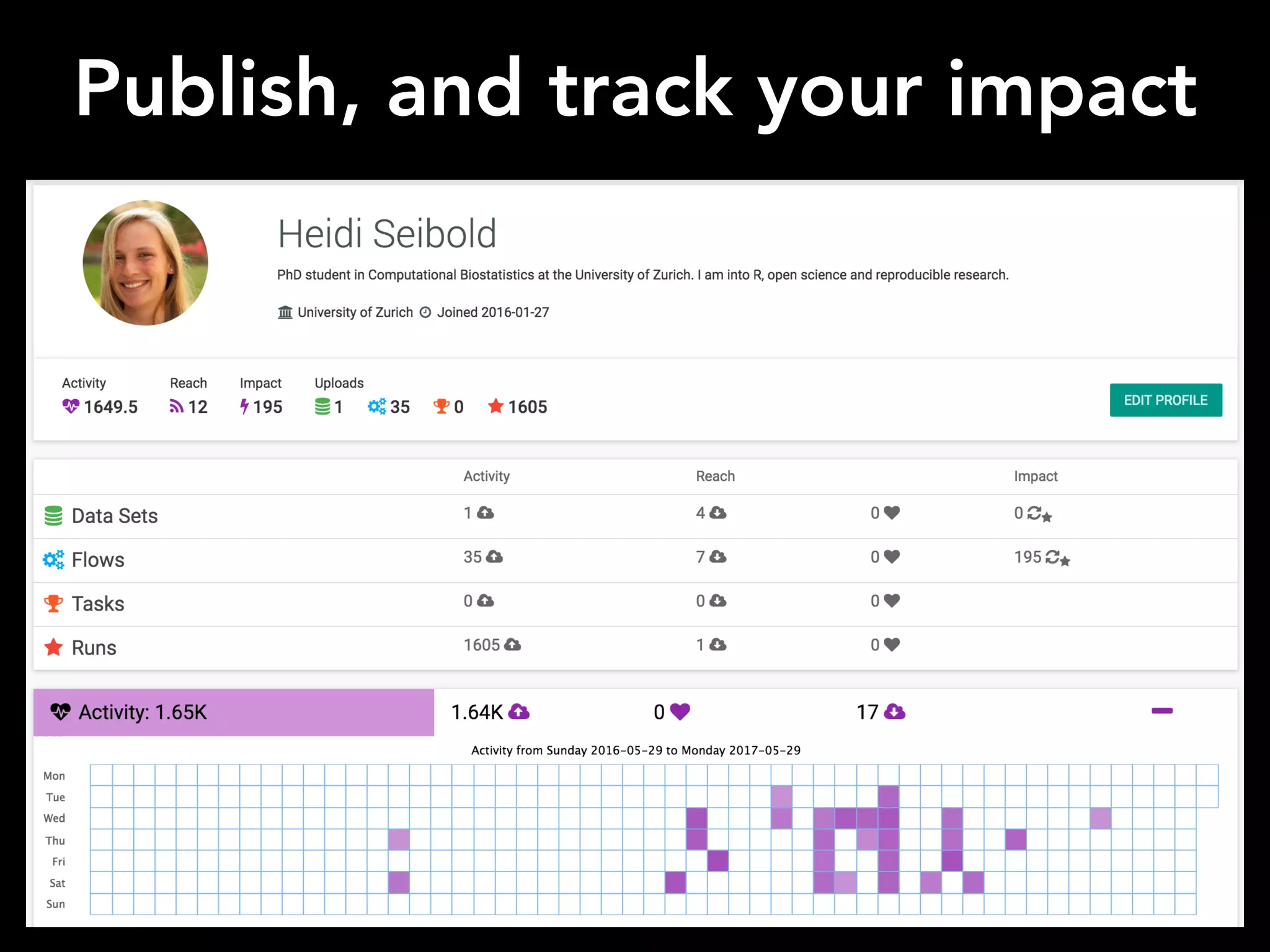
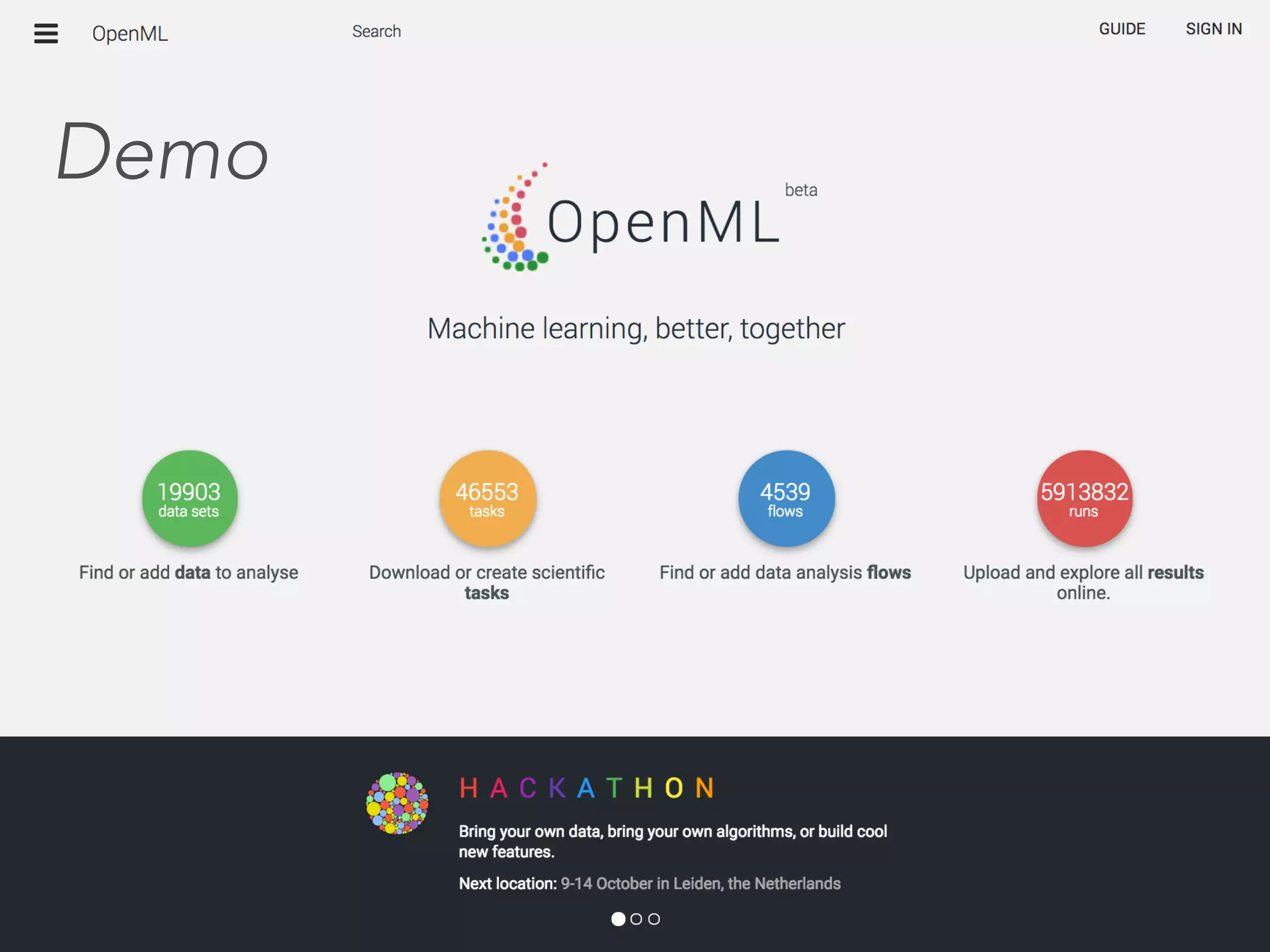
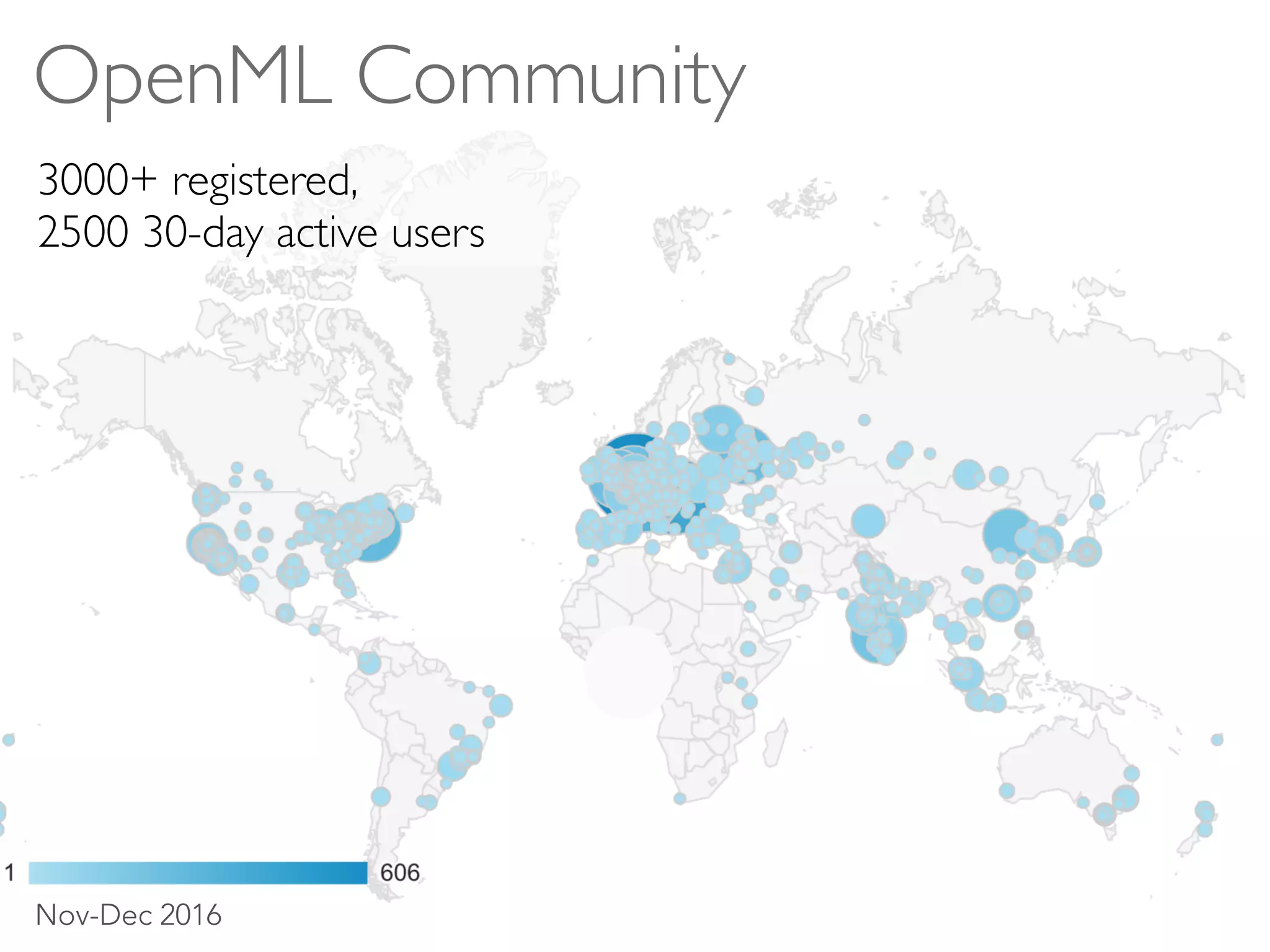





The document discusses OpenML, a platform designed to enhance reproducibility and collaboration in machine learning. It highlights challenges in data accessibility, code usage, and experimentation, proposing solutions such as easy online sharing of datasets and integration with various tools. OpenML aims to facilitate real-time collaborative analysis, streamline experimentation, and provide a structured reward system for contributions, fostering a community-driven approach to machine learning.


























































