Downloaded 51 times

























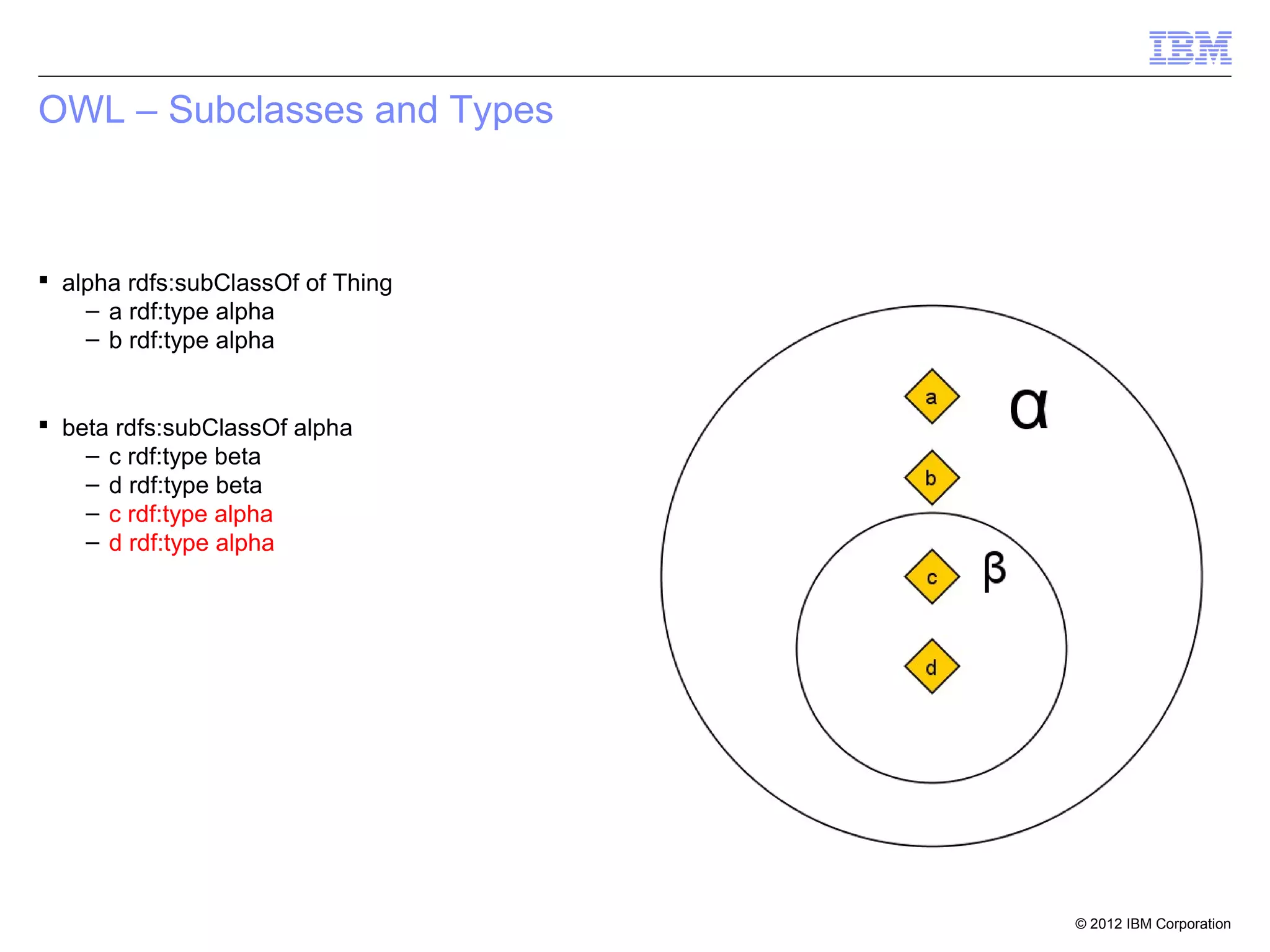
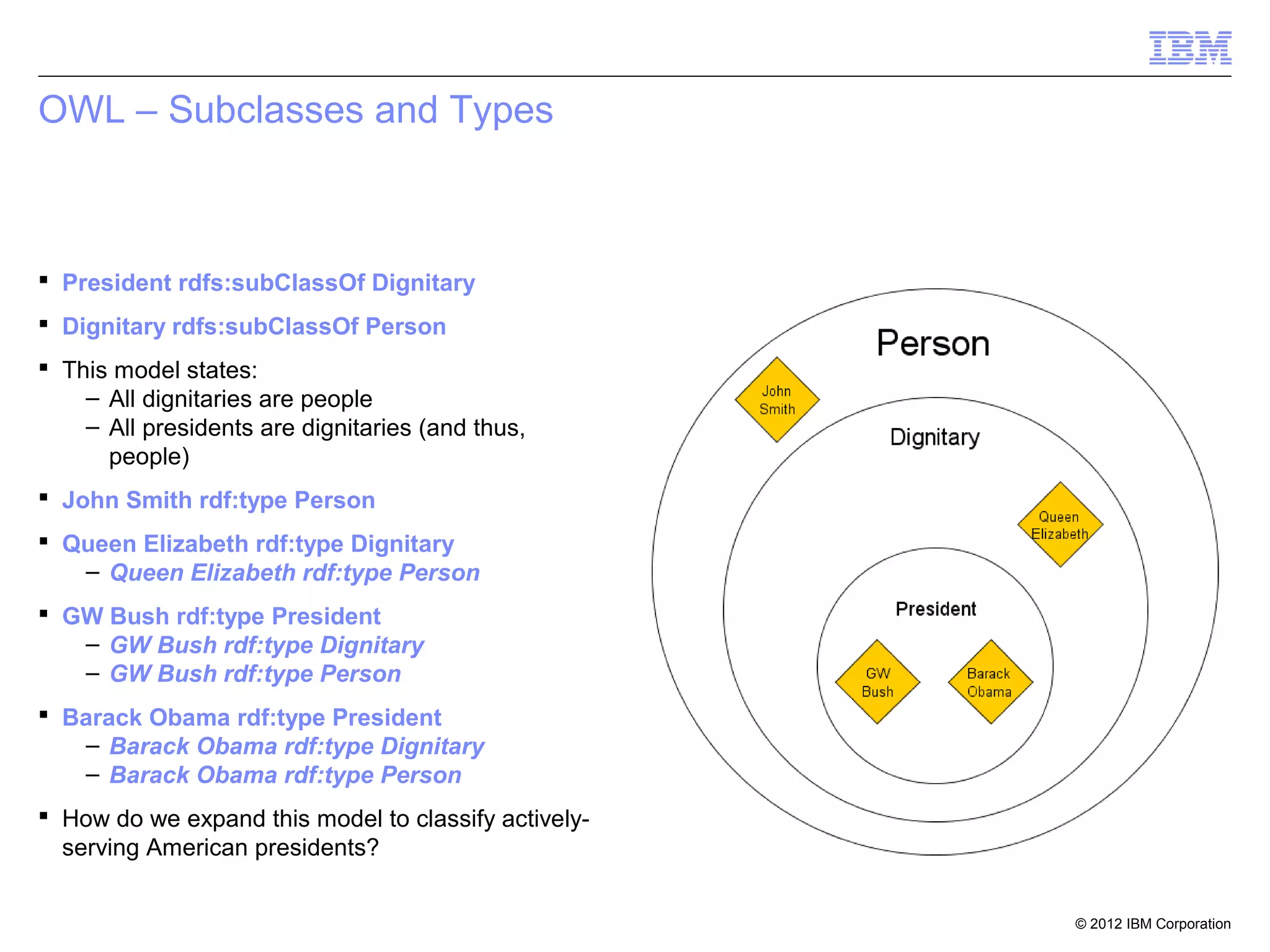
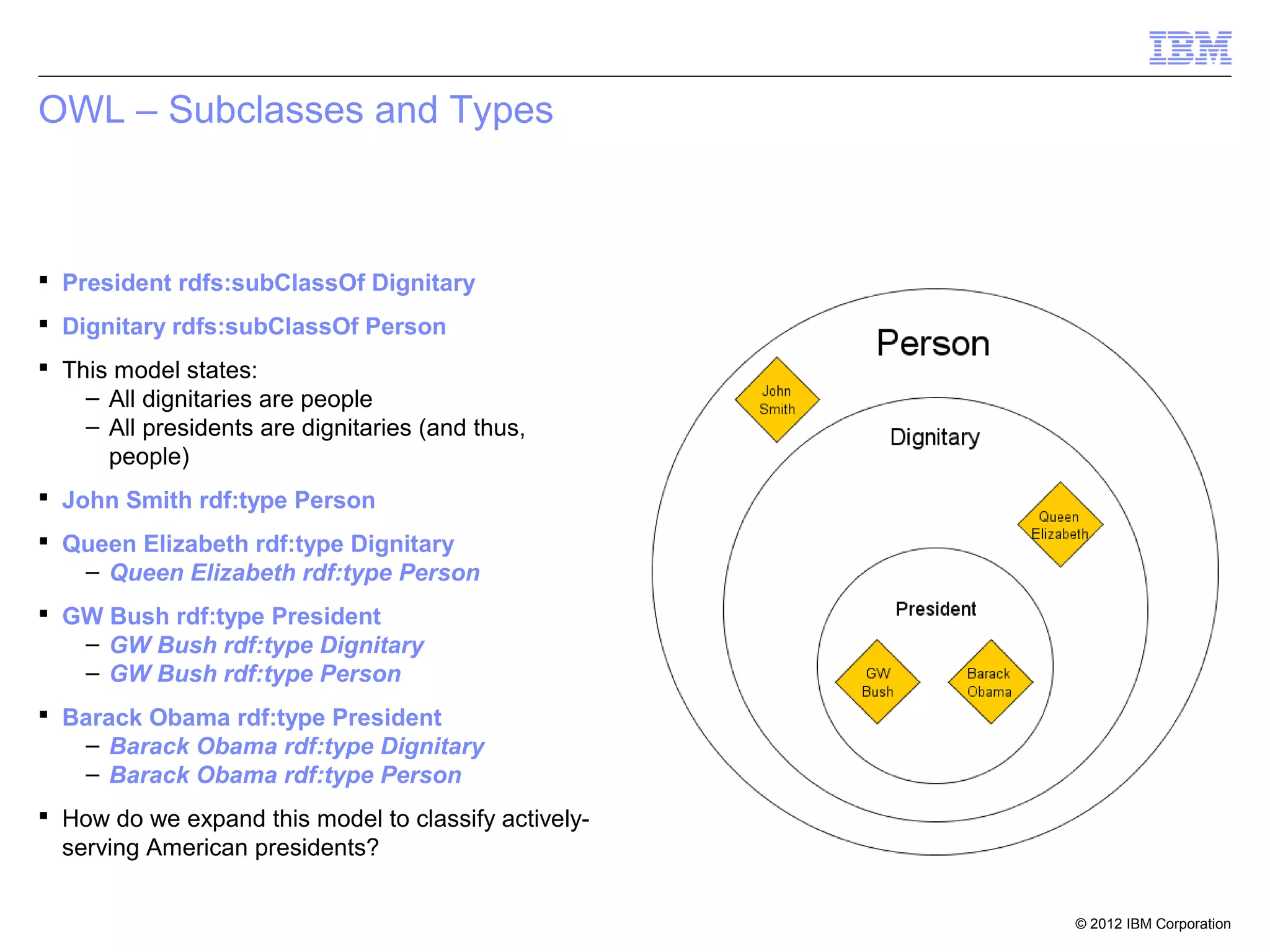

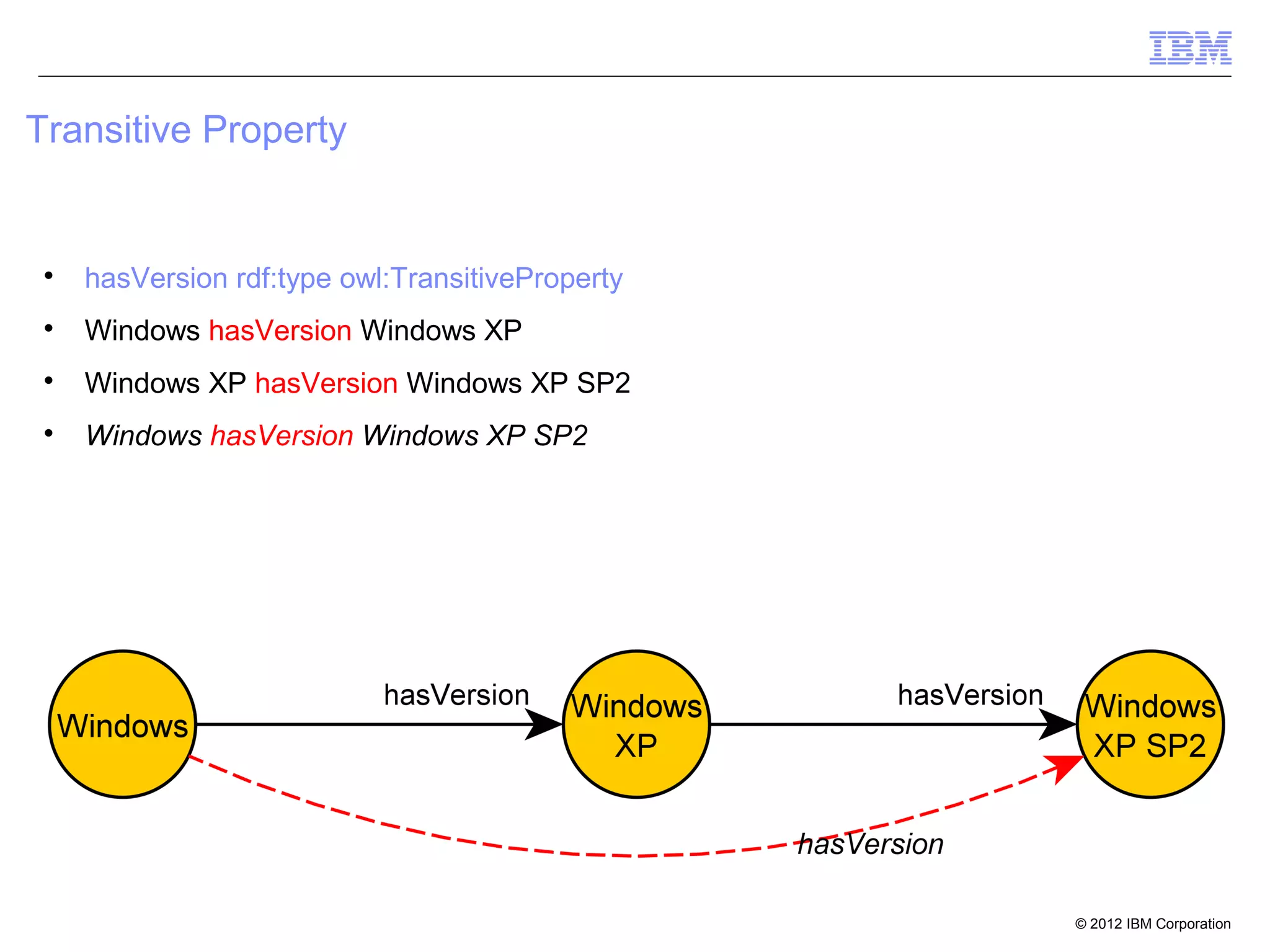

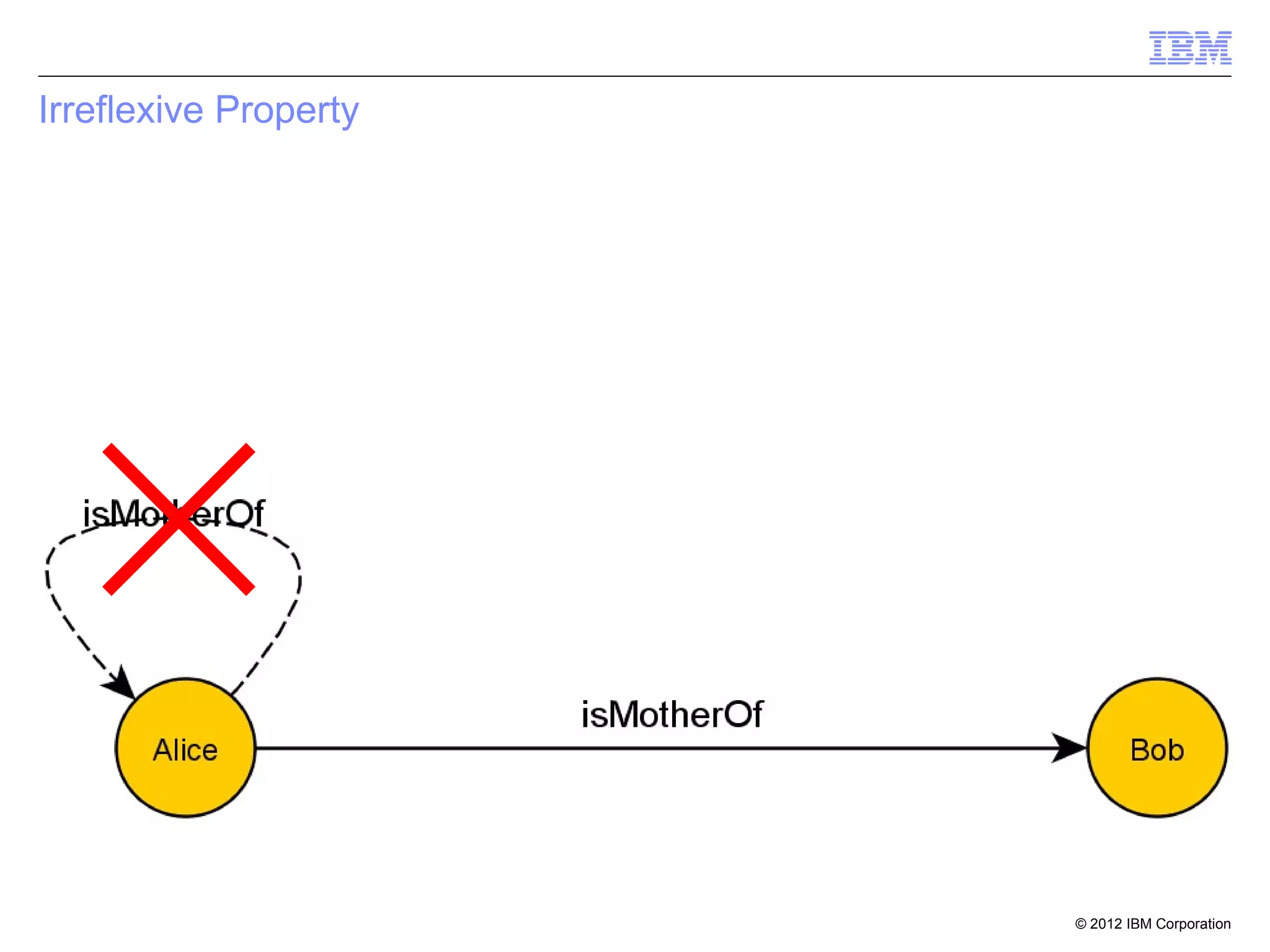
![Property Chain
[] rdfs:subPropertyOf hasGrandfather;
owl:propertyChain (
hasFather
hasFather
).
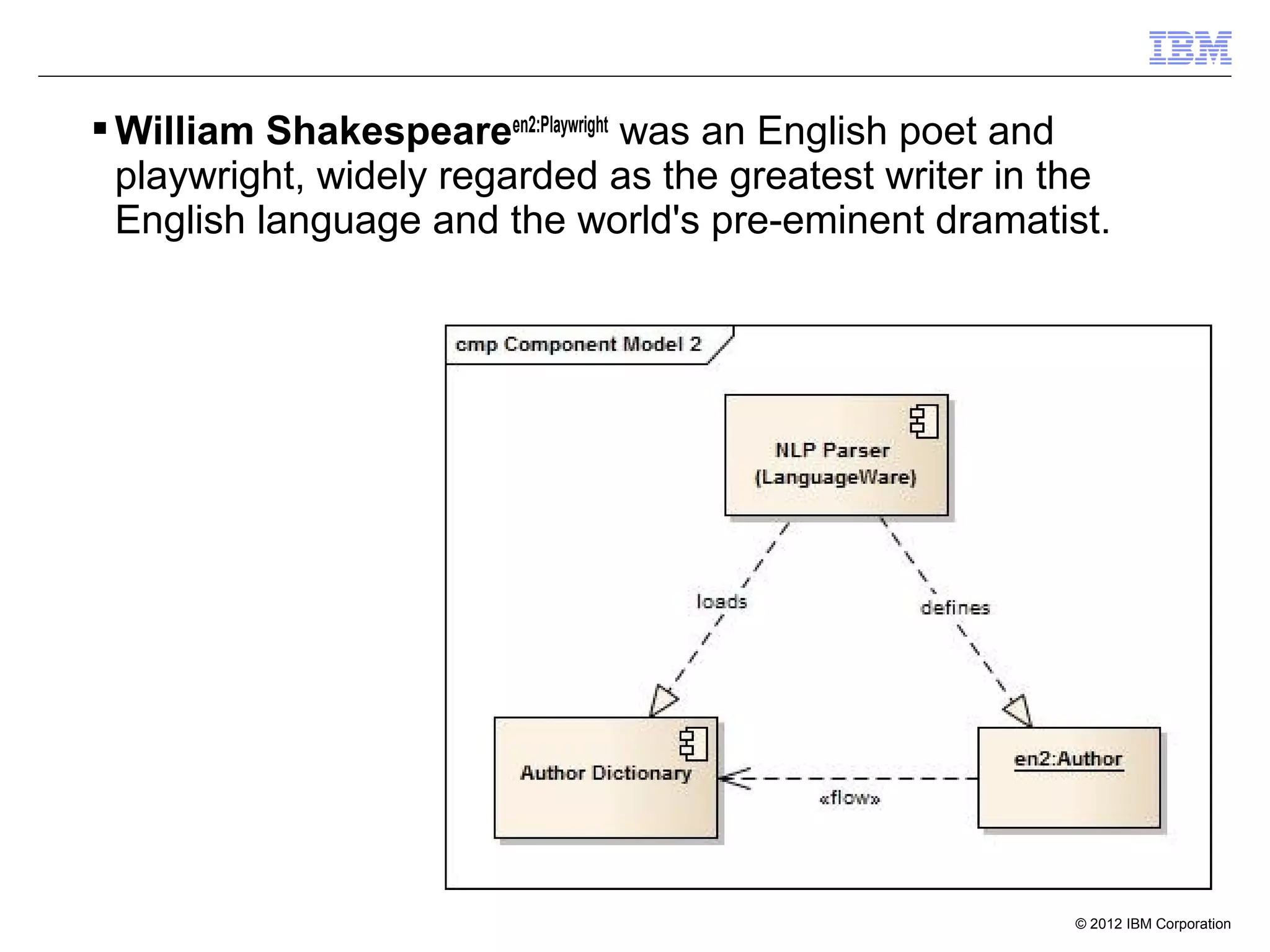
John III hasFather John JR
John JR hasFather John SR
John III hasGrandfather John SR
© 2012 IBM Corporation](https://image.slidesharecdn.com/ontologyandsemanticweb2011-130117144811-phpapp01/75/Ontology-and-semantic-web-2016-57-2048.jpg)









![Design Styles
Avoid proliferating owl:inverseOf [1]
© 2012 IBM Corporation](https://image.slidesharecdn.com/ontologyandsemanticweb2011-130117144811-phpapp01/75/Ontology-and-semantic-web-2016-70-2048.jpg)

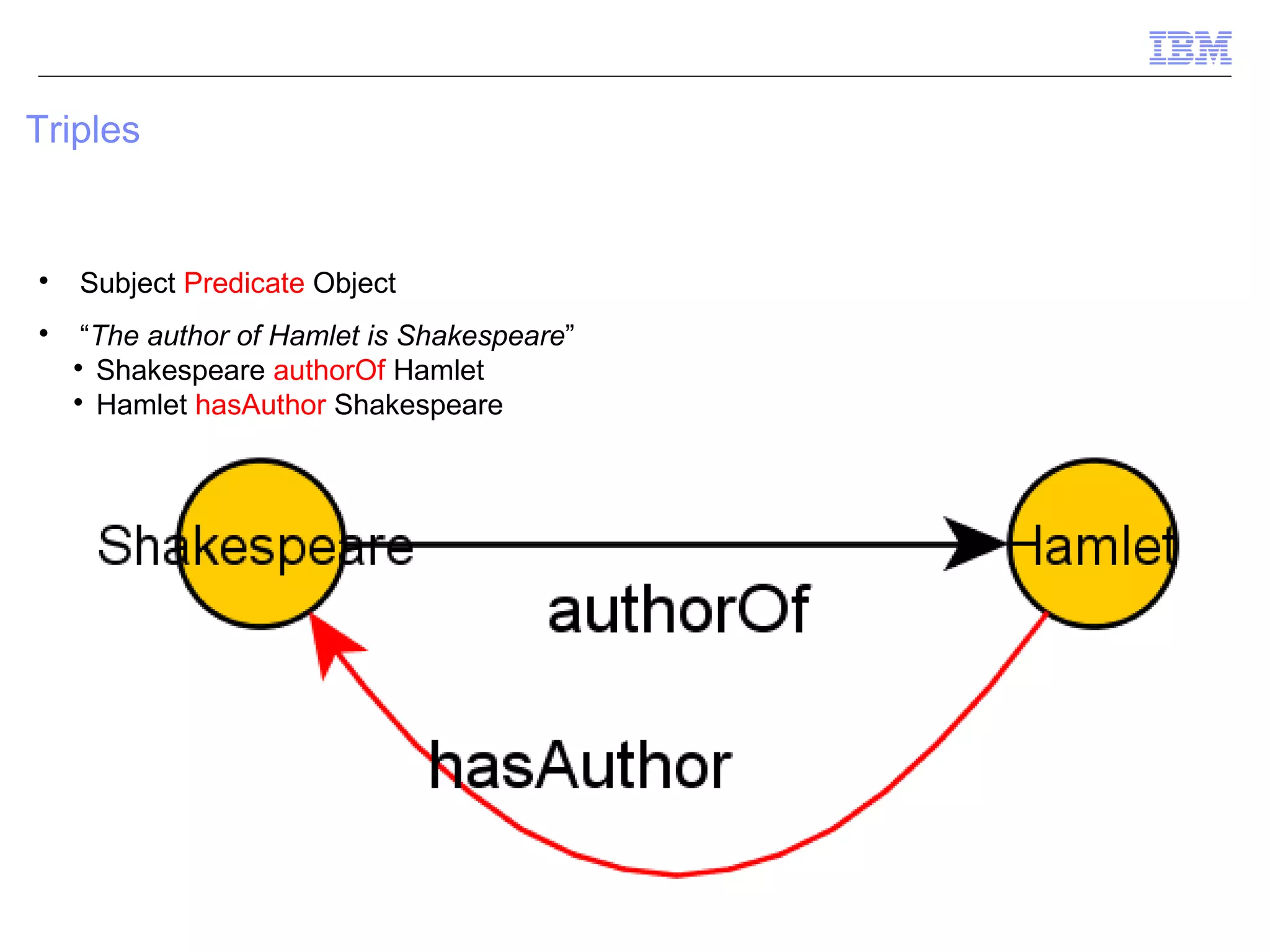
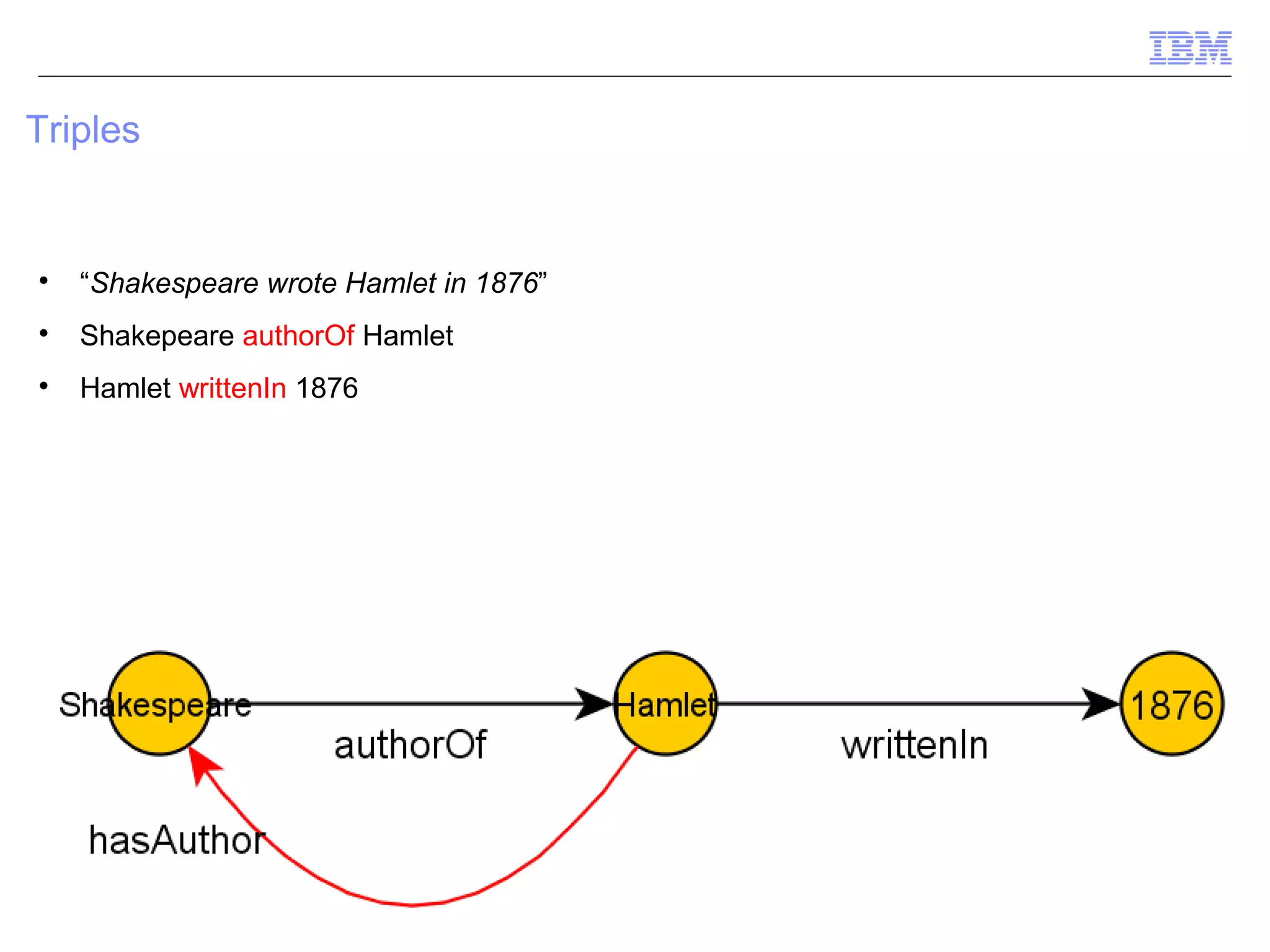
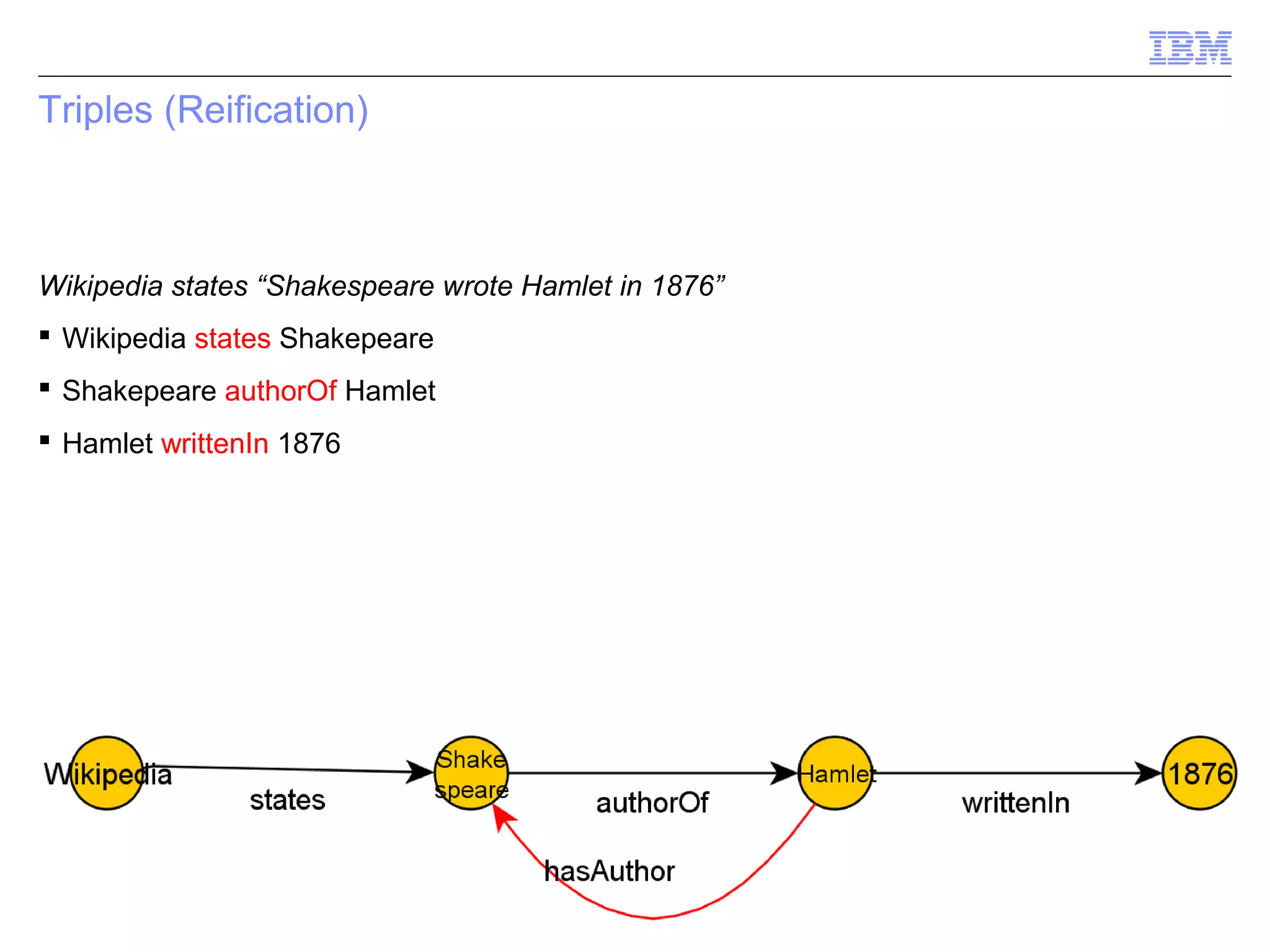
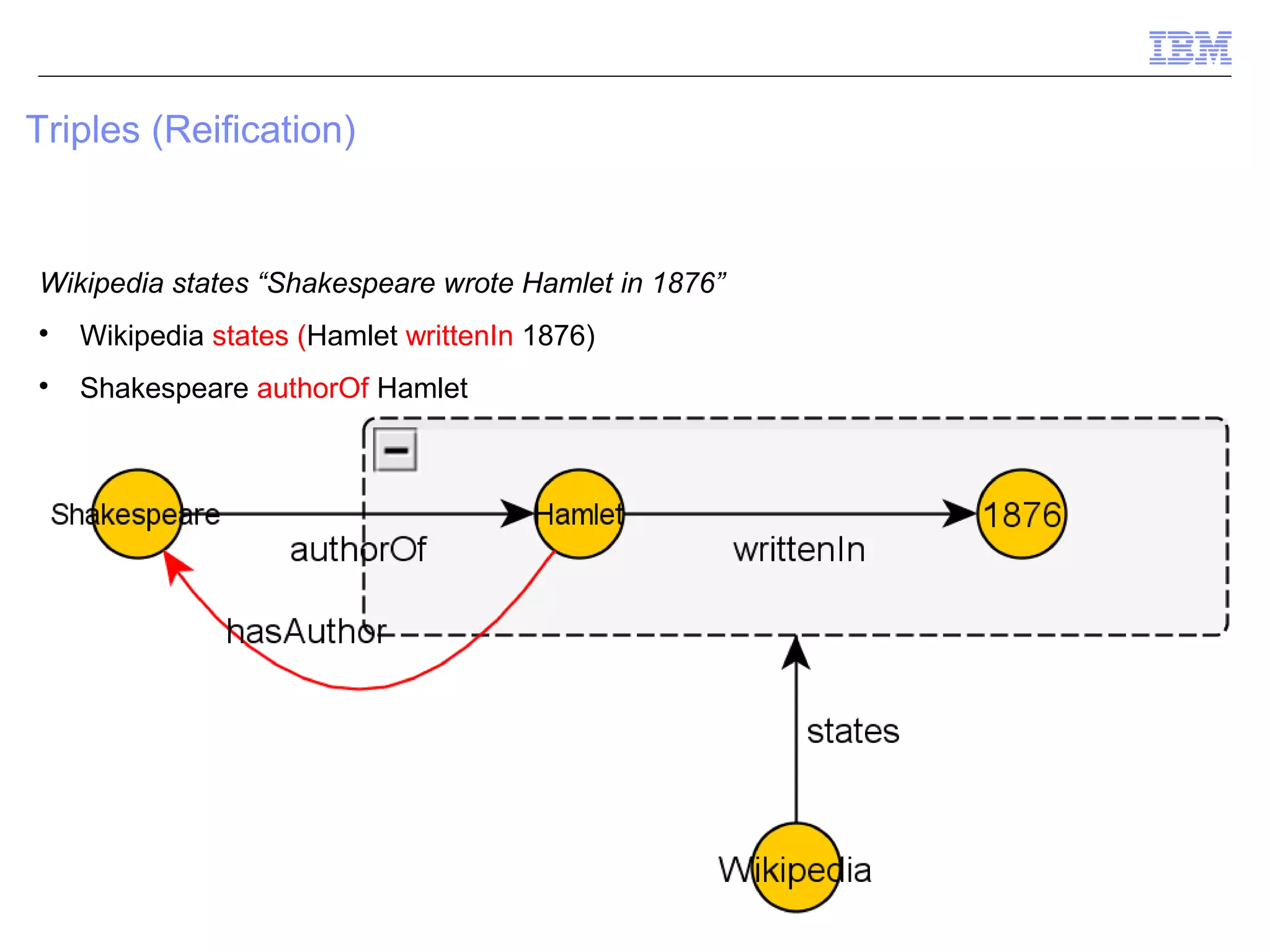
This document provides an outline and overview of ontologies and the semantic web. It discusses triples, ontologies, SPARQL, inferencing, and methodology for creating a semantic network. Triples, reification, confidence levels, ontology design, architecture, and components are covered. Methodology includes building a semantic network from natural language processing.


















































































