





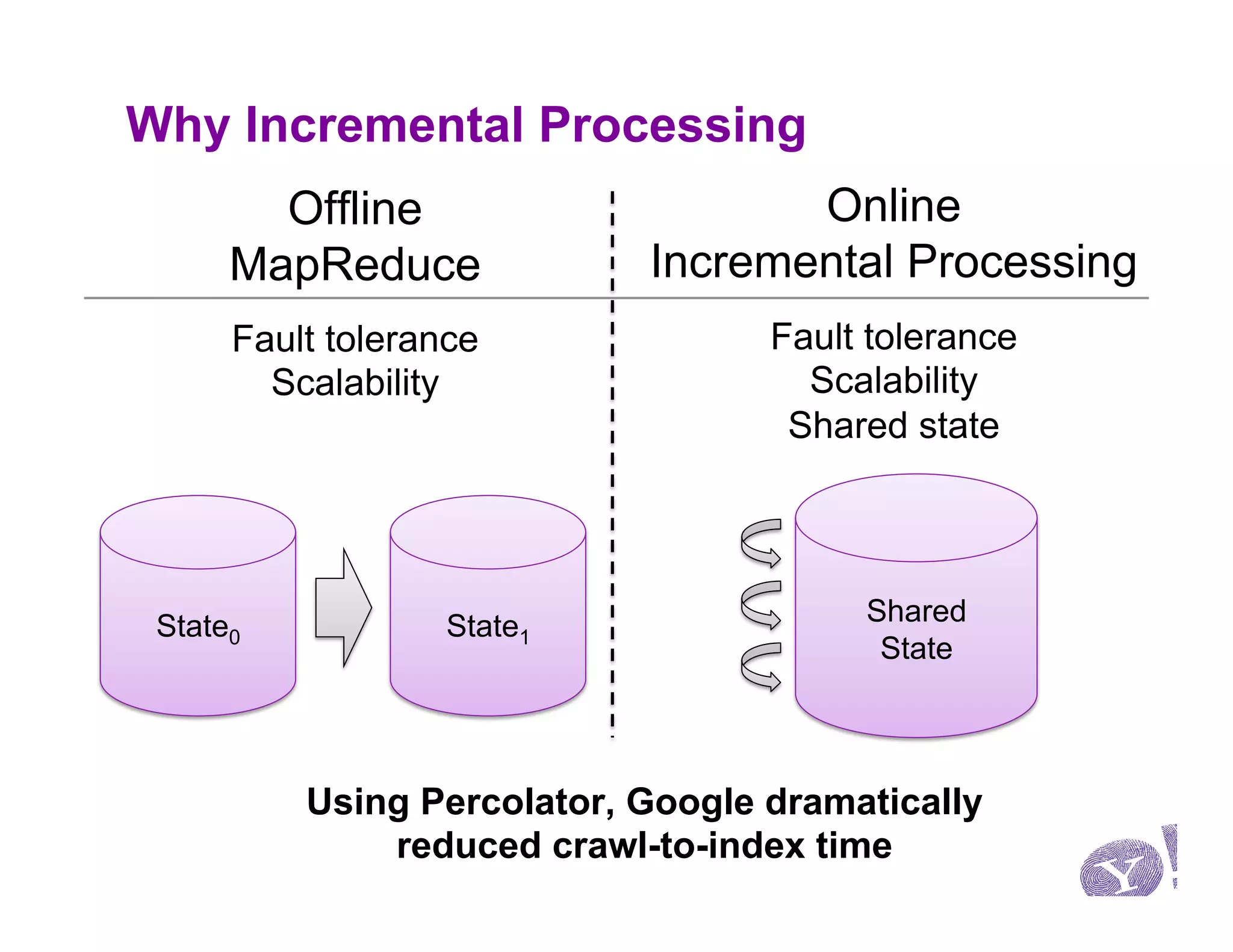



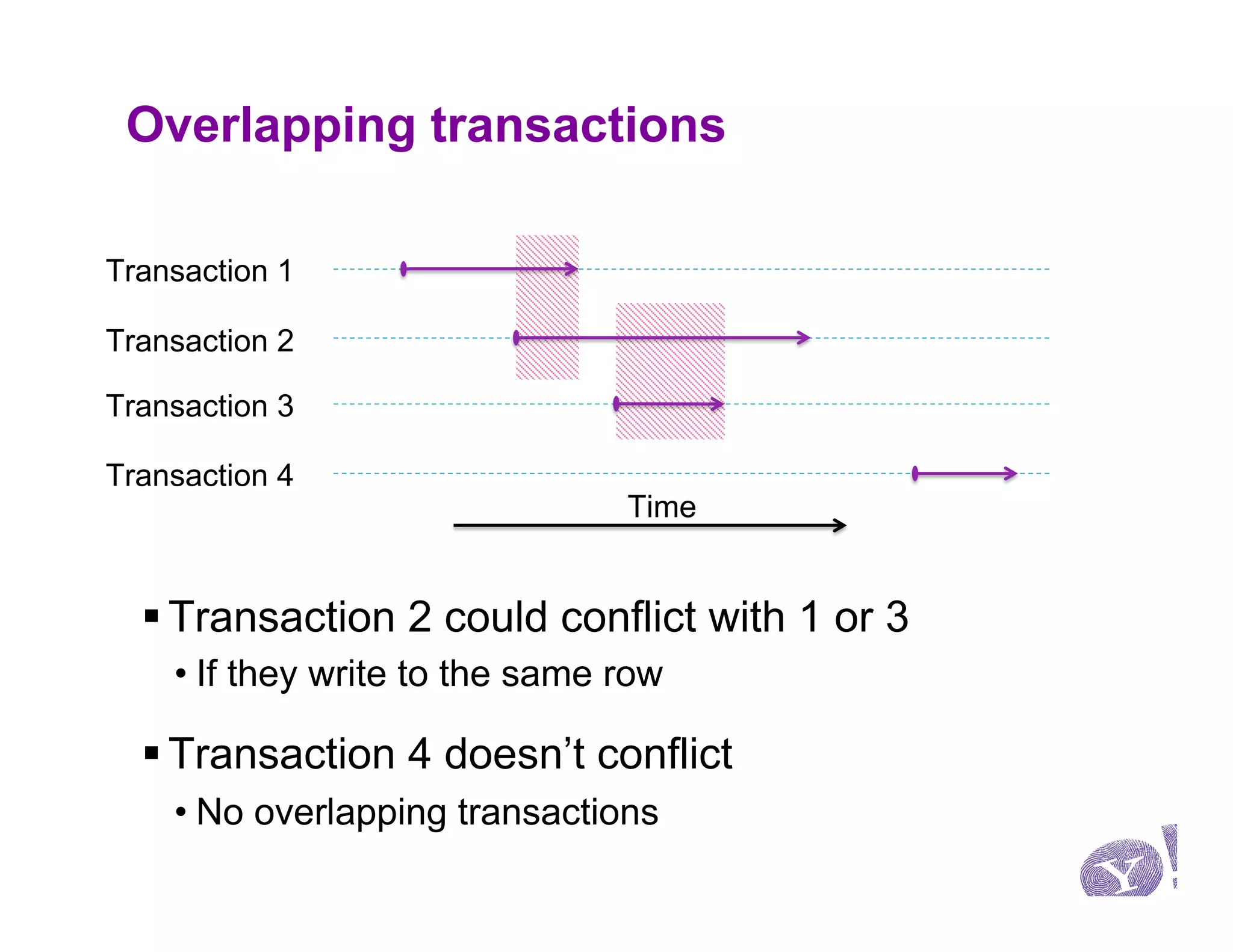


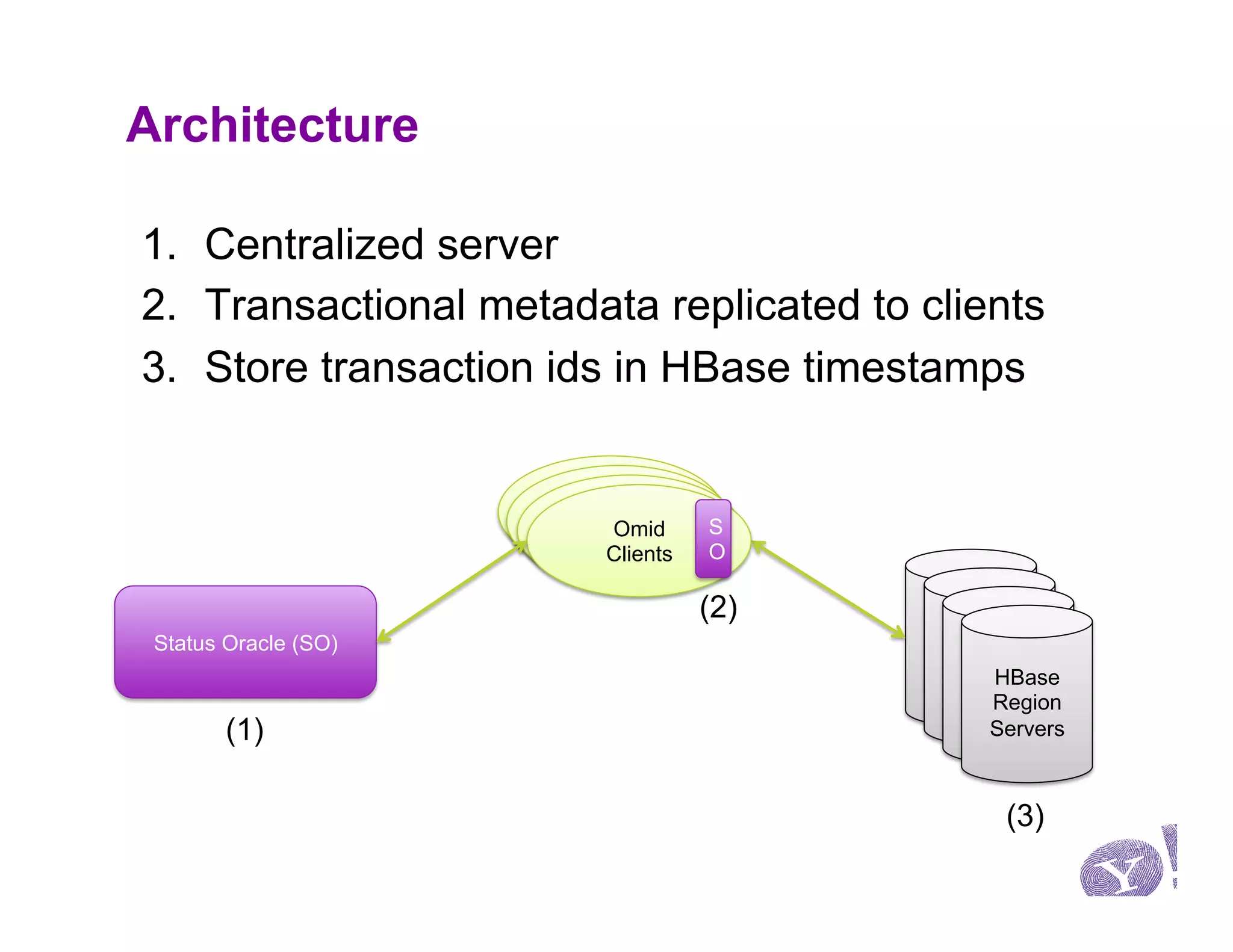
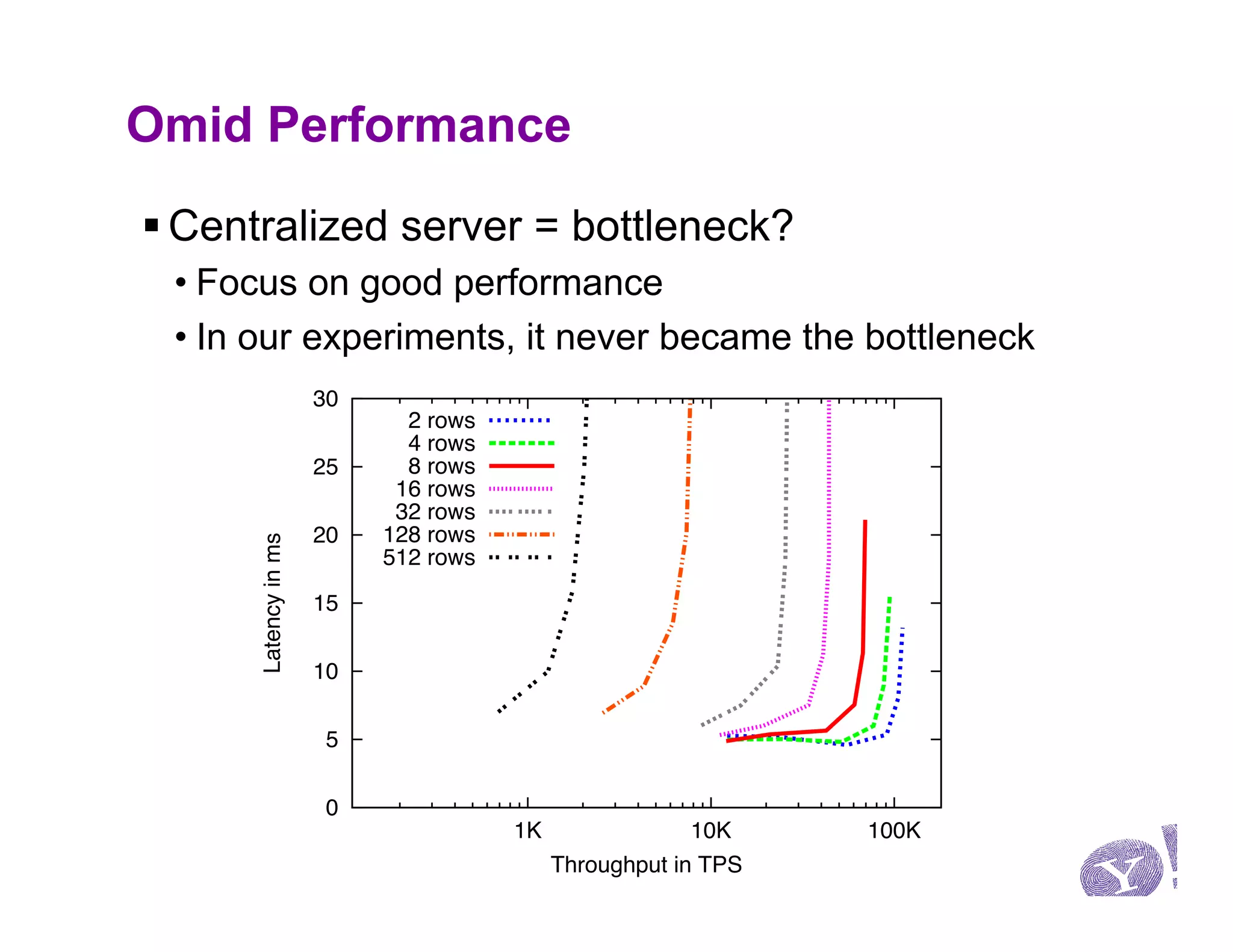


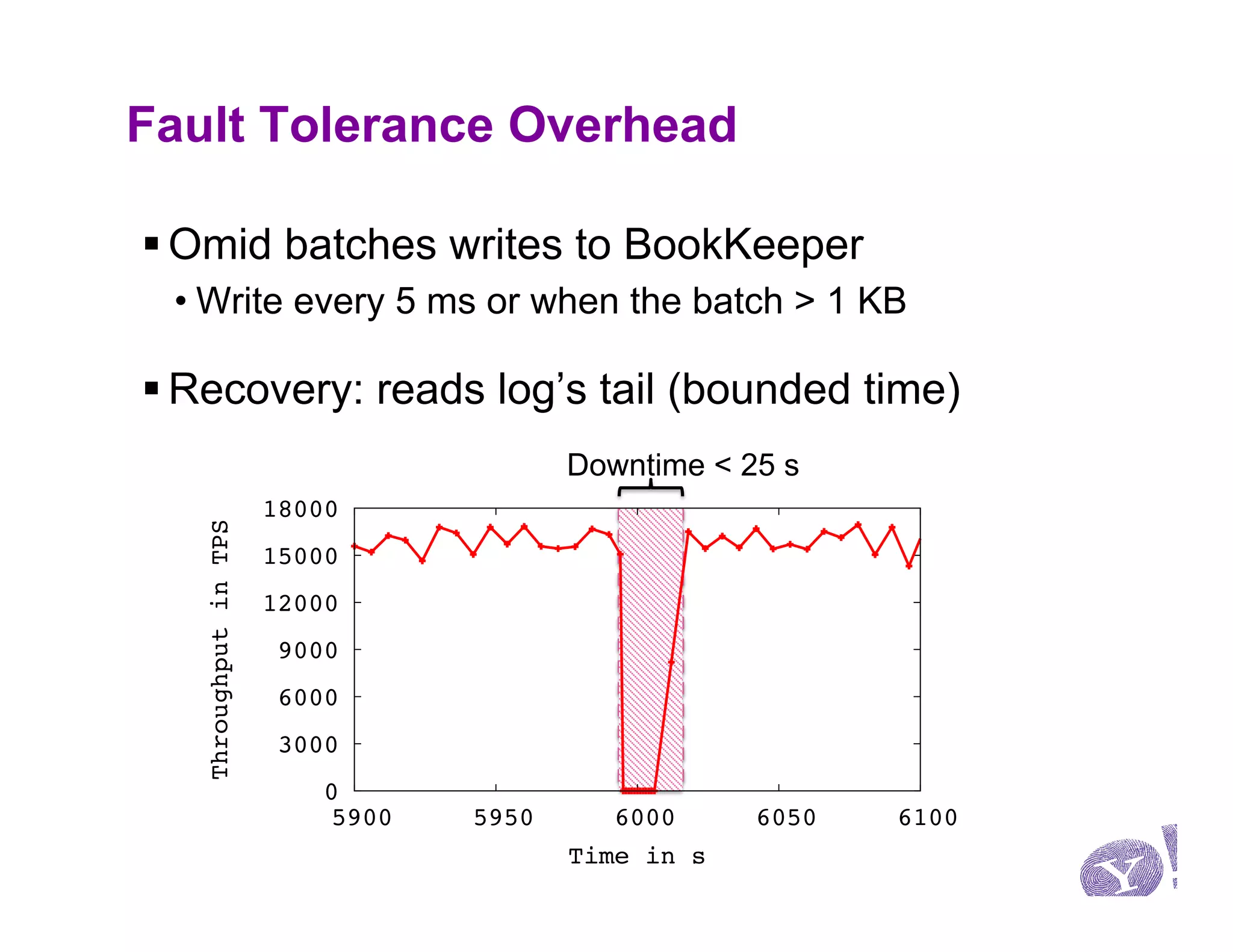









This document discusses Omid, a system for providing efficient transaction management and incremental processing for HBase. Omid implements an optimistic concurrency control model called snapshot isolation without locking. It has a simple API based on Java Transaction API and HBase API. Omid's architecture involves a centralized server for transaction metadata coordination and replication of metadata to HBase clients. It uses BookKeeper for fault tolerance. An example application described is performing TF-IDF indexing of tweets incrementally using Omid transactions.





















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












