2014년 Google Deepmind에서 발표한 Neural Turing Machine에 대한 발표자료입니다.
발표 영상 : https://www.youtube.com/watch?v=J9f6r2EH3ag
블로그 설명 주소 : https://y-rok.github.io/neural-turing-machine
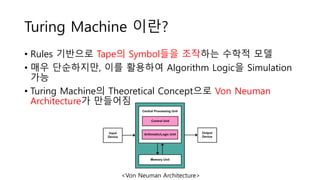
Turing Machine 이란?
•Rules 기반으로 Tape의 Symbol들을 조작하는 수학적 모델
• 매우 단순하지만, 이를 활용하여 Algorithm Logic을 Simulation
가능
• Turing Machine의 Theoretical Concept으로 Von Neuman
Architecture가 만들어짐
<Von Neuman Architecture>
4.
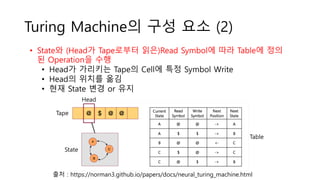
Turing Machine의 구성요소 (1)
• Tape
• Symbol을 Read / Write 가능한 Cell들로 나누어진 공간
• 양방향으로 무한히 Tape를 이어 붙일 수 있다고 가정
• 즉, 무한히 데이터를 저장 가능한 공간
• Head
• Tape에서 특정 Cell을 가리키고 Symbol을 Read / Write 하는 역할
• State Register
• 현재 Turing Machine의 State를 저장
• Table
• Head가 읽은 Symbol과 State에 따른 수행해야 할 Operation 정의
5.
Turing Machine의 구성요소 (2)
출처 : https://norman3.github.io/papers/docs/neural_turing_machine.html
State
Tape
Table
• State와 (Head가 Tape로부터 읽은)Read Symbol에 따라 Table에 정의
된 Operation을 수행
• Head가 가리키는 Tape의 Cell에 특정 Symbol Write
• Head의 위치를 옮김
• 현재 State 변경 or 유지
Head
6.
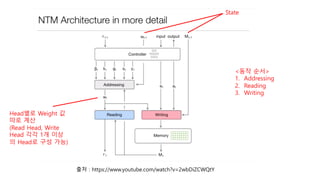
NTM Overview –Concept (1)
• (Turing Machine의 Tape 같은) External Memory 공간을 활용하는
Neural Network
• Differentiable 하므로 Memory addressing, Read, Write 등의
Operation을 Training Dataset을 통해 학습
• RNN의 Hidden state가 Internal memory 같은 역할을 했다면 NTM
은 External memory를 활용
Addressing Mechanism
• 2가지Mechanism을 조합하여 활용
• Focusing by Content
• Memory에 저장된 Data 기반으로 Weight 값 계산
• Transformer, Bahdanau Attention 등에서 활용한 방식
• Focusing by Location
• Memory에 저장된 Data의 위치 기반으로 Weight 값 계산
• Ex) f(x,y)=x+y 를 계산
• x,y를 memory에 저장 했을 때 x,y 값 보다 저장 위치가 중요
Focusing By Contents
Focusing By Location
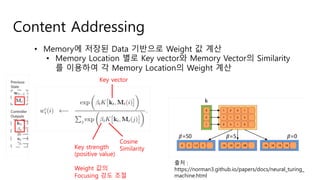
Content Addressing
• Memory에저장된 Data 기반으로 Weight 값 계산
• Memory Location 별로 Key vector와 Memory Vector의 Similarity
를 이용하여 각 Memory Location의 Weight 계산
Key strength
(positive value)
Weight 값의
Focusing 강도 조절
Key vector
Cosine
Similarity
출처 :
https://norman3.github.io/papers/docs/neural_turing_
machine.html
12.
Location Addressing -Interpolation
• Interpolation Gate를 통해 Content-addressing Weight과 이전 time
step을 조합
Interpolation
gate
Content-
addressing으로
얻어진 Weight
이전 time step의
weight
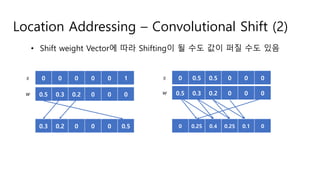
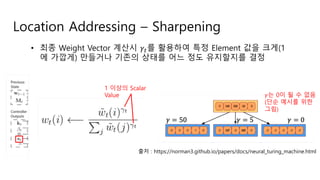
Location Addressing –Sharpening
• 최종 Weight Vector 계산시 !"를 활용하여 특정 Element 값을 크게(1
에 가깝게) 만들거나 기존의 상태를 어느 정도 유지할지를 결정
1 이상의 Scalar
Value !는 0이 될 수 없음
(단순 예시를 위한
그림)
출처 : https://norman3.github.io/papers/docs/neural_turing_machine.html
16.
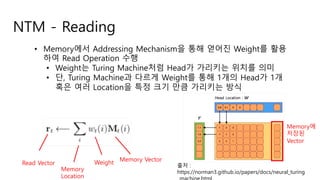
NTM - Reading
WeightReadVector
Memory Vector
• Memory에서 Addressing Mechanism을 통해 얻어진 Weight를 활용
하여 Read Operation 수행
• Weight는 Turing Machine처럼 Head가 가리키는 위치를 의미
• 단, Turing Machine과 다르게 Weight를 통해 1개의 Head가 1개
혹은 여러 Location을 특정 크기 만큼 가리키는 방식
출처 :
https://norman3.github.io/papers/docs/neural_turingMemory
Location
Memory에
저장된
Vector
17.
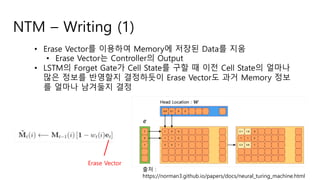
NTM – Writing(1)
• Erase Vector를 이용하여 Memory에 저장된 Data를 지움
• Erase Vector는 Controller의 Output
• LSTM의 Forget Gate가 Cell State를 구할 때 이전 Cell State의 얼마나
많은 정보를 반영할지 결정하듯이 Erase Vector도 과거 Memory 정보
를 얼마나 남겨둘지 결정
Erase Vector
출처 :
https://norman3.github.io/papers/docs/neural_turing_machine.html
Controller Network (1)
•Network 구성 Parameter
• Memory 크기
• Read Head 수, Write Head 수
• Read Head 수 만큼 Read Weight이 생성되고 순차적으로
Read Vector을 생성하여 concat하여 사용
• Write Head 수 만큼 Write Weight, Add Vector, Erase Vector가
생성되고 순차적으로 Memory Write
• Location Shift Range
• Shift range가 1인 경우 !", !$, !%&$값만 학습을 통해 결정됨
• 나머지는 0으로 padding됨
20.
Controller Network (2)
•LSTM 혹은 Feed Forward Network로 구성
• LSTM의 Hidden State는 컴퓨터의 Register와 유사한 역할
• CPU -> Controller
• RAM -> Memory
• Feed Forward Network로 Controller를 구성하더라도 Memory Read /
Write 작업을 통해 Sequence Data 학습 가능
Experiment – Copy(2)
<NTM>
<LSTM>
• Randomized 1~20 Sequence Length, Random Binary Vectors로 Training
• Read, Write head 1개씩 사용
• 학습시 NTM의 수렴 속도가 LSTM의 수렴 속도 보다 빠름
• Sequence Length 10, 20, 30, 50, 120에 대하여 Network Output 비교 시 LSTM은
20 이상의 Sequence Length에 대해 Output이 부정확
• NTM은 Longer sequence 학습 가능
23.
Experiment – Copy(3)
• Location-Addressing
• (Previous Weight 값에서 Shift하면서) Iteration을 통해 Read /
Write
• Content-Addressing
• Memory에 저장된 Start Delimeter를 활용하여 Start Location으로
Head를 이동
Input을 받아서
Memory에 적음
Output을 받아서
Memory에 적음
• Iteration을 통해
Write 한 위치에서
Read
• Sharpening을 통해
1개의 위치에 접근
24.
Experiment – PrioritySort
• Priority(Scalar)와 20 binary vectors를 받아 Priority 순으로 정렬
• Best Performance를 위해 각각 8개 Read / Write Head(+Feed
Forward Network) 필요
• Sorting은 Unary Vector Operation으로 학습하기 어려운 것으로
판담됨
• Sorting Algorithm이 어떤식으로 학습되었는지는 논문에 언급되어
있지 않음
Input의 Location이 Priority
값의 특정 Linear Function
실제 write weightings이
Linear Function의 결과와
유사
25.
Conclusion
• External Memory공간을 활용
• LSTM 보다 Long Sequence Data 특성을 잘 학습함
• Memory 접근 시 Content-Addressing과 Location-Addressing을 조합
하여 활용
• Memory Network는 Content-Addressing과 유사한 방법만을 활용
• Memory에 Read 뿐만 아니라 Write Operation도 수행
• Task에 따라 적합한 위치에 데이터 저장 (ex)Priority Sort)
• Multiple Head를 활용하여 Memory Vector의 Multiple transform 가
능
• Priority Sort의 경우 알고리즘 학습에 Multiple Head 활용
26.
Future seminar
• Few-ShotGeneralization Across Dialogue Tasks
• 대화시스템 플랫폼 RASA의 NeurIPS Paper 2018
• 대화 처리(Dialogue Management)에 관한 논문
• NTM 관한 논문




![NTM Overview – Copy Task
출처 : https://medium.com/@benjamin_47408/neural-turing-
machines-an-artificial-working-memory-cd913420508b
NTM
• Previous Read Vector
• (LSTM의 경우 Previous
Hidden State)
• Previous weight
External
Input
External Output
• Binary Target으로
Supervised Learning
• Binary Vector + Delimeter
로 Input 구성
• Ex) 12
• [0,0,0,0,1,1,0,0,0,0]
Number
Delimeter
(start, end)](https://image.slidesharecdn.com/neuralturingmachine-190204070912/85/Neural-turing-machine-7-320.jpg)







![Experiment – Copy (1)
출처 : https://medium.com/@benjamin_47408/neural-turing-
machines-an-artificial-working-memory-cd913420508b
NTM
• Previous Read Vector
• (LSTM의 경우 Previous
Hidden State)
• Previous weight
External
Input
External Output
• Binary Target으로
Supervised Learning
• Binary Vector + Delimeter
로 Input 구성
• Ex) 12
• [0,0,0,0,1,1,0,0,0,0]
Number
Delimeter
(start, end)](https://image.slidesharecdn.com/neuralturingmachine-190204070912/85/Neural-turing-machine-21-320.jpg)





![[Unite17] 유니티에서차세대프로그래밍을 UniRx 소개 및 활용](https://cdn.slidesharecdn.com/ss_thumbnails/track3final-170516155658-thumbnail.jpg?width=640&height=640&fit=bounds)




![[160402_데브루키_박민근] UniRx 소개](https://cdn.slidesharecdn.com/ss_thumbnails/160402unirx-160403045953-thumbnail.jpg?width=640&height=640&fit=bounds)



![[222]neural machine translation (nmt) 동작의 시각화 및 분석 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222neuralmachinetranslationnmt-171016102621-thumbnail.jpg?width=640&height=640&fit=bounds)





![[224] backend 개발자의 neural machine translation 개발기 김상경](https://cdn.slidesharecdn.com/ss_thumbnails/224backendneuralmachinetranslation-161025025107-thumbnail.jpg?width=640&height=640&fit=bounds)
![[신경망기초] 심층신경망개요](https://cdn.slidesharecdn.com/ss_thumbnails/nn10-180318142325-thumbnail.jpg?width=640&height=640&fit=bounds)









![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)
![[기초개념] Recurrent Neural Network (RNN) 소개](https://cdn.slidesharecdn.com/ss_thumbnails/agistpurnndkim190430-190430140949-thumbnail.jpg?width=640&height=640&fit=bounds)