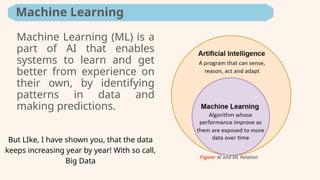
Machine Learning (ML)is a
part of AI that enables
systems to learn and get
better from experience on
their own, by identifying
patterns in data and
making predictions.
Machine Learning
Figure: AI and ML Relation
But LIke, I have shown you, that the data
keeps increasing year by year! With so call,
Big Data
2.OBJECT
IVE
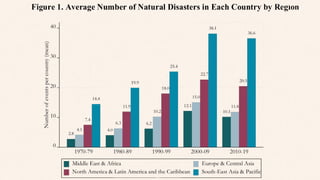
• enhance naturaldisasters prediction
with more accurate result with
longer duration before the disaster
occurs.
• Human can be well prepared before
the disaster.
• It can save millions of lives one earth
from tragical natural disasters.
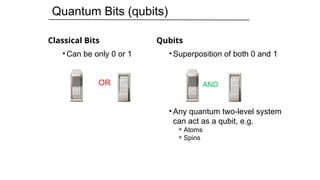
Classical Bits
• Canbe only 0 or 1
OR
Qubits
• Superposition of both 0 and 1
• Any quantum two-level system
can act as a qubit, e.g.
⚬Atoms
⚬Spins
Quantum Bits (qubits)
AND
22.
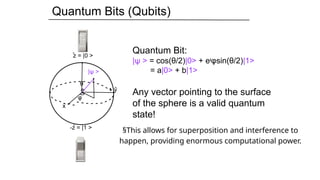
Quantum Bits (Qubits)
z= |0 >
-z = |1 >
x
y
θ
φ
|ψ >
ˆ
ˆ
ˆ
ˆ
Quantum Bit:
|ψ > = cos(θ/2)|0> + e φsin(θ/2)
ᶦ |1>
= a|0> + b|1>
Any vector pointing to the surface
of the sphere is a valid quantum
state!
§This allows for superposition and interference to
happen, providing enormous computational power.
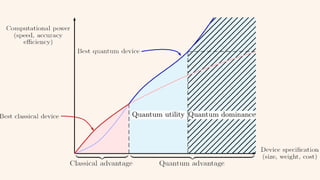
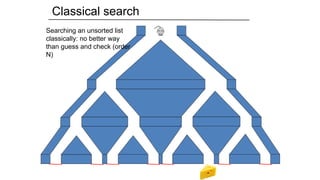
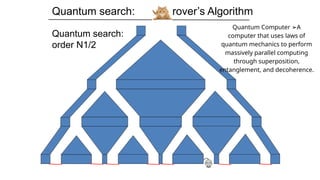
Quantum search: Grover’sAlgorithm
Quantum search:
order N1/2
Quantum Computer A
➢
computer that uses laws of
quantum mechanics to perform
massively parallel computing
through superposition,
entanglement, and decoherence.
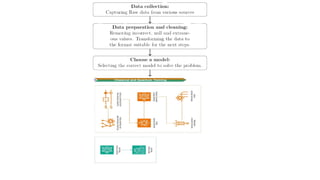
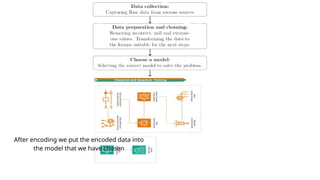
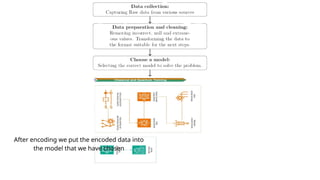
After encoding weput the encoded data into
the model that we have chosen
33.
Support Vector Machines:Slide <number>
Linear Classifiers
f
x
yᵉˢᵗ
denotes +1
denotes -1
f(x,w,b) = sign(w. x - b)
How would you
classify this data?
34.
Support Vector Machines:Slide <number>
Linear Classifiers
f
x
yᵉˢᵗ
denotes +1
denotes -1
f(x,w,b) = sign(w. x - b)
How would you
classify this data?
35.
Support Vector Machines:Slide <number>
Linear Classifiers
f
x
yᵉˢᵗ
denotes +1
denotes -1
f(x,w,b) = sign(w. x - b)
How would you
classify this data?
36.
Support Vector Machines:Slide <number>
Linear Classifiers
f
x
yᵉˢᵗ
denotes +1
denotes -1
f(x,w,b) = sign(w. x - b)
Any of these
would be fine..
..but which is
best?
37.
Support Vector Machines:Slide <number>
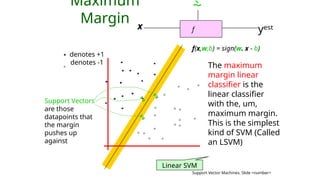
Maximum
Margin
f
x
yᵉˢᵗ
denotes +1
denotes -1
f(x,w,b) = sign(w. x - b)
The maximum
margin linear
classifier is the
linear classifier
with the, um,
maximum margin.
This is the simplest
kind of SVM (Called
an LSVM)
Support Vectors
are those
datapoints that
the margin
pushes up
against
Linear SVM
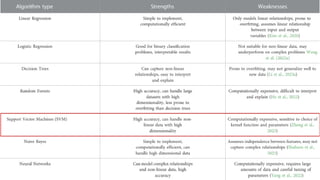
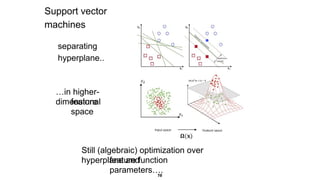
Lastly, by usinga technique known as kernel trick, SVM can
separate data which is not linearly separable in its input
space. This technique enables SVM to transform input data
into higher-dimen- sional space, where a separating linear
hyperplane can be found.
40.
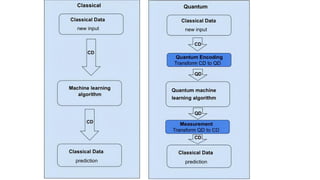
After encoding weput the encoded data into
the model that we have chosen
CONCLUSION
Further research inthe future:
• This research can be fully
applied once quantum
computers are fully developed.
• Update this research by
making the prediction to
process more faster and more
accurate .








































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


