Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
itoyan110
1,062 views
NagoyaStat #5 ご挨拶と前回の復習
NagoyaStat #5の開始に先立ち、GLMMとMCMCの手法の一つであるメトロポリス法について20分程度で復習しました。
Science
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 19
2
/ 19
3
/ 19
4
/ 19
5
/ 19
6
/ 19
7
/ 19
8
/ 19
9
/ 19
10
/ 19
11
/ 19
12
/ 19
13
/ 19
14
/ 19
15
/ 19
16
/ 19
17
/ 19
18
/ 19
19
/ 19
More Related Content
PDF
Chapter7 回帰分析の悩みどころ
by
itoyan110
PDF
NagoyaStat #4 ご挨拶と前回の復習
by
itoyan110
PDF
なめるな!plot
by
itoyan110
PDF
データ解析のための統計モデリング入門 1~2章
by
itoyan110
PDF
Rで確認しながら解く統計検定2級
by
itoyan110
PDF
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2017
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2021
by
itoyan110
Chapter7 回帰分析の悩みどころ
by
itoyan110
NagoyaStat #4 ご挨拶と前回の復習
by
itoyan110
なめるな!plot
by
itoyan110
データ解析のための統計モデリング入門 1~2章
by
itoyan110
Rで確認しながら解く統計検定2級
by
itoyan110
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
このIRのグラフがすごい!上場企業2017
by
itoyan110
このIRのグラフがすごい!上場企業2021
by
itoyan110
What's hot
PDF
このIRのグラフがすごい!上場企業2018
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2019
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2016
by
itoyan110
PDF
Rでノンパラメトリック法 1
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2015
by
itoyan110
PDF
コイン投げの分析を一捻り (Japan.R 2013 LT)
by
itoyan110
PPTX
Excelを使って学ぶ、統計の基礎
by
webcampusschoo
PDF
35thwebmining_lt
by
Daisuke Amano
PDF
絶対に描いてはいけないグラフ入りスライド24枚
by
itoyan110
PDF
相互運用可能な知的活動測定システムの研究
by
yamahige
PPTX
Bi&データ可視化ツール@tokyowebmining35
by
智明 高松
PPTX
Kandai R 入門者講習
by
考司 小杉
PDF
Kandai.R #1 公開用
by
Daisuke Nakanishi
PPTX
心理統計の課題をRmdで作る
by
考司 小杉
PDF
RでTwitterテキストマイニング
by
Yudai Shinbo
このIRのグラフがすごい!上場企業2018
by
itoyan110
このIRのグラフがすごい!上場企業2019
by
itoyan110
このIRのグラフがすごい!上場企業2016
by
itoyan110
Rでノンパラメトリック法 1
by
itoyan110
このIRのグラフがすごい!上場企業2015
by
itoyan110
コイン投げの分析を一捻り (Japan.R 2013 LT)
by
itoyan110
Excelを使って学ぶ、統計の基礎
by
webcampusschoo
35thwebmining_lt
by
Daisuke Amano
絶対に描いてはいけないグラフ入りスライド24枚
by
itoyan110
相互運用可能な知的活動測定システムの研究
by
yamahige
Bi&データ可視化ツール@tokyowebmining35
by
智明 高松
Kandai R 入門者講習
by
考司 小杉
Kandai.R #1 公開用
by
Daisuke Nakanishi
心理統計の課題をRmdで作る
by
考司 小杉
RでTwitterテキストマイニング
by
Yudai Shinbo
More from itoyan110
PDF
このIRのグラフがすごい!上場企業2024 (The graph on this IR is amazing! Listed companies in J...
by
itoyan110
PDF
Reviewing Let's Note CF-FV3 (レッツノート CF-FV3 をレビューする)
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2023
by
itoyan110
PDF
このIRのグラフがすごい!上場企業2020
by
itoyan110
PDF
Chapter9 一歩進んだ文法(前半)
by
itoyan110
PDF
2018年6月期 統計検定2級&準1級 対策スライド
by
itoyan110
PDF
レッツノートを業務用途にカスタマイズする
by
itoyan110
PDF
Rの拡張を書く (R 2.15.2)
by
itoyan110
PDF
Rで実験計画法 後編
by
itoyan110
PDF
Rで実験計画法 前編
by
itoyan110
このIRのグラフがすごい!上場企業2024 (The graph on this IR is amazing! Listed companies in J...
by
itoyan110
Reviewing Let's Note CF-FV3 (レッツノート CF-FV3 をレビューする)
by
itoyan110
このIRのグラフがすごい!上場企業2023
by
itoyan110
このIRのグラフがすごい!上場企業2020
by
itoyan110
Chapter9 一歩進んだ文法(前半)
by
itoyan110
2018年6月期 統計検定2級&準1級 対策スライド
by
itoyan110
レッツノートを業務用途にカスタマイズする
by
itoyan110
Rの拡張を書く (R 2.15.2)
by
itoyan110
Rで実験計画法 後編
by
itoyan110
Rで実験計画法 前編
by
itoyan110
NagoyaStat #5 ご挨拶と前回の復習
1.
NagoyaStat #5 ご挨拶と前回の復習 @ito_yan E-mail: 1mail2itoh3
[at] gmail.com 2017.04.07 NagoyaStat #5
2.
今回の内容 • ご挨拶と前回の復習 • 参加者による自己紹介 •
「データ解析のための統計モデリング入門」 • 第9章 tmkz.it 様 • 第10章 nishioka0902 様 2
3.
主催者について • TwitterID: @ito_yan •
ITインフラ屋さん • 仮想サーバ(構築、運用) • Javaアプリケーション開発 • 最近はドメイン移行に伴うメール移行とか • 小規模ネットワーク構築 3
4.
勉強会で取り上げる書籍について • 「データ解析のための統計モデリング入門」 • 通称:緑本 •
農学系のデータを扱っているが、農学系以外の 分野でも適用可能なことを扱っている 4
5.
第7章の復習 • 第3章や第6章でみた回帰は、現実のデータモデ リングへの適用が難しい • カウントデータのばらつきがポアソン分布や二項分 布「だけ」ではうまく説明できないことが多い •
説明変数が同じなら平均も同じになるというGLMの 仮定は、生物データには当てはまらないのが普通 • 第7章では測定できない個体差(原因不明の差 異)を組み込んだGLMであるGLMMが登場した 5
6.
問題設定 • 植物の各個体から8個の種子をとってきて、いくつ 生存しているかを調べる • 生存種子数が葉数と共に増大するかを調べたい •
葉数は2~6とし、各葉数で20個体を調査する 6 何となく葉数が増えると、 生存している種子数は増 えているように見えるが…
7.
一般化線形混合モデル(GLMM) • 通常のロジスティック回帰はうまくいかない • 推定すると、真の傾きに近い結果が得られない •
そもそもデータは二項分布に従っていない • X=4の箇所は特にその傾向が強い • 観測できない個体差や場所差の影響を組み込ん だ統計モデリングが必要となる • 生物的な要因(遺伝子、経験の相違) • 非生物的な要因(栄養・水・光など環境の違い) • 原因不明の個体差や場所差の効果をGLMに組 み込んだ統計モデルをGLMMと呼んでいる 7
8.
GLMMのモデル • 3項目に原因不明の効果をいれておく • 正規分布を選ぶ根拠はない •
そもそも個体差は観測不可なので分布も不明 • 統計モデリングに便利という程度で選ばれている • 単純化のため、個体差は相互に独立とする • 最初の2項は固定効果、最後の項はランダム効 果、それらを合わせると混合モデルと呼ばれる 8 sは集団内のばらつきを表す
9.
GLMMの最尤推定 • 個体差をすべて推定するのは無理がある • 各個体の尤度は次式で与えられる •
個体差を標準偏差に置き換えるのがキモ • 各個体の尤度は3つのパラメータで書ける • 全体の尤度は で与えられ るので、ここからパラメータを推定することになる →RのGLMM関数を用いる 9
10.
GLMMの実行コード • 教科書のコードそのままでは動かないので注意 10
11.
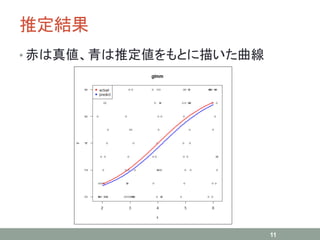
推定結果 • 赤は真値、青は推定値をもとに描いた曲線 11
12.
GLMMが必要な状況とは? • 擬似反復が含まれているかで決まる • 1個体から複数データをとることで、個体差の推定 ができるため、モデルの中で個体差を組み込む必 要が出てくる •
個体差を考えないと過分散のようなことになる • 逆に1個体に1つしかデータが得られない場合、 個体差の推定はやりようがない • この場合は個体差を考えないGLMで推定する 12
13.
第8章 • 考慮しなければならない誤差の原因(ランダム効 果)が増える • ランダム効果の発生源の数だけ多重積分が発生 するため、計算ができなくなるという問題が発生 •
MCMC(マルコフ連鎖モンテカルロ法)により、パ ラメータの分布を得る • 点推定ではなく、分布の形で得る 13
14.
第8章の例題 • 第6章6.2節の例題(上限のあるカウントデータ)と 同じように20個体の植物から種子8個を得て、そ の生死を調べる • 各植物は均質で、生存数は二項分布に従うとす ると、ある個体iの種子数が
である確率は • 尤度は あとはLの対数をとってをqで微分してやればよく、 最尤推定量は種子数の平均で与えられる 14
15.
ふらふらした最尤推定 • では、(第7章の積分が複雑になる場合のように) 最尤推定で解析的にパラメータが求まらないケー スはどう対応するか? • qを離散化(qは0~1で0.01刻み) •
ある値からスタートし • ランダムに隣接するqを選び • 対数尤度が高ければそちらに移動する • すると、例題においてはqの値の最尤推定値に向 かって移動していく 15
16.
メトロポリス法 • ランダムに隣接するqを選んで尤度が小さくなる 場合でも、確率 でそちらの方 に移動させる •
ふらふらした最尤推定の拡張 • メトロポリス法は直前のステップのみで新しい状 態を作り出し(マルコフ連鎖)、また隣接するqの 選択にランダム性がある(モンテカルロ法)ので、 MCMCと呼ばれるアルゴリズムの一種である 16
17.
定常分布 • メトロポリス法でqが変化すると、qの値で作るヒス トグラムがある確率分布に近づいていき、その分 布は定常分布と呼ばれる • 例題のqは初期値によらず定常分布に近づく •
詳細釣り合いの条件を満たしているため • qの値の最初に得られたサンプルは初期値に依存 したものなので、定常分布には含めない • 良いMCMCアルゴリズムは1ステップ間でサンプ ルされた値の相関が低いアルゴリズムである • 直前の値を引きずらず、定常分布が早く作れる 17
18.
最尤推定とベイズ統計の違い • 最尤推定は頻度主義のやりかたであり、パラメー タはある定数であるという考え方である • ベイズ統計は推定したいパラメータを確率分布で 表現するため、定常分布(MCMC)との親和性が 高い 18
19.
ベイズ統計モデル • ベイズの定理を変形していく • 事後分布は尤度と事前分布の積に比例 •
パラメータは分布の形で推定されるので、最尤推 定法のように1つの値では決まらない • 事前分布が定数なら単に尤度に比例する 19 分母はqに依存しない
Download
![NagoyaStat #5
ご挨拶と前回の復習
@ito_yan
E-mail: 1mail2itoh3 [at] gmail.com
2017.04.07
NagoyaStat #5](https://image.slidesharecdn.com/nagoyastat5greeting-170502141024/85/NagoyaStat-5-1-320.jpg)
![NagoyaStat #5
ご挨拶と前回の復習
@ito_yan
E-mail: 1mail2itoh3 [at] gmail.com
2017.04.07
NagoyaStat #5](https://image.slidesharecdn.com/nagoyastat5greeting-170502141024/75/NagoyaStat-5-1-2048.jpg)