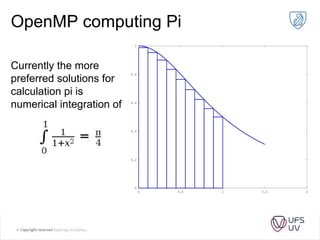
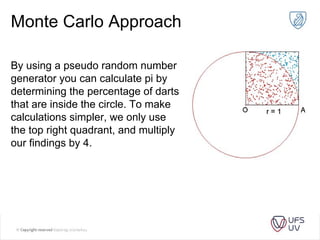
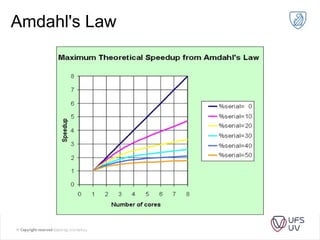
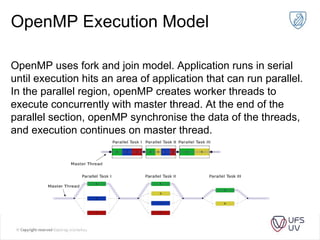
This document discusses the progression of multi-core processors from dual-core to octa-core CPUs over recent years. It then provides an overview of parallel programming with OpenMP, including its advantages, execution model, data sharing rules, and examples of parallelizing a for loop and calculating Pi in parallel.










![OpenMP example
For-loop with independent
iterations
For-loop parallelized using
OpenMP
for (int i=0; i < n;
i++)
c[i] = a[i] + b[i];
#pragma omp parallel
for
for (int i=0; i < n;
i++)
c[i] = a[i] + b[i];](https://image.slidesharecdn.com/4d61aaa0-e898-4621-8595-b23eca3b8e50-161123154425/85/Multi-Processor-computing-with-OpenMP-13-320.jpg)