Downloaded 26 times






![A couple of eclipse tips
• <ctrl>-F : search text in file, replace; regular expressions possible,
• <ctrl>-J + word : search text in file, without opening a popup,
• <ctrl>-R + filena : jump to the given filename directly. If multiple files
correspond to the name entered, they are proposed,
• select text + <ctrl>-7 [ right button -> source -> toggle comment] :
passed the whole selection in or out comment mode (prepend // to lines)](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-6-320.jpg)







![Groovy truth (cont’d)
In Groovy, several condition produce false (and opposite produces true)
assert !false //boolean value
assert !(‘a’ =~ /b/) //regular expression
assert ![] //empty list
assert ![:] //empty map
assert !‘‘ //empty string
assert !0 //zero
assert !null //null pointer
assert true
assert a=~/./
assert [1]
assert [a:1]
assert ‘my funny valentine’
assert 1
assert new Object()](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-14-320.jpg)






![Single line conditional statement (cont’d)
Imagine we want to sort elements on last name, and if they are equals, on
the first name
def nameList=[[first:'Harry', last:'Potter'], [first:'Ron',
last:'Weasley'], [first:'Fred', last:'Weasley'], [first:'Georges', last:'Weasley'], , [first:'Hermione', last:'Granger'] ]](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-21-320.jpg)
![Single line conditional statement (cont’d)
Imagine we want to sort elements on last name, and if they are equals, on
the first name
def nameList=[[first:'Harry', last:'Potter'], [first:'Ron',
last:'Weasley'], [first:'Fred', last:'Weasley'], [first:'Georges', last:'Weasley'], , [first:'Hermione', last:'Granger'] ]
The first “long” way:
nameList.sort{o1, o2 ->
if(o1.last == o2.last){
return o1.first <=> o2.first // <=> the spaceship
}else{ // operator
return o1.last <=> o2.last // compares elements
}
}.each{println “$it.first $it.last”}](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-22-320.jpg)
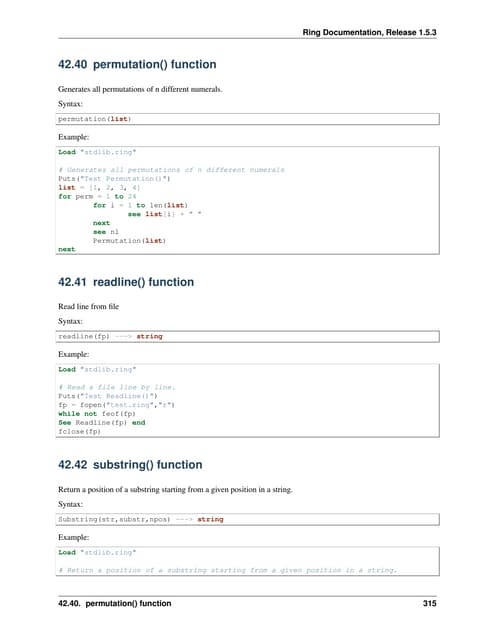
![Single line conditional statement (cont’d)
Imagine we want to sort elements on last name, and if they are equals, on
the first name
def nameList=[[first:'Harry', last:'Potter'], [first:'Ron',
last:'Weasley'], [first:'Fred', last:'Weasley'], [first:'Georges', last:'Weasley'], , [first:'Hermione', last:'Granger'] ]
The first “long” way:
nameList.sort{o1, o2 ->
if(o1.last == o2.last){
return o1.first <=> o2.first // <=> the spaceship
}else{ // operator
return o1.last <=> o2.last // compares elements
}
}.each{println “$it.first $it.last”}
Or the more compact manner:
(o1.last <=> o2.last)?:(o1.first <=> o2.first)](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-23-320.jpg)
![While loop
while(cond) is evaluated until the condition is false
List l=[]
x=5
while(x--){
l << x
}
assert l == [4, 3, 2, 1, 0]](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-24-320.jpg)
![While loop
while(cond) is evaluated until the condition is false
List l=[]
x=5
while(x--){
l << x
}
assert l == [4, 3, 2, 1, 0]
A loop scope can be exited with a break
List l=[]
x=5
while(x--){
l << x
if(x==3) break // NB a single line statement, no {}
}
assert l == [4, 3]](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-25-320.jpg)
![Loop: breaking the flow (cont’d)
It can be useful to jump directly to the next iteration, without evaluation the
remaining part of the loop, with the continue statement
int x = 10
def list=[]
while(x--){
if (x%2) continue // return to the while evaluation
if (x<4) break // exit
list << x
}
assert list == [8, 6, 4]](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-26-320.jpg)



















![regexp: character classes
assert ‘The Lord’ =~ /L.rd/ // . matches any character
assert ‘The Lord’ =~ /L..d/
assert ! ‘The Lord’ =~ /.The/
assert ‘The Lord’ =~ /L[eoi]rd/ //character set
assert ‘The Lord’ =~ /L[A-Za-z0-9]rd/
assert ’12:23:56’ =~ /[0-2][0-9]:[0-5][0-9]:[0-5][0-9]/](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-46-320.jpg)
![regexp: character classes
assert ‘The Lord’ =~ /L.rd/ // . matches any character
assert ‘The Lord’ =~ /L..d/
assert ! ‘The Lord’ =~ /.The/
assert ‘The Lord’ =~ /L[eoi]rd/ //character set
assert ‘The Lord’ =~ /L[A-Za-z0-9]rd/
assert ’12:23:56’ =~ /[0-2][0-9]:[0-5][0-9]:[0-5][0-9]/
assert ‘12_;45’ ==~ /[^a-z]*/ //anything but [a-z]](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-47-320.jpg)
![regexp: character classes
assert ‘The Lord’ =~ /L.rd/ // . matches any character
assert ‘The Lord’ =~ /L..d/
assert ! ‘The Lord’ =~ /.The/
assert ‘The Lord’ =~ /L[eoi]rd/ //character set
assert ‘The Lord’ =~ /L[A-Za-z0-9]rd/
assert ’12:23:56’ =~ /[0-2][0-9]:[0-5][0-9]:[0-5][0-9]/
assert ‘12_;45’ ==~ /[^a-z]*/ //anything but [a-z]
assert ‘1234’ ==~ /d+/ //any digit
assert ! ‘1234’ =~ /D/ //anything but digit
assert ‘The_12_ring’ ==~ /w/ //word char [a-zA-Z0-9_]
assert ! ‘The_12_ring’ =~ /W/ //non-word char
assert ‘of the Rings =~ /ofsth //space char [ trnf]](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-48-320.jpg)

















![regexp: looking around
Regular expression usually consume character
Let’s consider cleaving a protein sequence with trypsin
‘ACDEFKPGHRILKM’ =~/(w+?[KR])[^P]/ // the I is consumed](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-66-320.jpg)
![regexp: looking around
Regular expression usually consume character
Let’s consider cleaving a protein sequence with trypsin
‘ACDEFKPGHRILKM’ =~/(w+?[KR])[^P]/ // the I is consumed
If the next amino acid is consumed, it will not be caught in a situation where
we want to capture all the matches of the regular expression](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-67-320.jpg)
![regexp: looking around
Regular expression usually consume character
Let’s consider cleaving a protein sequence with trypsin
‘ACDEFKPGHRILKM’ =~/(w+?[KR])[^P]/ // the I is consumed
If the next amino acid is consumed, it will not be caught in a situation where
we want to capture all the matches of the regular expression
Hopefully, we can ‘lookahead’
‘ACDEFKPGHRILKM’ =~/(w+?[KR])(?=[^P])/](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-68-320.jpg)
![regexp: looking around
Regular expression usually consume character
Let’s consider cleaving a protein sequence with trypsin
‘ACDEFKPGHRILKM’ =~/(w+?[KR])[^P]/ // the I is consumed
If the next amino acid is consumed, it will not be caught in a situation where
we want to capture all the matches of the regular expression
Hopefully, we can ‘lookahead’
‘ACDEFKPGHRILKM’ =~/(w+?[KR])(?=[^P])/
Respectively, it is possible to check is a regexp matches before the captured
string (look behind)
(?<=...)](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-69-320.jpg)

![regexp at works : splitting a string
One of the most commons use of the regular expression is to split a string
into an array
Splitting point can be defined by a regular expression
assert “a b c d”.split(/s+/)==[‘a’, ‘b’, ‘c’, ‘d’]](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-71-320.jpg)
![regexp at works : splitting a string
One of the most commons use of the regular expression is to split a string
into an array
Splitting point can be defined by a regular expression
assert “a b c d”.split(/s+/)==[‘a’, ‘b’, ‘c’, ‘d’]
An extra argument can be passed, to limit the number of elements in the
returned list
assert “a b c d”.split(/s+/, 3)==[‘a’, ‘b’, ‘c d’]](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-72-320.jpg)
![regexp at works : splitting a string
One of the most commons use of the regular expression is to split a string
into an array
Splitting point can be defined by a regular expression
assert “a b c d”.split(/s+/)==[‘a’, ‘b’, ‘c’, ‘d’]
An extra argument can be passed, to limit the number of elements in the
returned list
assert “a b c d”.split(/s+/, 3)==[‘a’, ‘b’, ‘c d’]
Do not forget to pipe to an collect closure
assert “0 1 2”.split(/s+/).collect{it as Integer}](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-73-320.jpg)
![regexp at works : splitting a string
One of the most commons use of the regular expression is to split a string
into an array
Splitting point can be defined by a regular expression
assert “a b c d”.split(/s+/)==[‘a’, ‘b’, ‘c’, ‘d’]
An extra argument can be passed, to limit the number of elements in the
returned list
assert “a b c d”.split(/s+/, 3)==[‘a’, ‘b’, ‘c d’]
Do not forget to pipe to an collect closure
assert “0 1 2”.split(/s+/).collect{it as Integer}
Or use splitEachLine
txt.splitEachLine(/regexp/){it.action}](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-74-320.jpg)
![regexp: loop across matches
All the occurrence of a match is returned into a list:
String title = "The Lord of the Rings"
assert (title=~/(?i)thes+w+/).collect{"<$it>"} ==
[‘<The Lord>’, ‘<the Rings>’]](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-75-320.jpg)
![regexp: loop across matches
All the occurrence of a match is returned into a list:
String title = "The Lord of the Rings"
assert (title=~/(?i)thes+w+/).collect{"<$it>"} ==
[‘<The Lord>’, ‘<the Rings>’]
It is also natural to loop across all such occurrences:
(title=~/(?i)thes+w+/).each{println "<$it>"}](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-76-320.jpg)
![regexp: loop across matches
All the occurrence of a match is returned into a list:
String title = "The Lord of the Rings"
assert (title=~/(?i)thes+w+/).collect{"<$it>"} ==
[‘<The Lord>’, ‘<the Rings>’]
It is also natural to loop across all such occurrences:
(title=~/(?i)thes+w+/).each{println "<$it>"}
Is equivalent to
title.eachMatch(/(?i)thes+w+/){println "<$it>"}](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-77-320.jpg)

![regexp: capturing
Like in perl, it is possible to define with parenthesis sub patterns to be
captured in the pattern
If such parenthesis are present, the java.util.regex.Matcher structure
returned is different
def matcher = title=~/(?i)thes+(w+)/
assert matcher.hasGroup()
assert matcher[0][0] == ‘The Lord’ //the whole match
assert matcher[0][1] == ‘Lord‘ //first captured block](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-79-320.jpg)
![regexp: capturing
Like in perl, it is possible to define with parenthesis sub patterns to be
captured in the pattern
If such parenthesis are present, the java.util.regex.Matcher structure
returned is different
def matcher = title=~/(?i)thes+(w+)/
assert matcher.hasGroup()
assert matcher[0][0] == ‘The Lord’ //the whole match
assert matcher[0][1] == ‘Lord‘ //first captured block
It is possible to loop around with a closure
(title=~/(?i)thes+(w+)/).each{all, name ->
println "all: <$all>, capt:<$name>"
}](https://image.slidesharecdn.com/mpb-eop-lec3-100601115625-phpapp02/85/groovy-grails-lecture-3-80-320.jpg)

This document is a lecture note from a course on Groovy programming, focusing on efficiency-oriented programming, including control structures, regular expressions, and basic Groovy syntax. It provides tips for using the Eclipse IDE, Linux command line commands, and Groovy constructs for conditional and loop statements. Additionally, it covers fundamental concepts relating to regular expressions and their applications in string manipulation.