





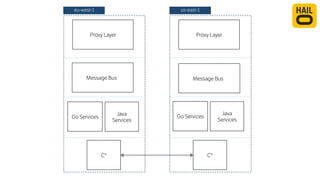
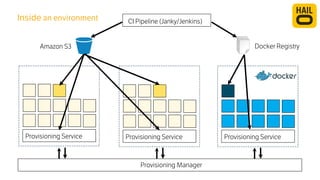
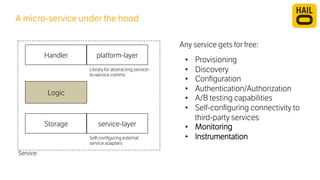

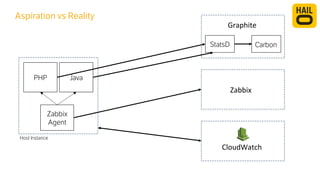


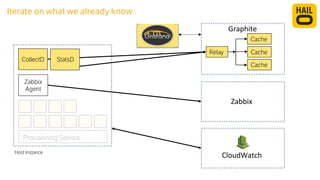

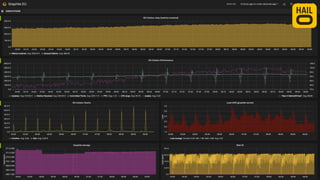

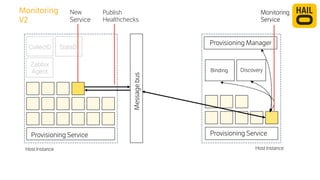
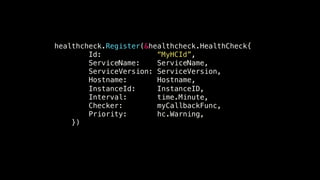



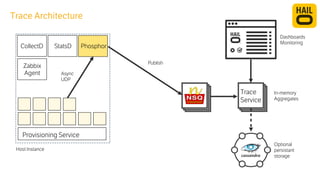
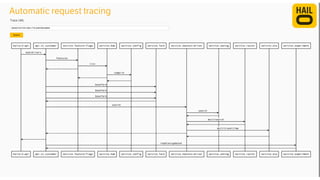



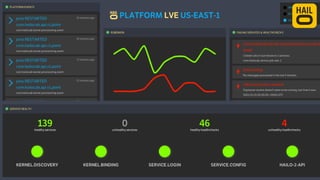



The document details the monitoring micro-services platform at Hailo, highlighting its architecture built on AWS with over 160 services and key challenges faced in scaling and instrumentation. It outlines the evolution of monitoring practices, including the transition to tools like Grafana and the implementation of service-level health checks for improved performance insights. The mission involves defining platform metrics, enhancing automatic failover capabilities, and integrating machine learning for advanced event correlation.














































































