OUTLINE
• Two-phase lockingtechniques for Concurrency control
• Concurrency control based on Timestamp ordering
• Multiversion Concurrency control techniques
• Validation Concurrency control techniques
• Granularity of Data items and Multiple Granularity
Locking.
3.
• The conceptof locking data items is one of the main techniques
used for controlling the concurrent execution of transactions.
• A lock is a variable associated with a data item in the database.
Generally there is a lock for each data item in the database.
• A lock describes the status of the data item with respect to
possible operations that can be applied to that item.
• It is used for synchronizing the access by concurrent
transactions to the database items.
• A transaction locks an object before using it
• When an object is locked by another transaction, the requesting
transaction must wait.
Two-Phase Locking Techniques for Concurrency
Control
4.
Types of Locksand System Lock Tables
1. Binary Locks
•A binary lock can have two states or values: locked and unlocked
(or 1 and 0).
•If the value of the lock on X is 1, item X cannot be accessed by a
database operation that requests the item
•If the value of the lock on X is 0, the item can be accessed when
requested, and the lock value is changed to 1
•We refer to the current value (or state) of the lock associated
with
item X as lock(X).
5.
• Two operations,lock_item and unlock_item, are used
with binary locking.
• A transaction requests access to an item X by first issuing a
lock_item{X} operation
• If LOCK( = 1, the transaction is forced to wait.)
• If LOCK( = 0, it is set to 1 (the transaction locks the item) and
the transaction is allowed to access item X
6.
• If LOCK(X) = 1, locked .
• If LOCK (X) = 0, the transaction locks the item and the transaction is
allowed to access item X.
• lock_item(X):
B: if LOCK(X) = 0 (* item is unlocked *) then
LOCK(X) 1 ( * lock the item *)
else
begin
wait (until LOCK(X) = 0 and the lock manager wakes
up the transaction);
go to B
end;
7.
unlock_item(X):
LOCK(X) 0;(* unlock the item *)
if any transactions are waiting then wakeup one
of the waiting transactions;
8.
• If thesimple binary locking scheme described here is used,
every transaction must obey the following rules:
1. A transaction T must issue the operation Iock_item(x) before
any read_item( x) or write_item(x) operations are performed
in T.
2. A transaction T must issue the operation unIock_item(x) after
all read_item(x) and write_item( x) operations are completed in
T.
3. A transaction T will not issue a Iock_item(x) operation
if it already holds the lock on item X.
4. A transaction T will not issue an unIock_item(x)
operation unless it already holds the lock on item X.
9.
2.Shared/Exclusive (or Read/Write)Locks:
• We should allow several transactions to access the same item X if they
all access X for reading purposes only.
• This is because read operations on the same item by different
transactions are not conflicting.
• For this purpose, a different type of lock called a multiple-mode
lock is used.
• In this scheme— called shared/exclusive or read/write locks—
there are three locking operations: read_lock(X), write_lock(X),
and unlock(X).
• A read-locked item is also called share-locked because other
transactions are allowed to read the item.
• whereas a write_locked item is called exclusive-locked because a
single transaction exclusively holds the lock on the item.
• unlock(X) called after all read_item(X) and write_item(X)
operations are completed .
10.
Shared (read )lock:
shared read_lock(X):
B: if LOCK(X) = “unlocked”
then begin LOCK(X) ← “read-locked”;
no_of_reads(X) ← 1
end
else if LOCK(X) = “read-locked”
then no_of_reads(X) ← no_of_reads(X) + 1
else
begin wait (until LOCK(X) = “unlocked” and the lock
manager wakes up the transaction);
go to B
end;
11.
Exclusive write Lock:
exclusive write_lock(X):
B: if LOCK(X) = “unlocked”
then LOCK(X) ← “write-locked”
else begin
wait (until LOCK(X) = “unlocked” and the lock
manager wakes up the transaction);
go to B
end;
12.
When we usethe shared/exclusive locking scheme, the
system must enforce the following rules:
1. A transaction T must issue the operation read_lock(X) or
write_lock(X) before any read_item(X) operation is performed in
T.
2. A transaction T must issue the operation write_lock(X) before
any write_item(X) operationis performed in T.
3. A transaction T must issue the operation unlock(X) after all
read_item(X) and write_item(X) operations are completed in T.
4. A transaction T will not issue a read_lock(X) operation if it already
holds a read (shared) lock or a write (exclusive) lock on item X.
5. A transaction T will not issue a write_lock(X) operation if it
already holds a read (shared) lock or write (exclusive) lock on
item X.
6. A transaction T will not issue an unlock(X) operation unless it
already holds a read (shared) lock or a write (exclusive) lock on
item X.
13.
Conversion of Locks:
•Sometimes it is desirable to relax conditions 4 and 5 in the
preceding list in order to allow lock conversion; that is, a
transaction that already holds a lock on item X is allowed under
certain conditions to convert the lock from one locked state to
another.
• For example, it is possible for a transaction T to issue a
read_lock(X) and then later to upgrade the lock by issuing a
write_lock(X) operation.
• If T is the only transaction holding a read lock on X at the time
it issues the write_lock(X) operation, the lock can be upgraded;
otherwise, the transaction must wait.
• It is also possible for a transaction T to issue a write_lock(X) and
then later to downgrade the lock by issuing a read_lock(X)
operation.
14.
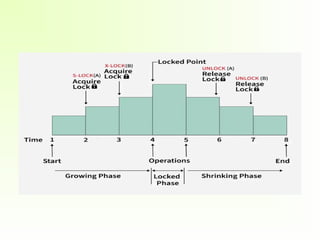
Guaranteeing Serializability byTwo-Phase Locking
• A transaction is said to follow the two-phase locking
protocol if all locking operations (read_lock, write_lock)
precede the first unlock operation in the transaction.
• Such a transaction can be divided into two phases:
– an expanding or growing (first) phase, during which new
locks on items can be acquired but none can be released;
– a shrinking (second) phase, during which existing locks can be
released but no new locks can be acquired.
• If lock conversion is allowed, then upgrading of locks (from read-
locked to write-locked) must be done during the expanding phase,
and downgrading of locks (from write-locked to read- locked) must
be done in the shrinking phase.
16.
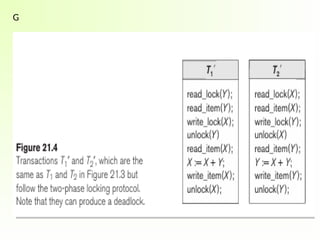
Slide 18-
• TransactionsT1 and T2 in Figure (a) do not follow the two-phase locking
protocol because the write lock ( X ) operation follows the unlock (Y)
operation in T1, and similarly the write lock (Y) operation follows the
unlock (X) operation in T2.
If we enforcetwo-phase locking, the transactions can be
rewritten as
T1’ and T2’ as shown in below Figure .
Now, the schedule shown in Figure (c) is not permitted for T1
and T2 (with their modified order of locking and unlocking
operations) under the rules of locking because T1 will issue
its write_Iock( x) before it unlocks item Y, consequently,
when T2_ issues its read_Iock( Y), it is forced to wait until
T1 releases the lock by issuing an unlock (Y) in the
schedule.
19.
Advantage :
• Ensuresserializability
Disadvantages:
• May not free from irrecoverability.
• May not free from deadlock.
• May not free from Starvation.
• May not free from cascading Rollback.
20.
Variations of Two-PhaseLocking
Basic 2PL
•Technique described previously
Conservative (static) 2PL
• Requires a transaction to lock all the items it accesses before
the transaction begins execution by predeclaring read-set and write-
set
•Its Deadlock-free protocol
Strict 2PL
•guarantees strict schedules
•Transaction does not release exclusive locks until after it commits or aborts
•no other transaction can read or write an item that is written by T unless T
has
committed, leading to a strict schedule for recoverability.
•Strict 2PL is not deadlock-free.
Rigorous 2PL
•guarantees strict schedules
•Transaction does not release any locks until after it commits or aborts
21.
Dealing with Deadlockand Starvation
Deadlock occurs when each transaction
transactions is waiting for some item
T in a set of two or
that is locked by some
more
other
transaction T’ in the set.
•Hence, each transaction in the set is in a waiting queue, waiting for one of
the other transactions in the set to release the lock on an item.
•But because the other transaction is also waiting, it will never release the
lock.
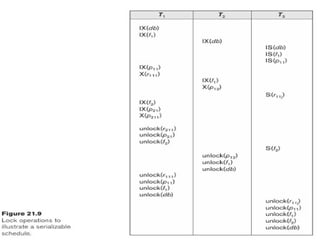
•A simple example is shown in Figure, where the two transactions T1’ and
T2’are deadlocked in a partial schedule; T1’ is in the waiting queue for X,
which is locked by T2’, while T2’ is in the waiting queue for Y, which is
locked by T1’. Meanwhile, neither T1’ nor T2’ nor any other transaction can
access items X and Y
22.
Methods for handlingdeadlock:
1. Deadlock prevention protocol
2. Deadlock detection and recovery
23.
Deadlock prevention protocols
Oneway to prevent deadlock is to use a deadlock
prevention protocol
• One deadlock prevention protocol, which is used in
conservative two-phase locking, requires that every transaction
lock all the items it needs in advance.
Two schemes that prevent deadlock are called wait-die and wound-
wait.
Suppose that transaction T, tries to lock an item X but is not able
to because X is locked by some other transaction Tj with a
conflicting lock. The rules followed by these schemes are:
24.
Wait-die:
If TS(Ti) <TS(Tj), then
(Ti older than Tj) Ti is allowed to wait;
Else
(Ti younger than Tj) abort Ti (Ti dies) and
restart it later with the same timestamp.
• In wait-die, an older transaction is allowed to wait for a younger
transaction, whereas a younger transaction requesting an item held by
an older transaction is aborted and restarted.
25.
Wound-wait:
If TS(Ti) >TS(Tj), then
(Ti younger than Tj) Ti is allowed to wait.
Else
(Ti older than Tj) abort Tj (Ti wounds Tj) and
restart it later with the same timestamp;
•The wound-wait approach does the opposite: A younger
transaction is allowed to wait for an older one, whereas an
older transaction requesting an item held by a younger
transaction preempts the younger transaction by aborting it.
Both schemes end up aborting the younger of the two
transactions (the transaction that started later) that may be
involved in a deadlock.
26.
Another group ofprotocols that prevent deadlock do not
require timestamps.
These include the
• No waiting (NW) and
• Cautious waiting (CW) algorithms
No waiting algorithm,
• If a transaction is unable to obtain a lock, it is immediately
aborted and then restarted after a certain time delay without
checking whether a deadlock will actually occur or not.
• No transaction ever waits, so no deadlock will occur.
• This scheme can cause transactions to abort and restart needlessly.
27.
cautious waiting
• Tryto reduce the number of needless aborts/restarts.
• Suppose that transaction Ti tries to lock an item X but is not able
to do so because X is locked by some other transaction Tj with a
conflicting lock.
The cautious waiting rules are as follows:
• If Tj is not blocked (not waiting for some other locked
item), then Ti is blocked and allowed to wait; otherwise abort
Ti.
• It can be shown that cautious waiting is deadlock-free,
because no transaction will ever wait for another blocked
transaction.
28.
Deadlock Detection:
• Indeadlock detection, the system checks if a state of deadlock actually
exists.
• This can happen if different transactions rarely access the same items
at the same time A simple way to detect a state of deadlock is for the
system to construct and maintain a wait-for graph.
• One node is created in the wait-for graph for each transaction that is
currently executing.
• Whenever a transaction Ti is waiting to lock an item X that is currently
locked by a transaction Tr a directed edge (T, TI) is created in the wait-
for graph.
• It can be checked for a cycle every time an edge is added to the wait-
for graph, but this may cause excessive overhead.
• Criteria such as the number of currently executing transactions or the
period of time several transactions have been waiting to lock items may
be used instead to check for a cycle.
29.
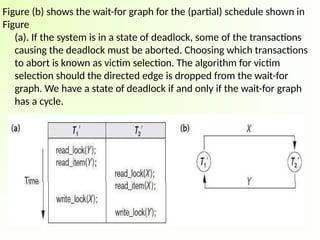
Figure (b) showsthe wait-for graph for the (partial) schedule shown in
Figure
(a). If the system is in a state of deadlock, some of the transactions
causing the deadlock must be aborted. Choosing which transactions
to abort is known as victim selection. The algorithm for victim
selection should the directed edge is dropped from the wait-for
graph. We have a state of deadlock if and only if the wait-for graph
has a cycle.
30.
Starvation:
• Another problemthat may occur when we use locking is starvation,
which occurs when a transaction cannot proceed for an
indefinite period of time while other transactions in the
system continue normally.
• This may occur if the waiting scheme for locked items is unfair,
giving priority to some transactions over others
• One solution for starvation is to have a fair waiting scheme, such as
using a first- come-first-served queue; transactions are enabled
to lock an item in the order in which they originally requested the lock.
• Another scheme allows some transactions to have priority over
others but increases the priority of a transaction the longer it
waits, until it eventually gets the highest priority and proceeds.
• Starvation can also occur because of victim selection if the algorithm
selects the same transaction as victim repeatedly, thus causing it
to abort and never finish execution.
• The algorithm can use higher priorities for transactions that have
been aborted multiple times to avoid this problem.
31.
Concurrency Control basedOn Timestamp Ordering
• Timestamp ordering is a concurrency control method in database systems that
schedules transactions based on their timestamps to ensure serializability.
Each transaction is assigned a unique timestamp when it begins.
Timestamp:
• Unique identifier assigned by the DBMS to identify a transaction.
• Assigned in the order submitted transaction start time( When
transaction enters into the system)
• Concurrency control techniques based on timestamps do not use locks.
• Deadlocks cannot occur.
• Timestamps can be generated in several ways.
- Counter incremented each time its value is assigned to a
transaction.
- Current date/time value of the system clock
- Ensure no two timestamps are generated during the same tick
of the clock
32.
The Timestamp OrderingAlgorithm for Concurrency
Control
• Timestamp ordering (TO)
Timestamp-based concurrency control is a method used in database systems
to ensure that transactions are executed safely and consistently without
conflicts, even when multiple transactions are being processed
simultaneously.
-Allows interleaving of transaction operations
-The schedule is equivalent to the particular serial order corresponding to the
order of the transaction timestamps.
- The algorithm ensures, each item accessed by the schedule does not
violate the timestamp order.
33.
To do this,the algorithm associates with each data base item X
two timestamp (TS)values:
- read_TS(X) :The read timestamp of item X is the largest
timestamp among all the timestamps of transactions that
have successfully read item X—that is, read_TS(X) = TS(T),
where T is the youngest transaction that has read X
successfully.
- write_TS(X):The write timestamp of item X is the largest of
all the timestamps of transactions that have successfully written
item X—that is, write_TS(X) = TS(T), where T is the youngest
transaction that has written X successfully.
34.
• Basic TOalgorithm
It compares the timestamp of T with read_TS(X) and
write_TS(X) for validating the order of transaction.
If order is violated, Transaction T is aborted and
resubmitted to the system as a new transaction with a
new timestamp.
If T is aborted and rolled back, any transaction T1 that
may have used a value written by T must also be rolled
back.
Similarly, any transaction T2 that may have used a value
written byT1 must also be rolled back, and so on. This
effect is known as cascading rollback.
35.
Basic Timestamp Orderingalgorithm
-The concurrency control algorithm must check whether conflicting operations
violate the timestamp ordering in the following two cases:
1. Whenever a transaction T issues a read_item(X)
operation,the following is checked:
A. If write_TS(X) > TS(T), then abort and roll back T and reject
the operation.
B. Otherwise execute the read_item(X) operation of T. and
set read_TS(X) = MAX{read_TS(X),TS(Ti)}
2. Whenever a transaction T issues a write_item(X)
operation,the following is checked:
A. If read_TS(X) > TS(T) or if write_TS(X) > TS(T),then abort and
roll back T and reject the operation.
B. Otherwise execute the write_item(X) operation of T and set
write_TS(X) to TS(T).
36.
Advantages of TimestampOrdering:
1.Ensures Serializability
2.Deadlock-Free
3.Simple to Implement
4.Automatic Ordering
5.Suitable for Distributed Databases
Disadvantages of Timestamp Ordering:
6.High Abort Rate
7.Starvation
8.Cascading Rollback
9.Storage Overhead
37.
Strict TO algorithm
-Ensures schedules are both strict -(for easy recoverability) and
conflict serializable.
- In this variation, a transaction T that issues a read_item(X) or
write_item(X) such that TS(T)>write_TS(X) has its read or write
operation delayed until the transaction T that wrote the value of
X(hence TS(T)=write_TS(X)) has committed or aborted.
- To implement this algorithm, it is necessary to simulate the locking of a
an item X that has been written by transaction T until T is either
committed or aborted.
- This algorithm does not cause deadlock, since T waits for T only if
TS(T) > TS(T).
38.
Thomas’s write rule:
-Modification of basic TO algorithm
- Does not enforce conflict serializability
- Rejects fewer write operations by modifying checks for write_item(X)
operation as follows:
1. If read_TS(X) > TS(T),then abort and roll back T and reject the operation.
2.If write_TS(X) > TS(T),then do not execute the write operation but
continue processing.
3.Otherwise , execute the write_item(X) operation of T and set
write_TS(X) to TS(T).
39.
Multiversion Concurrency ControlTechnique
• Several versions of an item are kept by a system-multiversion
concurrency control
• When a transaction requires access to an item, an appropriate
version is chosen to maintain the serializability of the currently
executing schedule.
• Some read operations that would be rejected in other techniques
can be accepted by reading an older version of the item.
• When a transaction writes an item, it writes a new version and
the old version(s) of the item are retained.
• Maintains serializability
• Disadvantage: More storage is needed to maintain multiple
versions of the database items.
• Multiversion currency control scheme types
o Based on timestamp ordering
o Based on two-phase locking n
o Validation and snapshot isolation techniques
40.
Multiversion Technique BasedOn Timestamp Ordering:
In this method, several versions X1, X2, ..., Xk of each data item X are
maintained. For each version, the value of version Xi and the following two
timestamps are kept:
1.read_TS(Xi):The read time stamp of Xi is the largest of all the
timestamps of transactions that have successfully read version Xi.
2. write_TS(Xi): The write timestamp of Xi is the timestamp of the
transaction that wrote the value of version Xi.
-When a transaction T is allowed to execute a write_item(X) operation, a
new version Xk+1 of item X is created, with both the write_TS(Xk+1) and the
read_TS(Xk+1) set to TS(T).
-when a transaction T is allowed to read the value of version Xi, the value of
read_TS(Xi) is set to the larger of the current read_TS(Xi) and TS(T).
41.
To ensure serializability,the following rules are used:
1.If transaction T issues a write_item(X) operation, for all value of
X : write_TS(Xi)≤ TS(T), and read_TS(Xi) > TS(T), then abort and
rollback Transaction T; otherwise, create a new version Xj of X with
read_TS(Xj)=write_TS(Xj)=TS(T).
2.If transaction T issues a read_item(X) operation, read_TS(Xi)≤
TS(T), then return the value of Xi to transaction T, and set the value
of read_TS(Xi) to the larger of TS(T) and the current read_TS(Xi).
42.
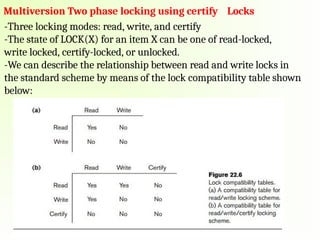
Multiversion Two phaselocking using certify Locks
-Three locking modes: read, write, and certify
-The state of LOCK(X) for an item X can be one of read-locked,
write locked, certify-locked, or unlocked.
-We can describe the relationship between read and write locks in
the standard scheme by means of the lock compatibility table shown
below:
43.
-An entry ofYes means that if a transaction T holds the type of lock
specified in the column header on item X and if transaction T requests
the type of lock specified in the Row header on the same item X, then T
can obtain the lock because the locking mode are compatible.
- On the other hand, an entry of No in the table indicates that the locks
are not compatible, so T must wait until T releases the lock as shown
in fig(a).
- From fig (b), T is ready to commit, it must obtain a certify lock on all
items that it currently holds write locks on before it can commit.
- The certify lock is not compatible with read locks, so the
transaction may have to delay its commit until all its write-locked
items are released by any reading transactions in order to obtain the
certify locks.
- Once the certify locks—which are exclusive locks—are acquired,
the committed version X of the data item is set to the value of
version X, version X is discarded, and the certify locks are then
released.
44.
Validation (Optimistic) Techniquesand Snapshot
Isolation Concurrency Control
Validation Based Concurrency Control:
• Also called validation or certification techniques
• No checking is done while the transaction is executing
• At the end of transaction execution, a validation phase checks
whether any of the transaction’s updates violate serializability.
• Certain information needed by the validation phase must be kept by
the system. Validation phase checks whether any of
transaction’s updates violate serializability
• If serializability is not violated, the transaction is committed and
the database is updated from the local copies; otherwise, the
transaction is aborted and then restarted later.
45.
There are threephases for this concurrency control protocol:
1. Read phase: A transaction can read values of committed data items
from the
database. However, updates are applied only to local copies (versions) of the
data items kept in the transaction workspace.
2. Validation phase: Checking is performed to ensure that serializability
will not be violated if the transaction updates are applied to the database.
3.Write phase: If the validation phase is successful, the transaction
updates are applied to the database; otherwise, the updates are discarded and
the transaction is restarted.
The validation phase for Ti checks that, for each such transaction Tj that is
either committed or is in its validation phase, one of the following conditions
holds:
1. Transaction Tj completes its write phase before Ti starts its read phase.
2.Ti starts its write phase after Tj completes its write phase, and the
read_set of Ti has no items in common with the write_set of Tj.
3.Both the read_set and write_set of Ti have no items in common with the
write_set of Tj, and Tj completes its read phase before Ti completes its read
phase.
46.
Concurrency Control basedon Snapshot Isolation
• Transaction sees data items based on committed
values of the items in the database snapshot
• Does not see updates that occur after transaction
starts
• Read operations do not require read locks
• Write operations require write locks
• Temporary version store keeps track of older versions of
updated items
• Variation: serializable snapshot isolation (SSI)
47.
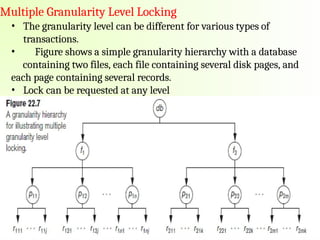
Granularity of DataItems and Multiple Granularity
Locking
Multiple Granularity Locking (MGL) is a concurrency control
method used in databases to manage locks at different levels of a
data hierarchy efficiently. Instead of locking only rows or only entire
tables, MGL allows locking at multiple levels, such as:
1. database record
2. A field value of a database record
3. A disk block
4. A whole file
5. The whole database
48.
Granularity Level Considerationsfor Locking:
• Size of data items known as data item granularity
-Fine (small) :Fine granularity
-Coarse (large) : coarse granularity
• Larger the data item size, lower the degree of concurrency
permitted
-Example: entire disk block locked
• Smaller the data item size -more locks required
• Higher overhead
- Best item size depends on transaction type
49.
Multiple Granularity LevelLocking
• The granularity level can be different for various types of
transactions.
• Figure shows a simple granularity hierarchy with a database
containing two files, each file containing several disk pages, and
each page containing several records.
• Lock can be requested at any level
50.
Intention locks areneeded
To make multiple granularity level locking practical, additional types
of locks, called intention locks, are needed.
The idea behind intention locks is for a transaction to indicate, along
the path from the root to the desired node, what type of lock (shared
or exclusive) it will require from one of the node’s descendants.
allow concurrent access while preventing conflicts:
There are three types of intention locks:
1.Intention-shared (IS) then explicit locking is done at a lower level, but
only with shared mode locks.
2.Intention-exclusive (IX) then explicit locking is done at a lower level,
but only with exclusive mode locks.
51.
3. Shared-intention-exclusive (SIX)
indicatesthat the current node is locked in shared mode but
that one or more exclusive locks will be requested on some
descendant node(s).
The compatibility table of the three intention locks, and the shared and
exclusive locks, is shown in below figure.
52.
The multiple granularitylocking (MGL) protocol
consists of the following rules:
1.The root of the tree must be locked first, in any mode.
2.A transaction can lock a node in S or IS mode only if it
has already locked the parent node in IS or IX mode
3.A transaction can lock a node in X, IX, or SIX mode only
if it has already locked the parent node in IX or SIX mode.
4.A transaction can lock a node only if it has not unlocked
any node (to enforce the 2PL protocol).
5.A transaction can unlock a node only if none of the
children of node are currently locked by Transaction.
53.
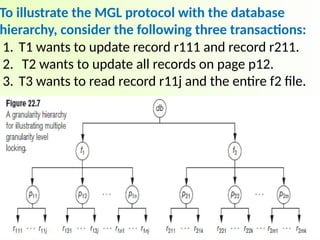
To illustrate theMGL protocol with the database
hierarchy, consider the following three transactions:
1. T1 wants to update record r111 and record r211.
2. T2 wants to update all records on page p12.
3. T3 wants to read record r11j and the entire f2 file.
OUTLINE
• Introduction toNOSQL Systems
• The CAP Theorem
• Document-Based NOSQL Systems and MongoDB
• NOSQL Key-Value Stores
• Column-Based or Wide Column NOSQL Systems
• NOSQL Graph Databases and Neo4j
57.
Introduction
Slide 23- 57
•Most NOSQL systems are distributed databases or distributed storage
systems which focus on semi-structured data storage, high
performance, availability, data replication, and scalability.
NoSQL, or “Not Only SQL,” is a database management system (DBMS)
designed to handle large volumes of unstructured and semi-structured
data.
It’s more than rows in tables—NoSQL systems store and retrieve
data from many formats: key-value stores, graph databases, column-
family (Bigtable) stores, document stores, and even rows in tables.
It works on many processors—NoSQL systems allow you to store
your database on multiple processors and maintain high-speed
performance.
It’s free of joins—
It’s schema-free—
58.
• why NOSQL?
•SQL systems offer too many services (powerful query language, concurrency control,
etc.)
• a structured data model may be too restrictive
• relational systems require schema, NOSQL systems don’t
• NOSQL systems focus on storage of ‘big data’
• typical applications that use NOSQL
• social media, web links, user profiles, marketing and sales, posts and tweets, road
maps and spatial data, email, etc
• Examples
• DynamoDB (Amazon): key-value data store
• BigTable: Google’s proprietary NOSQL system. Column-based or
wide column store
• Cassandra (Facebook): uses concepts from both key-value store
and column-based
systems
• MongoDB and CouchDB: document stores
• Neo4J and GraphBase: graph-based NOSQL systems
• OrientDB: combines several concepts
Characteristics of NOSQLSystems
NOSQL characteristics related to distributed databases and
distributed systems
•Scalability
• horizontal scalability (by adding more nodes) is employed while
the system is operational, so techniques for distributing the
existing data among new nodes without interrupting system
operation are necessary
•Availability, replication, and eventual consistency
• requirement for continuous system availability (data is
replicated over many nodes in transparent manner)
• if one node fails, the data is still available on other nodes
• replication improves data availability and read performance
(however, write performance becomes more cumbersome, must
write to every copy of the replicated data items)
• this can slow down write performance if serializable consistency
is required, so more relaxed forms of consistency known as
eventual consistency are used
61.
•Replication models
• master-slave
•requires one copy to be the master copy.
• all write operations must be applied to the master copy and then
propagated to the slave copies.
• usually using eventual consistency (the slave copies will eventually
be the
same as the master copy)
• master-master replication
• allows reads and writes at any of the replicas.
• may not guarantee that reads at nodes that store different copies see the
same values.
• different users may write the same data item concurrently at different
nodes of the system (so the values of the item will be temporarily
inconsistent).
•sharding of files
• NOSQL applications can have millions of records, and these records can be
accessed concurrently by thousands of users (it is not practical to store
the whole file in one node)
• sharding (also known as horizontal partitioning) of the file records is employ
• this serves to distribute the load of accessing the file records to multiple node
• the combination of sharding and replicating the shards works towards
62.
NOSQL characteristics relatedto data models and query languages
•schema not required
• semi-structured, self describing data facilitates this flexibility of no
schema
• the lack of schema and constraints:
• constraints on the data would have to be programmed
• languages for describing semi-structured data are
• JSON (JavaScript Object Notation)
• XML (Extensible Markup Language)
•less powerful query languages
• we may not require a powerful query language such as SQL because
search (read) queries often locate single objects in a single file based on
their object keys
• in many cases, the operations are called CRUD operations
• only a subset of SQL querying capabilities are provided (many NOSQL
systems do not provide join operations)
Versioning: Some NOSQL systems provide storage of multiple versions of
the data items, with the timestamps of when the data version was created.
63.
Categories of NOSQLsystems
• Document-based NOSQL systems: data in the form of documents.
documents are accessible via their document id, but can also be accessed
rapidly using other indexes.
• NOSQL key-value stores: simple data model based on fast access by
the key to the value associated with the key (hashing)
• Column-based or wide column NOSQL systems: These systems
partition a table by column into column families where each column
family is stored in its own files. They also allow versioning of data values.
• Graph-based NOSQL systems: Data is represented as graphs, and related
nodes can be found by traversing the edges using path expressions.
• Hybrid NOSQL systems: These systems have characteristics from two or
more of the above four categories.
64.
The CAP Theorem
•The CAP principle, can be used to explain some of the competing
requirements in a distributed system with replication.
CAP theorem: The CAP theorem states that it is not possible to guarantee all three
of the desirable properties—consistency, availability, and partition tolerance—at the
same time in a distributed system.
Consistency-the consistency of the values in different copies of the
same data item in a replicated distributed system.
Availability-of each read or write request for a data item will either be
processed successfully or will receive a message that the operation cannot be
completed.
partition tolerance- the system can continue operating if the network
connecting the nodes has a fault that results in two or more partitions, where
the nodes in each partition can only communicate among each other.
• Designer can choose two of three to guarantee.
• Weaker consistency level is often acceptable in NOSQL distributed data
store, it often guaranteeing availability and partition tolerance more
important. This form of consistency known as Eventual consistency.
65.
Slide 23- 65
Document-BasedNOSQL Systems and MongoDB
• Document stores
• Collections of similar documents
• Individual documents resemble complex objects or XML documents
• Documents are self-describing
• Can have different data elements
• new documents can have new data elements that do not exist in any of
the current documents in the collection.
• The system basically extracts the data element names from the self-
describing documents in the collection, and the user can request that
the system create indexes on some of the data elements.
• Documents can be specified in various formats:
• XML
• JSON
• A popular language to specify documents in NOSQL systems is JSON
(JavaScript Object Notation).
66.
MongoDB Data Model
•Documents stored in binary JSON (BSON) format-more efficient storage
than JSON with additional data types.
• Individual documents stored in a collection
• The operation createCollection is used to create each collection
• Syntax: db.createCollection(name, options)
Where, -First parameter specifies name of the collection
-Collection options include limits on size and number of documents
• Example: Company database
In our example, the collection is capped; this means it has upper limits on its
storage space (size) and number of documents (max). The capping parameters
help the system choose the storage options for each collection.
• Consider Employee database and create document collection Worker c
• Each document in collection has unique ObjectID field called _id, which is
automatically indexed in the collection unless the user explicitly requests
no
index for the _id field.
67.
• System-generated ObjectIdshave a specific format which combines:
- the timestamp: when the object is created
- the node id
- the process id and
- a counter (3 bytes) into a 16-byte Id value.
• User-generated ObjectsIds can have any value specified by the user as
long as it uniquely identifies the document and so these Ids are similar to
primary keys in relational systems.
• A collection does not have a schema
-Structure of the data fields in documents chosen based on how
documents will be accessed and used
-User can choose normalized or denormalized design
68.
• The Figure24.1(a) shows a simplified MongoDB document showing some of
the data from from the COMPANY database example.
• The workers information is embedded in the project document; so there is no
need for the “worker” collection.
• In Figure 24.1(b), where worker references are embedded in the project
document, but the worker documents themselves are stored in a separate
“worker” collection.
• A list of values that is enclosed in square brackets [ ... ] within a document
represents a field whose value is an array.
69.
• A thirdoption in Figure 24.1(c) would use a normalized design, similar to
First Normal Form relations.
• This design is not the general normalized design for a many-to-many
relationship, such as the one between employees and projects; rather, we
would need three collections for “project”, “employee”, and “works_on”.
• In the design in Figure 24.1(c), an EMPLOYEE who works on several projects
would be represented by multiple worker documents with different _id values;
each document would represent the employee as worker for a particular project.
70.
MongoDB CRUD Operations
•MongoDbhas several CRUD operations, where CRUD stands for (create, read,
update, delete).
INSERT: Documents can be created and inserted into their collections using
the insert operation, whose format is:
• The parameters of the insert operation can include either a single document
or an array of documents as shown below:
DELETE: The delete operation is called remove, and the format is:
• The documents to be removed from the collection are specified by a Boolean
condition on some of the fields in the collection documents.
71.
UPDATE: There isalso an update operation, which has a condition to select
certain documents, and a $set clause to specify the update.
• It is also possible to use the update operation to replace an existing
document with another one but keep the same ObjectId.
READ: the main command is called find, and the format is:
• General Boolean conditions can be specified as <condition>, and the
documents in the collection that return true are selected for the query result.
db.student.update({name:"prachi"},{$set:{age:20}}
db.<collection_name>.find(<condition>)
72.
MongoDB Distributed SystemsCharacteristics
• Two-phase commit method
• Used to ensure atomicity and consistency of multidocument
transactions
• Replication in MongoDB
• Concept of replica set to create multiple copies of same data set
on
different nodes
• Variation of master-slave approach
• Example, to replicate a particular document collection C-A replica set
will have one primary copy in one node N1, secondary copy on another
node N2.
• Primary copy, secondary copy, and arbiter
• Arbiter participates in elections to select new primary if needed
• All write operations applied to the primary copy and propagated to the
secondaries
• For read operations, the user can choose the particular read preference
for their application.
• The default read preference processes all reads at the primary copy
• So, all read and write operations are performed at the primary node.
73.
• In thiscase, secondary copies are mainly to make sure that the system
continues operation if the primary fails
• To increase read performance, it is possible to set the read preference so that
read requests can be processed at any replica (primary or secondary);
• However, a read at a secondary is not guaranteed to get the latest version of a
document
• a delay in propagating writes from the primary to the secondaries.
Sharding in MongoDB
•Sharding of the documents in the collection—also known as horizontal
partitioning-divides the documents into disjoint partitions known as shards.
• add more nodes as needed by a process known as horizontal scaling of
the distributed system
• Load balancing- by storing the shards of the collection on different
nodes
• The partitioning field—known as the shard .
Two main characteristics of shard:
• It must exist in every document in the
collection,
• It must have an index.
74.
• The valuesof the shard key are divided into chunks either through range
partitioning or hash partitioning.
There are two ways to partition a collection into shards in MongoDB—
1. Range partitioning:
• creates chunks by specifying a range of key values
• If the shard key values ranged from one to thousand, it is possible to
create ten ranges—1 to 100; 101 to 200; ... ; 901 to1000—and
• each chunk would contain the key values in one range.
• works best with range queries
2. Hash partitioning
• Applies a hash function h(K) to each shard key K, and the partitioning of
keys into chunks is based on the hash values
• When sharding is used, MongoDB queries are submitted to a module calle
the query router, which keeps track of which nodes contain which shards
based on the particular partitioning method used on the shard keys.
• The query (CRUD operation) will be routed to the nodes that hold the
documents.
• If the system cannot determine which shards hold the required
documents, the query will be submitted to all the nodes that hold
shards of the collection.
75.
• Sharding focuseson improving performance via load balancing and
horizontal scalability
• Replication focuses on ensuring system availability when certain
nodes fail in the distributed system.
76.
NOSQL Key-Value Stores
•Key-value stores focus on high performance, availability, and
scalability
• Can store structured, unstructured, or semi-structured
data
• Key: unique identifier associated with a data item
• Used for fast retrieval
• Value: the data item itself
• Can be string or array
of bytes
• Application interprets
the structure
77.
DynamoDB Overview
• DynamoDBpart of Amazon’s Web Services/SDK platforms (proprietary)
DynamoDB data model: The basic data model in DynamoDB uses the
concepts of tables, items, and attributes.
• Table holds a collection of self-describing items
• Each item consists of attribute-value pairs (records-tuples)
• attribute values can be single or multi-valued
•primary key used to locate items within a table
•can be single attribute or pair of attributes
• When a table is created, it is required to specify a table name and a
primary key;
• The primary key is the key and the item is the value for the DynamoDB
key-value store.
The primary key can be one of the following two types:
1. A single attribute:
• This attribute to build a hash index on the items in the table. This is
called a hash type primary key.
• The items are not ordered in storage on the value of the hash attribute
78.
2. A pairof attributes:
• This is called a hash and range type primary key.
• The primary key will be a pair of attributes (A, B):
• attribute A will be used for hashing, and because there will
be multiple items with the same value of A,
• the B values will be used for ordering the records with the
same A value.
• A table with this type of key can have additional secondary
indexes defined
79.
Voldemort Key-Value DistributedData Store
• Voldemort: open source key-value system similar to Amazon
DynamoDB.
• The focus is on high performance and horizontal scalability, as well as on
providing replication for high availability and sharding for improving
latency (response time) of read and write requests.
• These features are achieved through- Consistent Hashing
• through a technique to distribute the key-value pairs among the
nodes of a distributed cluster;
• Voldemort has been used by LinkedIn for data storage.
Voldemort features:
1. Simple basic operations (get, put, and delete)
• A collection of (key, value) pairs is kept in a Voldemort store ‘s’.
• The operation s.put(k, v) inserts an item as a key-value pair with
key k and value v.
• The operation s.delete(k) deletes the item whose key is k from the
store, and
• the operation v = s.get(k) retrieves the value v associated with key
k. Slide 23- 67
80.
2.High-level formatted datavalues:
• The values v in the (k, v) items can be specified in JSON (JavaScript
Object Notation), and the system will convert between JSON and the
internal storage format.
• Serialization- convert the user defined format to internal storage
through serializer classes.
3. Consistent hashing for distributing (key, value) pairs
• Voldemort for data distribution among the nodes in the distributed
cluster of nodes.
• A hash function h(k) is applied to the key k of each (k, v) pair, and
h(k) determines where the item will be stored.
• The method assumes that h(k) is an integer value, usually in the range
0 to Hmax = 2n−1 and evenly distributed on a circle (or ring).
• The nodes are located on the same ring and each node will have
several locations on the ring.
• Point represents- node
• An item (k, v) will be stored on the node whose position in the
ring follows the position of h(k) on the ring in a clockwise
direction.
81.
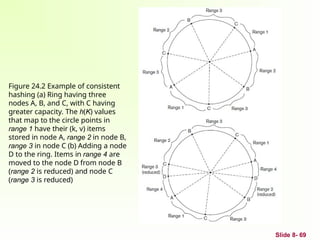
Slide 8- 69
Figure24.2 Example of consistent
hashing (a) Ring having three
nodes A, B, and C, with C having
greater capacity. The h(K) values
that map to the circle points in
range 1 have their (k, v) items
stored in node A, range 2 in node B,
range 3 in node C (b) Adding a node
D to the ring. Items in range 4 are
moved to the node D from node B
(range 2 is reduced) and node C
(range 3 is reduced)
82.
4. Consistency andversioning:
• Concurrent write operations are allowed by different processes
so there could exist two or more different values associated
with the same key at different nodes when items are
replicated.
• Consistency is achieved when the item is read by using a
technique known as versioning and read repair.
• Concurrent writes are allowed, but each write is associated with
a vector clock value. When a read occurs, it is possible that
different versions of the same value (associated with the same
key) are read from different nodes.
• If the system can reconcile to a single final value, it will pass
that value to the read;
• otherwise, more than one version which will reconcile the
various versions into one version based on the application
semantics and give this reconciled value back to the nodes.
83.
Slide 23- 83
Column-Basedor Wide Column NOSQL Systems
• The Google distributed storage system for big data, known as BigTable, is a
well-known example of this class of NOSQL systems, and it is used in many
Google applications such as Gmail.
• Big-Table uses the Google File System (GFS) for data storage and
distribution.
• An open source system known as Apache HBase is somewhat similar to
Google Big-Table, but it typically uses HDFS (Hadoop Distributed File
System) for data storage.
• Hbase can also use Amazon’s Simple Storage System (known as S3) for
data storage.
• BigTable (and Hbase) is sometimes described as a sparse
multidimensional distributed persistent sorted map, where the word
map means a collection of (key, value) pairs (the key is mapped to the
value).
• In column-based systems such as Hbase, the key is multidimensional and
so has several components: typically, a combination of table name, row
key, column, and timestamp.
84.
Slide 23- 84
HbaseData Model and Versioning
• The data model in Hbase organizes data using the concepts Dat
organization concepts
• Namespaces
• Tables
• Column families
• Column qualifiers
• Columns
• Rows
• Data cells
• A column is identified by a combination of (column family:column
qualifier).
Data is stored in a self-describing form by associating columns with data
values, where data values are strings.
• Tables and Rows:
• Data in Hbase is stored in tables, and each table has a table name.
• Data in a table is stored as self-describing rows.
• Each row has a unique row key and they are in lexicographical order
85.
•Column Families, ColumnQualifiers, and Columns:
Column families:
• A table is associated with one or more column
families.
• Each column family will have a name and must be specified when the
table is created and cannot be changed later.
• column families are a way of grouping together related columns
for storage purposes,
Example: Creating a table called EMPLOYEE with three column families:
Name, Address, and Details.
create ‘EMPLOYEE’, ‘Name’, ‘Address’, ‘Details’
-the table name is followed by the names of the column families associated
with the table.
• When the data is loaded into a table, each column family can be associated
with many column qualifiers, but the column qualifiers are not specified
as part of creating a table.
• A column is specified by a combination of
ColumnFamily : ColumnQualifier.
86.
Column Qualifiers:
• Sothe column qualifiers make the model a self-describing data model because
the qualifiers can be dynamically specified as new rows are created and
inserted into the table.
Example: Inserting some in the EMPLOYEE table; different rows can have
different self describing column qualifiers (Fname, Lname, Nickname, Mname,
Minit, Suffix, ... for column family Name; Job, Review, Supervisor, Salary for
column family Details).
• It is important that the application programmers know which column qualifiers
belong to each column family, even though they have the flexibility to create
new column qualifiers on the fly when new data rows are created.
• The concept of column family is somewhat similar to vertical partitioning
87.
Versions and Timestamps:
•HBase can keep several versions of a data item, along with the
timestamp associated with each version.
• The timestamp is a long integer number that represents the system
time when the version was created, so newer versions have larger
timestamp values.
• HBase uses midnight ‘January 1, 1970 UTC’ as timestamp value zero, and
uses a long integer that measures the number of milliseconds since that
time as the system timestamp value .
• It is also possible for the user to define the timestamp value explicitly
in a Date format rather than using the system-generated timestamp.
Cells:
• A cell holds a basic data item in HBase.
• The key (address) of a cell is specified by a combination of (table,
rowid, columnfamily, columnqualifier, timestamp).
• The default number of versions to be retrieved, as well as the default
number of versions that the system needs to keep, are parameters that can
be specified during table creation.
88.
•If timestamp isleft out, the latest version of the item is retrieved
unless a default number of versions is specified, say the latest three
versions.
• The default number of versions to be retrieved, as well as the default
number of versions that the system needs to keep, are parameters that
can be specified during table creation.
Namespaces:
• A namespace is a collection of tables.
• A namespace basically specifies a collection of one or more tables that are
typically used together by user applications, and it corresponds to a
database that contains a collection of tables in relational terminology.
89.
Slide 23- 89
HBaseCRUD Operations
• Provides only low-level CRUD (create, read, update, delete) operations
• Application programs implement more complex operations
• HBase only provides low-level CRUD operations.
• Create: It creates a new table and specifies one or more column families
associated with that table, but it does not specify the column qualifiers.
• Put: The put operation is used for inserting new data or new versions of
existing data items.
• Get: The get operation is for retrieving the data associated with a single
row in a table, and
• Scan: the scan operation retrieves all the rows.
90.
Slide 23- 90
HbaseStorage and Distributed System Concepts
• Each Hbase table divided into several regions
• Each region holds a range of the row keys in the table
• Row keys must be lexicographically ordered
• Each region has several stores
• Column families are assigned to stores
• Regions assigned to region servers for storage
• Master server responsible for monitoring
the region servers
•Hbase uses Apache Zookeeper-system for services related to man-
aging the naming, distribution, and synchronization of the Hbase data on
the distributed Hbase server nodes,
• Hbase also uses Apache HDFS (Hadoop Distributed File System) for
91.
Slide 23- 91
NOSQLGraph Databases and Neo4j
• Graph databases
• Collection of vertices (nodes) and edges.
• Both nodes and edges can be labeled to indicate the types of
entities and relationships they represent,
• Possible to store data associated with both individual nodes and
individual edges
• The most used graph database system which is used in many
application is Neo4j
92.
Neo4j Data Model
•Neo4j organizes data using the concepts of nodes and relationships.
• which store the data items associated with nodes and relationships.
• Nodes can have labels, the nodes that have the same label are grouped into a
collection that identifies a subset of the nodes in the database graph for
querying purposes.
• A node can have zero, one, or several
• Relationships are directed; each relationship has a start node and end
node.
• Each node as relationship type, which serves a similar role to a node label
by identifying similar relationships that have the same relationship type.
• Properties can be specified via a map pattern, which is made of one or
more “name : value” pairs enclosed in curly brackets;
for example {Lname : ‘Smith’, Fname : ‘John’, Minit : ‘B’}.
• In the Neo4j graph model with ER/EER concepts,
• nodes -entities,
• node labels- entity types and subclasses,
• relationships -relationship instances,
• relationship types - relationship types,
• Properties- attributes. Slide 23- 80
93.
Creating nodes inNeo4j
• CREATE command
• Part of high-level declarative query language Cypher
• Labels and properties: When a node is created, the node label can be
specified. It is also possible to create nodes without any labels.
• Properties are enclosed in curly brackets.
• Example: Employee, Department
• It is possible that some nodes have multiple labels; listing all the
labels separated by the colon symbol
• Example: Person: Employee: Manager
Slide 23- 93
94.
• Relationships andrelationship types:
• The → specifies the direction of the relationship, but the relationship
can be traversed in either direction.
• The relationship types (labels) are WorksFor, Manager, LocatedIn, and
WorksOn; only relationships with the relationship type WorksOn have
properties (Hours).
Slide 23- 94
95.
• Path
• Traversalof part of the graph
• Typically used as part of a query to specify a pattern
• A path is typically specified by a start node, followed by one or more
relationships, leading to one or more end nodes that satisfy the pattern.
• Schema optional in Neo4j
• Graphs can be created and used without a schema
• The main features related to schema creation involve creating
indexes and constraints based on the labels and properties.
• Indexing and node identifiers
• When a node is created, Neo4j system creates an internal unique
system-defined identifier for each node.
• Users can create for the collection of nodes that have a particular
label.
• One or more properties can be indexed
• For example, Empid can be used to index nodes with the
• EMPLOYEE label, Dno to index the nodes with the DEPARTMENT
label, and Pno to index the nodes with the PROJECT label.
Slide 23- 95
96.
The Cypher QueryLanguage of Neo4j
Slide 23- 96
• Cypher query made up of clauses
• Result from one clause can be the input to the next clause in the
query
• The below figure summarizes some of the main clauses that can be
part of a Cyber query.
97.
• The Cyberlanguage can specify complex queries and updates on a
graph database.
• We will give a few of examples to illustrate simple Cyber queries
• Match specifies the pattern and the query variables (d and loc)
• RETURN specifies the query result to be retrieved by referring to the query
variables.
• It is also possible to limit the number of returned results by using the LIMIT claus
98.
Neo4j Interfaces andDistributed System Characteristics
Slide 23- 86
• Neo4j has other interfaces that can be used to create, retrieve, and
update nodes and relationships in a graph database.
• It also has two main versions:
• Enterprise edition-which comes with additional capabilities
• Community edition
Additional features of Neo4J
• Enterprise edition versus community edition:
• Enterprise edition supports caching, clustering of data, and
locking
• Both editions support the Neo4j graph data model and storage
system, as well as the Cypher graph query language
• Both editions support ACID properties.
• Graph visualization interface
• Subset of nodes and edges in a database graph can be
displayed
as a graph
• This tool can be used to visualize query results in a graph
representation.
99.
• Master-slave replication:
•Neo4j can be configured on a cluster of distributed system nodes
(computers), where one node is designated the master node.
• The data and indexes are fully replicated on each node in the
cluster.
• synchronizing between master and slave nodes can be configured in the
distributed cluster.
• Caching: A main memory cache can be configured to store the graph
data for improved performance.
• Logical logs: Logs can be maintained to recover from failures.
100.
24.7 Summary
NOSQL systemsfocus on storage of “big data”
General categories
Document-based
Key-value stores
Column-based
Graph-based
Some systems
use techniques
spanning two or
more categories
Consistency
paradigms
CAP theorem
Slide 23- 88




























































![• The Figure 24.1(a) shows a simplified MongoDB document showing some of
the data from from the COMPANY database example.
• The workers information is embedded in the project document; so there is no
need for the “worker” collection.
• In Figure 24.1(b), where worker references are embedded in the project
document, but the worker documents themselves are stored in a separate
“worker” collection.
• A list of values that is enclosed in square brackets [ ... ] within a document
represents a field whose value is an array.](https://image.slidesharecdn.com/module-5dbms-250712081512-74ed9bef/85/Module-5_DataBase-Management-System-pptx-68-320.jpg)