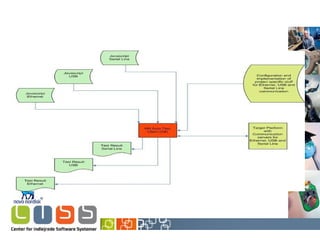
The document discusses model-based automatic offline MMI testing at Novo Nordisk, focusing on the testing of embedded devices and user interaction through MMI flows. It highlights the transition from manual to automated verification processes using UML state machine diagrams to improve efficiency and documentation of test coverage. Key outcomes include enhanced software quality, easier regression testing, and improved collaboration among stakeholders.



![Timed Automata Synchronization Guard Invariant Reset [Alur & Dill’89] Resource](https://image.slidesharecdn.com/idaypresentation-12817988375442-phpapp01/85/Model-based-GUI-testing-using-UPPAAL-4-320.jpg)
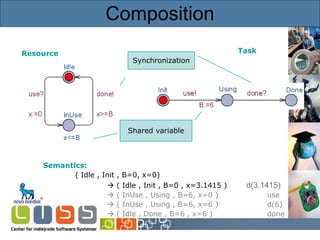
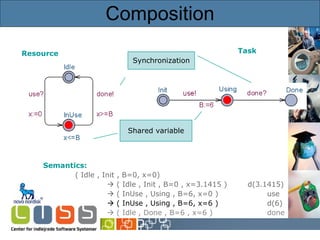
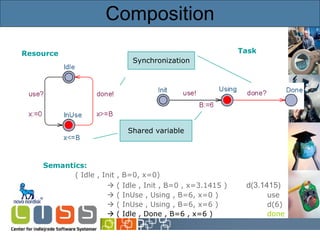
![Timed Automata Resource Semantics: ( Idle , x=0 ) ( Idle , x=2.5) d(2.5) ( InUse , x=0 ) use? ( InUse , x=5) d(5) ( Idle , x=5) done! ( Idle , x=8) d(3) ( InUse , x=0 ) use? [Alur & Dill’89]](https://image.slidesharecdn.com/idaypresentation-12817988375442-phpapp01/85/Model-based-GUI-testing-using-UPPAAL-5-320.jpg)
![Timed Automata Resource Semantics: ( Idle , x=0 ) ( Idle , x=2.5) d(2.5) ( InUse , x=0 ) use? ( InUse , x=5) d(5) ( Idle , x=5) done! ( Idle , x=8) d(3) ( InUse , x=0 ) use? [Alur & Dill’89] Synchronization Guard Invariant Reset](https://image.slidesharecdn.com/idaypresentation-12817988375442-phpapp01/85/Model-based-GUI-testing-using-UPPAAL-6-320.jpg)
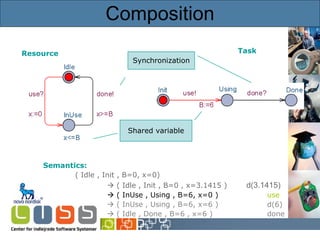
![Timed Automata Resource Semantics: ( Idle , x=0 ) ( Idle , x=2.5) d(2.5) ( InUse , x=0 ) use? ( InUse , x=5) d(5) ( Idle , x=5) done! ( Idle , x=8) d(3) ( InUse , x=0 ) use? [Alur & Dill’89] Synchronization Guard Invariant Reset](https://image.slidesharecdn.com/idaypresentation-12817988375442-phpapp01/85/Model-based-GUI-testing-using-UPPAAL-7-320.jpg)
![Timed Automata Resource Semantics: ( Idle , x=0 ) ( Idle , x=2.5) d(2.5) ( InUse , x=0 ) use? ( InUse , x=5) d(5) ( Idle , x=5) done! ( Idle , x=8) d(3) ( InUse , x=0 ) use? [Alur & Dill’89] Synchronization Guard Invariant Reset](https://image.slidesharecdn.com/idaypresentation-12817988375442-phpapp01/85/Model-based-GUI-testing-using-UPPAAL-8-320.jpg)
![Timed Automata Resource Semantics: ( Idle , x=0 ) ( Idle , x=2.5) d(2.5) ( InUse , x=0 ) use? ( InUse , x=5) d(5) ( Idle , x=5) done! ( Idle , x=8) d(3) ( InUse , x=0 ) use? [Alur & Dill’89] Synchronization Guard Invariant Reset](https://image.slidesharecdn.com/idaypresentation-12817988375442-phpapp01/85/Model-based-GUI-testing-using-UPPAAL-9-320.jpg)
![Advanced Features int [0,1234] ivar = 42; typedef struct { bool sL; } base_t; base_t Base; bool func(base_t & bt) { if (ivar < 31) return bt.sL; else return true ; } Template ( base_t & bt )](https://image.slidesharecdn.com/idaypresentation-12817988375442-phpapp01/85/Model-based-GUI-testing-using-UPPAAL-14-320.jpg)