Download as PDF, PPTX








![Thuật toán Naïve Bayes
Thuật toán chia làm 2 giai đoạn:
Huấn luyện
Input:
Ma trận đánh giá R[m x n], m là số user trong tập huấn luyện, n là số
item trong tập huấn luyện
Tập nhãn/lớp cho từng vector đặc trưng cho đối tượng cần phân lớp
của tập huấn luyện
Output: xác suất P(Ci) và P(Xk|Ci)
Bước 1: Tính P(Ci)
Bước 2: Tính P(Xk|Ci)](https://image.slidesharecdn.com/modelbasedcollaborativefiltering-140528215901-phpapp01/85/Model-based-collaborative-filtering-8-320.jpg)









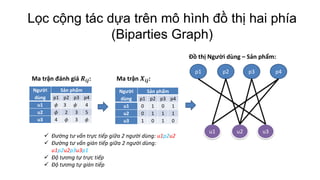



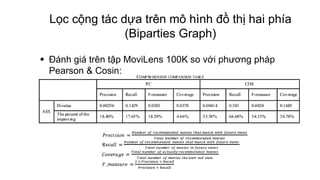
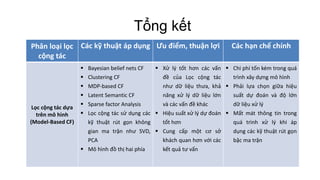


Tài liệu trình bày về các hệ thống khuyến nghị, đặc biệt là phương pháp lọc cộng tác, nơi người dùng nhận được sản phẩm đề xuất dựa trên sở thích của những người dùng khác tương tự. Nó khám phá các mô hình như mạng bayes, ngữ nghĩa ẩn và đồ thị hai phía, cùng với các kỹ thuật như phân loại naïve bayes và phân rã giá trị riêng để dự đoán đánh giá sản phẩm. Cuối cùng, tài liệu nêu rõ ưu điểm và nhược điểm của các phương pháp lọc cộng tác và việc ứng dụng các kỹ thuật để giải quyết vấn đề dữ liệu thưa và hiệu suất dự đoán.



































































