ML Label engineering and N-Hot Encoders
•Download as PPTX, PDF•
1 like•541 views
Suggesting an N-Hot Encoding approach, in the pre-processing (Machine Learning) phase of categorical data
Report
Share
Report
Share

Recommended
Feature Engineering in Machine Learning
In this Knolx we are going to explore Data Preprocessing and Feature Engineering Techniques. We will also understand what is Feature Engineering and its importance in Machine Learning. How Feature Engineering can help in getting the best results from the algorithms.
Introduction of Data Science
This document provides an overview of data science including what is big data and data science, applications of data science, and system infrastructure. It then discusses recommendation systems in more detail, describing them as systems that predict user preferences for items. A case study on recommendation systems follows, outlining collaborative filtering and content-based recommendation algorithms, and diving deeper into collaborative filtering approaches of user-based and item-based filtering. Challenges with collaborative filtering are also noted.
Data science
The document provides an overview of data science through an introduction by Sreejith C, a data scientist. It defines data science as discovering unknown information from data, obtaining predictive insights, creating impactful data products, and communicating business stories from data. A data scientist's work includes tasks like authoring data processing pipelines, performing analyses, and communicating results. The document also demonstrates a loan prediction problem using machine learning algorithms like logistic regression, decision trees, and random forests in Python.
Data science presentation
This document provides an overview of getting started with data science using Python. It discusses what data science is, why it is in high demand, and the typical skills and backgrounds of data scientists. It then covers popular Python libraries for data science like NumPy, Pandas, Scikit-Learn, TensorFlow, and Keras. Common data science steps are outlined including data gathering, preparation, exploration, model building, validation, and deployment. Example applications and case studies are discussed along with resources for learning including podcasts, websites, communities, books, and TV shows.
Data science
The document outlines a data science roadmap that covers fundamental concepts, statistics, programming, machine learning, text mining, data visualization, big data, data ingestion, data munging, and tools. It provides the percentage of time that should be spent on each topic, and lists specific techniques in each area, such as linear regression, decision trees, and MapReduce in big data.
Deep learning - A Visual Introduction
It’s long ago, approx. 30 years, since AI was not only a topic for Science-Fiction writers, but also a major research field surrounded with huge hopes and investments. But the over-inflated expectations ended in a subsequent crash and followed by a period of absent funding and interest – the so-called AI winter. However, the last 3 years changed everything – again. Deep learning, a machine learning technique inspired by the human brain, successfully crushed one benchmark after another and tech companies, like Google, Facebook and Microsoft, started to invest billions in AI research. “The pace of progress in artificial general intelligence is incredible fast” (Elon Musk – CEO Tesla & SpaceX) leading to an AI that “would be either the best or the worst thing ever to happen to humanity” (Stephen Hawking – Physicist).
What sparked this new Hype? How is Deep Learning different from previous approaches? Are the advancing AI technologies really a threat for humanity? Let’s look behind the curtain and unravel the reality. This talk will explore why Sundar Pichai (CEO Google) recently announced that “machine learning is a core transformative way by which Google is rethinking everything they are doing” and explain why "Deep Learning is probably one of the most exciting things that is happening in the computer industry” (Jen-Hsun Huang – CEO NVIDIA).
Either a new AI “winter is coming” (Ned Stark – House Stark) or this new wave of innovation might turn out as the “last invention humans ever need to make” (Nick Bostrom – AI Philosoph). Or maybe it’s just another great technology helping humans to achieve more.
Lecture #01
This document provides an overview of the introductory lecture to the BS in Data Science program. It discusses key topics that were covered in the lecture, including recommended books and chapters to be covered. It provides a brief introduction to key terminologies in data science, such as different data types, scales of measurement, and basic concepts. It also discusses the current landscape of data science, including the difference between roles of data scientists in academia versus industry.
Three Big Data Case Studies
Takes you to the fundamentals of Big Data. Has real life examples. Also find out why you may or may not need Big Data.
Recommended
Feature Engineering in Machine Learning
In this Knolx we are going to explore Data Preprocessing and Feature Engineering Techniques. We will also understand what is Feature Engineering and its importance in Machine Learning. How Feature Engineering can help in getting the best results from the algorithms.
Introduction of Data Science
This document provides an overview of data science including what is big data and data science, applications of data science, and system infrastructure. It then discusses recommendation systems in more detail, describing them as systems that predict user preferences for items. A case study on recommendation systems follows, outlining collaborative filtering and content-based recommendation algorithms, and diving deeper into collaborative filtering approaches of user-based and item-based filtering. Challenges with collaborative filtering are also noted.
Data science
The document provides an overview of data science through an introduction by Sreejith C, a data scientist. It defines data science as discovering unknown information from data, obtaining predictive insights, creating impactful data products, and communicating business stories from data. A data scientist's work includes tasks like authoring data processing pipelines, performing analyses, and communicating results. The document also demonstrates a loan prediction problem using machine learning algorithms like logistic regression, decision trees, and random forests in Python.
Data science presentation
This document provides an overview of getting started with data science using Python. It discusses what data science is, why it is in high demand, and the typical skills and backgrounds of data scientists. It then covers popular Python libraries for data science like NumPy, Pandas, Scikit-Learn, TensorFlow, and Keras. Common data science steps are outlined including data gathering, preparation, exploration, model building, validation, and deployment. Example applications and case studies are discussed along with resources for learning including podcasts, websites, communities, books, and TV shows.
Data science
The document outlines a data science roadmap that covers fundamental concepts, statistics, programming, machine learning, text mining, data visualization, big data, data ingestion, data munging, and tools. It provides the percentage of time that should be spent on each topic, and lists specific techniques in each area, such as linear regression, decision trees, and MapReduce in big data.
Deep learning - A Visual Introduction
It’s long ago, approx. 30 years, since AI was not only a topic for Science-Fiction writers, but also a major research field surrounded with huge hopes and investments. But the over-inflated expectations ended in a subsequent crash and followed by a period of absent funding and interest – the so-called AI winter. However, the last 3 years changed everything – again. Deep learning, a machine learning technique inspired by the human brain, successfully crushed one benchmark after another and tech companies, like Google, Facebook and Microsoft, started to invest billions in AI research. “The pace of progress in artificial general intelligence is incredible fast” (Elon Musk – CEO Tesla & SpaceX) leading to an AI that “would be either the best or the worst thing ever to happen to humanity” (Stephen Hawking – Physicist).
What sparked this new Hype? How is Deep Learning different from previous approaches? Are the advancing AI technologies really a threat for humanity? Let’s look behind the curtain and unravel the reality. This talk will explore why Sundar Pichai (CEO Google) recently announced that “machine learning is a core transformative way by which Google is rethinking everything they are doing” and explain why "Deep Learning is probably one of the most exciting things that is happening in the computer industry” (Jen-Hsun Huang – CEO NVIDIA).
Either a new AI “winter is coming” (Ned Stark – House Stark) or this new wave of innovation might turn out as the “last invention humans ever need to make” (Nick Bostrom – AI Philosoph). Or maybe it’s just another great technology helping humans to achieve more.
Lecture #01
This document provides an overview of the introductory lecture to the BS in Data Science program. It discusses key topics that were covered in the lecture, including recommended books and chapters to be covered. It provides a brief introduction to key terminologies in data science, such as different data types, scales of measurement, and basic concepts. It also discusses the current landscape of data science, including the difference between roles of data scientists in academia versus industry.
Three Big Data Case Studies
Takes you to the fundamentals of Big Data. Has real life examples. Also find out why you may or may not need Big Data.
Data Science
The document provides an overview of key concepts in data science including data types, the data value chain, and big data. It defines data science as extracting insights from large, diverse datasets using tools like machine learning. The data value chain involves acquiring, processing, analyzing and using data. Big data is characterized by its volume, velocity and variety. Common techniques for big data analytics include data mining, machine learning and visualization.
Presentation on supervised learning
This document discusses computational intelligence and supervised learning techniques for classification. It provides examples of applications in medical diagnosis and credit card approval. The goal of supervised learning is to learn from labeled training data to predict the class of new unlabeled examples. Decision trees and backpropagation neural networks are introduced as common supervised learning algorithms. Evaluation methods like holdout validation, cross-validation and performance metrics beyond accuracy are also summarized.
Introduction to data science
This is a presentation prepared on Introduction to data science for the fulfillment of an university assignment
Machine Learning
Machine learning involves programming computers to optimize performance using example data or past experience. It is used when human expertise does not exist, humans cannot explain their expertise, solutions change over time, or solutions need to be adapted to particular cases. Learning builds general models from data to approximate real-world examples. There are several types of machine learning including supervised learning (classification, regression), unsupervised learning (clustering), and reinforcement learning. Machine learning has applications in many domains including retail, finance, manufacturing, medicine, web mining, and more.
Supervised Machine Learning
This describes the supervised machine learning, supervised learning categorisation( regression and classification) and their types, applications of supervised machine learning, etc.
Bias and variance trade off
This manuscript addresses the fundamentals of the trade-off relation between bias and variance in machine learning.
Machine learning
1. Machine learning is a set of techniques that use data to build models that can make predictions without being explicitly programmed.
2. There are two main types of machine learning: supervised learning, where the model is trained on labeled examples, and unsupervised learning, where the model finds patterns in unlabeled data.
3. Common machine learning algorithms include linear regression, logistic regression, decision trees, support vector machines, naive Bayes, k-nearest neighbors, k-means clustering, and random forests. These can be used for regression, classification, clustering, and dimensionality reduction.
Introduction to data science
Introduction to various data science. From the very beginning of data science idea, to latest designs, changing trends, technologies what make then to the application that are already in real world use as we of now.
3. mining frequent patterns
The document discusses frequent pattern mining and the Apriori algorithm. It introduces frequent patterns as frequently occurring sets of items in transaction data. The Apriori algorithm is described as a seminal method for mining frequent itemsets via multiple passes over the data, generating candidate itemsets and pruning those that are not frequent. Challenges with Apriori include multiple database scans and large number of candidate sets generated.
Machine Learning and its Applications
Machine learning and its applications was a gentle introduction to machine learning presented by Dr. Ganesh Neelakanta Iyer. The presentation covered an introduction to machine learning, different types of machine learning problems including classification, regression, and clustering. It also provided examples of applications of machine learning at companies like Facebook, Google, and McDonald's. The presentation concluded with discussing the general machine learning framework and steps involved in working with machine learning problems.
Machine learning
Machine learning is a method of data analysis that uses algorithms to iteratively learn from data without being explicitly programmed. It allows computers to find hidden insights in data and become better at tasks via experience. Machine learning has many practical applications and is important due to growing data availability, cheaper and more powerful computation, and affordable storage. It is used in fields like finance, healthcare, marketing and transportation. The main approaches are supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Each has real-world examples like loan prediction, market basket analysis, webpage classification, and marketing campaign optimization.
Foundations of Machine Learning
Machine learning is concerned with developing algorithms that learn
from experience, build models of the environment from the acquired
knowledge, and use these models for prediction. Machine learning is
usually taught as a bunch of methods that can solve a bunch of
problems (see my Introduction to SML last week). The following
tutorial takes a step back and asks about the foundations of machine
learning, in particular the (philosophical) problem of inductive inference,
(Bayesian) statistics, and arti¯cial intelligence. The tutorial concentrates
on principled, uni¯ed, and exact methods.
Introduction to Deep Learning
A fast-paced introduction to Deep Learning concepts, such as activation functions, cost functions, back propagation, and then a quick dive into CNNs. Basic knowledge of vectors, matrices, and derivatives is helpful in order to derive the maximum benefit from this session.
Semi-Supervised Learning
Review presentation about Semi-Supervised techniques in Machine Learning. Presentation was done as part of Montreal Data series.
Data mining :Concepts and Techniques Chapter 2, data
slides contain:
Data Objects and Attribute Types,
Basic Statistical Descriptions of Data,
Data Visualization,
Measuring Data Similarity and Dissimilarity,
Summary,
by
Jiawei Han, Micheline Kamber, and Jian Pei,
University of Illinois at Urbana-Champaign &
Simon Fraser University,
©2013 Han, Kamber & Pei. All rights reserved.
Introduction To Data Science
1) The document introduces data science and its core disciplines, including statistics, machine learning, predictive modeling, and database management.
2) It explains that data science uses scientific methods and algorithms to extract knowledge and insights from both structured and unstructured data.
3) The roles of data scientists are discussed, noting that they have skills in programming, statistics, analytics, business analysis, and machine learning.
Introduction to Data Science
The presentation is about the career path in the field of Data Science. Data Science is a multi-disciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data.
Statistics vs machine learning
Team knowledge sharing presentation covering topics of classical statistics vs modern machine learning including linear regression, logistic regression, neural networks, and deep learning using Python and R
Artificial Neural Network | Deep Neural Network Explained | Artificial Neural...
This presentation Neural Network will help you understand what is a neural network, how a neural network works, what can the neural network do, types of neural network and a use case implementation on how to classify between photos of dogs and cats. Deep Learning uses advanced computing power and special types of neural networks and applies them to large amounts of data to learn, understand, and identify complicated patterns. Automatic language translation and medical diagnoses are examples of deep learning. Most deep learning methods involve artificial neural networks, modeling how our brains work. Neural networks are built on Machine Learning algorithms to create an advanced computation model that works much like the human brain. This neural network tutorial is designed for beginners to provide them the basics of deep learning. Now, let us deep dive into these slides to understand how a neural network actually work.
Below topics are explained in this neural network presentation:
1. What is Neural Network?
2. What can Neural Network do?
3. How does Neural Network work?
4. Types of Neural Network
5. Use case - To classify between the photos of dogs and cats
Simplilearn’s Deep Learning course will transform you into an expert in deep learning techniques using TensorFlow, the open-source software library designed to conduct machine learning & deep neural network research. With our deep learning course, you'll master deep learning and TensorFlow concepts, learn to implement algorithms, build artificial neural networks and traverse layers of data abstraction to understand the power of data and prepare you for your new role as deep learning scientist.
Why Deep Learning?
It is one of the most popular software platforms used for deep learning and contains powerful tools to help you build and implement artificial neural networks.
Advancements in deep learning are being seen in smartphone applications, creating efficiencies in the power grid, driving advancements in healthcare, improving agricultural yields, and helping us find solutions to climate change. With this Tensorflow course, you’ll build expertise in deep learning models, learn to operate TensorFlow to manage neural networks and interpret the results.
You can gain in-depth knowledge of Deep Learning by taking our Deep Learning certification training course. With Simplilearn’s Deep Learning course, you will prepare for a career as a Deep Learning engineer as you master concepts and techniques including supervised and unsupervised learning, mathematical and heuristic aspects, and hands-on modeling to develop algorithms.
Learn more at: https://www.simplilearn.com
What Is Data Science? | Introduction to Data Science | Data Science For Begin...
This Data Science Presentation will help you in understanding what is Data Science, why we need Data Science, prerequisites for learning Data Science, what does a Data Scientist do, Data Science lifecycle with an example and career opportunities in Data Science domain. You will also learn the differences between Data Science and Business intelligence. The role of a data scientist is one of the sexiest jobs of the century. The demand for data scientists is high, and the number of opportunities for certified data scientists is increasing. Every day, companies are looking out for more and more skilled data scientists and studies show that there is expected to be a continued shortfall in qualified candidates to fill the roles. So, let us dive deep into Data Science and understand what is Data Science all about.
This Data Science Presentation will cover the following topics:
1. Need for Data Science?
2. What is Data Science?
3. Data Science vs Business intelligence
4. Prerequisites for learning Data Science
5. What does a Data scientist do?
6. Data Science life cycle with use case
7. Demand for Data scientists
This Data Science with Python course will establish your mastery of data science and analytics techniques using Python. With this Python for Data Science Course, you’ll learn the essential concepts of Python programming and become an expert in data analytics, machine learning, data visualization, web scraping and natural language processing. Python is a required skill for many data science positions, so jumpstart your career with this interactive, hands-on course.
Why learn Data Science?
Data Scientists are being deployed in all kinds of industries, creating a huge demand for skilled professionals. Data scientist is the pinnacle rank in an analytics organization. Glassdoor has ranked data scientist first in the 25 Best Jobs for 2016, and good data scientists are scarce and in great demand. As a data you will be required to understand the business problem, design the analysis, collect and format the required data, apply algorithms or techniques using the correct tools, and finally make recommendations backed by data.
The Data Science with python is recommended for:
1. Analytics professionals who want to work with Python
2. Software professionals looking to get into the field of analytics
3. IT professionals interested in pursuing a career in analytics
4. Graduates looking to build a career in analytics and data science
5. Experienced professionals who would like to harness data science in their fields
Just Count the Love-Hate Squares
This document proposes a method for recommender systems that counts different configurations ("squares") in the user-item bipartite rating network to predict whether a user will rate an item highly. It involves counting the number of each configuration for every user-item pair to generate features, then training a machine learning classifier on these features. The method was applied to the KDD Cup 2011 Yahoo! Music Dataset competition and achieved competitive results, with enhancements like normalizing against random networks and separating counts based on item hierarchy. Interestingly, configurations involving "hate" edges were most predictive of a user's potential love for an item.
Gaming product name, genre
The document discusses 5 video games - Counter Strike, Need for Speed, Call of Duty, Slender Man, and Halo. For each game, it provides the product name, genre, and any notes on codes of conventions. The genres included are first person shooter, racing, and horror. Codes of conventions are discussed for some games and refer to how meaning is created through technical and symbolic signs and systems in games and websites.
More Related Content
What's hot
Data Science
The document provides an overview of key concepts in data science including data types, the data value chain, and big data. It defines data science as extracting insights from large, diverse datasets using tools like machine learning. The data value chain involves acquiring, processing, analyzing and using data. Big data is characterized by its volume, velocity and variety. Common techniques for big data analytics include data mining, machine learning and visualization.
Presentation on supervised learning
This document discusses computational intelligence and supervised learning techniques for classification. It provides examples of applications in medical diagnosis and credit card approval. The goal of supervised learning is to learn from labeled training data to predict the class of new unlabeled examples. Decision trees and backpropagation neural networks are introduced as common supervised learning algorithms. Evaluation methods like holdout validation, cross-validation and performance metrics beyond accuracy are also summarized.
Introduction to data science
This is a presentation prepared on Introduction to data science for the fulfillment of an university assignment
Machine Learning
Machine learning involves programming computers to optimize performance using example data or past experience. It is used when human expertise does not exist, humans cannot explain their expertise, solutions change over time, or solutions need to be adapted to particular cases. Learning builds general models from data to approximate real-world examples. There are several types of machine learning including supervised learning (classification, regression), unsupervised learning (clustering), and reinforcement learning. Machine learning has applications in many domains including retail, finance, manufacturing, medicine, web mining, and more.
Supervised Machine Learning
This describes the supervised machine learning, supervised learning categorisation( regression and classification) and their types, applications of supervised machine learning, etc.
Bias and variance trade off
This manuscript addresses the fundamentals of the trade-off relation between bias and variance in machine learning.
Machine learning
1. Machine learning is a set of techniques that use data to build models that can make predictions without being explicitly programmed.
2. There are two main types of machine learning: supervised learning, where the model is trained on labeled examples, and unsupervised learning, where the model finds patterns in unlabeled data.
3. Common machine learning algorithms include linear regression, logistic regression, decision trees, support vector machines, naive Bayes, k-nearest neighbors, k-means clustering, and random forests. These can be used for regression, classification, clustering, and dimensionality reduction.
Introduction to data science
Introduction to various data science. From the very beginning of data science idea, to latest designs, changing trends, technologies what make then to the application that are already in real world use as we of now.
3. mining frequent patterns
The document discusses frequent pattern mining and the Apriori algorithm. It introduces frequent patterns as frequently occurring sets of items in transaction data. The Apriori algorithm is described as a seminal method for mining frequent itemsets via multiple passes over the data, generating candidate itemsets and pruning those that are not frequent. Challenges with Apriori include multiple database scans and large number of candidate sets generated.
Machine Learning and its Applications
Machine learning and its applications was a gentle introduction to machine learning presented by Dr. Ganesh Neelakanta Iyer. The presentation covered an introduction to machine learning, different types of machine learning problems including classification, regression, and clustering. It also provided examples of applications of machine learning at companies like Facebook, Google, and McDonald's. The presentation concluded with discussing the general machine learning framework and steps involved in working with machine learning problems.
Machine learning
Machine learning is a method of data analysis that uses algorithms to iteratively learn from data without being explicitly programmed. It allows computers to find hidden insights in data and become better at tasks via experience. Machine learning has many practical applications and is important due to growing data availability, cheaper and more powerful computation, and affordable storage. It is used in fields like finance, healthcare, marketing and transportation. The main approaches are supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Each has real-world examples like loan prediction, market basket analysis, webpage classification, and marketing campaign optimization.
Foundations of Machine Learning
Machine learning is concerned with developing algorithms that learn
from experience, build models of the environment from the acquired
knowledge, and use these models for prediction. Machine learning is
usually taught as a bunch of methods that can solve a bunch of
problems (see my Introduction to SML last week). The following
tutorial takes a step back and asks about the foundations of machine
learning, in particular the (philosophical) problem of inductive inference,
(Bayesian) statistics, and arti¯cial intelligence. The tutorial concentrates
on principled, uni¯ed, and exact methods.
Introduction to Deep Learning
A fast-paced introduction to Deep Learning concepts, such as activation functions, cost functions, back propagation, and then a quick dive into CNNs. Basic knowledge of vectors, matrices, and derivatives is helpful in order to derive the maximum benefit from this session.
Semi-Supervised Learning
Review presentation about Semi-Supervised techniques in Machine Learning. Presentation was done as part of Montreal Data series.
Data mining :Concepts and Techniques Chapter 2, data
slides contain:
Data Objects and Attribute Types,
Basic Statistical Descriptions of Data,
Data Visualization,
Measuring Data Similarity and Dissimilarity,
Summary,
by
Jiawei Han, Micheline Kamber, and Jian Pei,
University of Illinois at Urbana-Champaign &
Simon Fraser University,
©2013 Han, Kamber & Pei. All rights reserved.
Introduction To Data Science
1) The document introduces data science and its core disciplines, including statistics, machine learning, predictive modeling, and database management.
2) It explains that data science uses scientific methods and algorithms to extract knowledge and insights from both structured and unstructured data.
3) The roles of data scientists are discussed, noting that they have skills in programming, statistics, analytics, business analysis, and machine learning.
Introduction to Data Science
The presentation is about the career path in the field of Data Science. Data Science is a multi-disciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data.
Statistics vs machine learning
Team knowledge sharing presentation covering topics of classical statistics vs modern machine learning including linear regression, logistic regression, neural networks, and deep learning using Python and R
Artificial Neural Network | Deep Neural Network Explained | Artificial Neural...
This presentation Neural Network will help you understand what is a neural network, how a neural network works, what can the neural network do, types of neural network and a use case implementation on how to classify between photos of dogs and cats. Deep Learning uses advanced computing power and special types of neural networks and applies them to large amounts of data to learn, understand, and identify complicated patterns. Automatic language translation and medical diagnoses are examples of deep learning. Most deep learning methods involve artificial neural networks, modeling how our brains work. Neural networks are built on Machine Learning algorithms to create an advanced computation model that works much like the human brain. This neural network tutorial is designed for beginners to provide them the basics of deep learning. Now, let us deep dive into these slides to understand how a neural network actually work.
Below topics are explained in this neural network presentation:
1. What is Neural Network?
2. What can Neural Network do?
3. How does Neural Network work?
4. Types of Neural Network
5. Use case - To classify between the photos of dogs and cats
Simplilearn’s Deep Learning course will transform you into an expert in deep learning techniques using TensorFlow, the open-source software library designed to conduct machine learning & deep neural network research. With our deep learning course, you'll master deep learning and TensorFlow concepts, learn to implement algorithms, build artificial neural networks and traverse layers of data abstraction to understand the power of data and prepare you for your new role as deep learning scientist.
Why Deep Learning?
It is one of the most popular software platforms used for deep learning and contains powerful tools to help you build and implement artificial neural networks.
Advancements in deep learning are being seen in smartphone applications, creating efficiencies in the power grid, driving advancements in healthcare, improving agricultural yields, and helping us find solutions to climate change. With this Tensorflow course, you’ll build expertise in deep learning models, learn to operate TensorFlow to manage neural networks and interpret the results.
You can gain in-depth knowledge of Deep Learning by taking our Deep Learning certification training course. With Simplilearn’s Deep Learning course, you will prepare for a career as a Deep Learning engineer as you master concepts and techniques including supervised and unsupervised learning, mathematical and heuristic aspects, and hands-on modeling to develop algorithms.
Learn more at: https://www.simplilearn.com
What Is Data Science? | Introduction to Data Science | Data Science For Begin...
This Data Science Presentation will help you in understanding what is Data Science, why we need Data Science, prerequisites for learning Data Science, what does a Data Scientist do, Data Science lifecycle with an example and career opportunities in Data Science domain. You will also learn the differences between Data Science and Business intelligence. The role of a data scientist is one of the sexiest jobs of the century. The demand for data scientists is high, and the number of opportunities for certified data scientists is increasing. Every day, companies are looking out for more and more skilled data scientists and studies show that there is expected to be a continued shortfall in qualified candidates to fill the roles. So, let us dive deep into Data Science and understand what is Data Science all about.
This Data Science Presentation will cover the following topics:
1. Need for Data Science?
2. What is Data Science?
3. Data Science vs Business intelligence
4. Prerequisites for learning Data Science
5. What does a Data scientist do?
6. Data Science life cycle with use case
7. Demand for Data scientists
This Data Science with Python course will establish your mastery of data science and analytics techniques using Python. With this Python for Data Science Course, you’ll learn the essential concepts of Python programming and become an expert in data analytics, machine learning, data visualization, web scraping and natural language processing. Python is a required skill for many data science positions, so jumpstart your career with this interactive, hands-on course.
Why learn Data Science?
Data Scientists are being deployed in all kinds of industries, creating a huge demand for skilled professionals. Data scientist is the pinnacle rank in an analytics organization. Glassdoor has ranked data scientist first in the 25 Best Jobs for 2016, and good data scientists are scarce and in great demand. As a data you will be required to understand the business problem, design the analysis, collect and format the required data, apply algorithms or techniques using the correct tools, and finally make recommendations backed by data.
The Data Science with python is recommended for:
1. Analytics professionals who want to work with Python
2. Software professionals looking to get into the field of analytics
3. IT professionals interested in pursuing a career in analytics
4. Graduates looking to build a career in analytics and data science
5. Experienced professionals who would like to harness data science in their fields
What's hot (20)
Data mining :Concepts and Techniques Chapter 2, data
Data mining :Concepts and Techniques Chapter 2, data
Artificial Neural Network | Deep Neural Network Explained | Artificial Neural...
Artificial Neural Network | Deep Neural Network Explained | Artificial Neural...
What Is Data Science? | Introduction to Data Science | Data Science For Begin...
What Is Data Science? | Introduction to Data Science | Data Science For Begin...
Similar to ML Label engineering and N-Hot Encoders
Just Count the Love-Hate Squares
This document proposes a method for recommender systems that counts different configurations ("squares") in the user-item bipartite rating network to predict whether a user will rate an item highly. It involves counting the number of each configuration for every user-item pair to generate features, then training a machine learning classifier on these features. The method was applied to the KDD Cup 2011 Yahoo! Music Dataset competition and achieved competitive results, with enhancements like normalizing against random networks and separating counts based on item hierarchy. Interestingly, configurations involving "hate" edges were most predictive of a user's potential love for an item.
Gaming product name, genre
The document discusses 5 video games - Counter Strike, Need for Speed, Call of Duty, Slender Man, and Halo. For each game, it provides the product name, genre, and any notes on codes of conventions. The genres included are first person shooter, racing, and horror. Codes of conventions are discussed for some games and refer to how meaning is created through technical and symbolic signs and systems in games and websites.
MLBox
MLBox is a fully automated machine learning pipeline that cleans, preprocesses, models, and analyzes data. It features include reading and cleaning data, encoding categorical features, feature engineering, hyperparameter tuning, model validation, and interpreting results. MLBox addresses issues like data drift over time by detecting drifting features and selectively removing them if they negatively impact model performance. It also uses entity embeddings to learn low-dimensional vector representations of categorical features, providing an accurate, scalable, and interpretable encoding method. This technique was tested on a large automotive insurance dataset and improved both model accuracy and understanding of feature relationships.
Secure 2 Party AES
This Presentation highlights the project in which i am currently working on.
Secure 2-party AES:
AES is one of the most widely used block cipher.It takes a secret key as input and a message block to be encrypted and generates the ciphertext corresponding to the message, without disclosing anything about the key or the message.
Typically the key and the message to be encrypted are available with a single entity.
Now consider a scenario where we have two parties, one holding the secret key and the other holding the message to be encrypted.
We want to design a protocol such that at the end of the protocol, the second party learns the encryption of the message (and no information about the key) while the first party learns nothing about the encrypted message.
The goal of this project will be to implement such a protocol.
R user group meeting 25th jan 2017
Using R in Kaggle Competitions.
Kaggle has been the most popular data science platform linking close to half a million of data scientists worldwide. How to get yourself a decent ranking on Kaggle competitions with R programming, eXtreme Gradient BOOSTing, and a laptop. Great machine learning tools for all levels to get started and learn. Find out how to perform features engineering, tuning XGB models, selecting a sizable cross validations and performing model ensembles.
SSD: Single Shot MultiBox Detector (UPC Reading Group)
Slides by Míriam Bellver at the UPC Reading group for the paper:
Liu, Wei, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, and Scott Reed. "SSD: Single Shot MultiBox Detector." ECCV 2016.
Full listing of papers at:
https://github.com/imatge-upc/readcv/blob/master/README.md
A More Scaleable Way of Making Recommendations with MLlib-(Xiangrui Meng, Dat...
This document summarizes the implementation of Alternating Least Squares (ALS) in MLlib to make recommendations at scale. It discusses how MLlib reduces communication cost through a block-to-block approach and compressed storage formats. It also describes optimizations like avoiding garbage collection through specialized code. The ALS algorithm is tested on real-world datasets including Amazon reviews and Spotify music data involving billions of ratings.
MLSEV. Logistic Regression, Deepnets, and Time Series
Supervised Learning (Part II): Logistic Regression, Deepnets, and Time Series, by BigML.
MLSEV 2019: 1st edition of the Machine Learning School in Seville, Spain.
Feature Engineering in H2O Driverless AI - Dmitry Larko - H2O AI World London...
The document discusses feature engineering techniques for machine learning models. It describes how feature engineering involves extracting new features from existing data, removing irrelevant features, and transforming features to simplify models and improve results. Specific techniques discussed include handling missing numerical values, encoding categorical features, and target mean encoding to represent categorical levels based on their relationship to the target variable. The document advocates using techniques like leave-one-out encoding and smoothing to add noise and avoid overfitting during feature engineering.
DynamoDB Design Workshop
by Edin Zulich, NoSQL Solutions Architect, AWS
Following the DynamoDB Deep Dive session, this workshop is a design session (no computer needed) in which we will work through several real world DynamoDB use cases. For each one, we will go over the requirements, propose and analyze possible solutions and their pros and cons, with an eye for performance efficiency, scalability, and cost optimization. Level: 300
Similar to ML Label engineering and N-Hot Encoders (10)
SSD: Single Shot MultiBox Detector (UPC Reading Group)
SSD: Single Shot MultiBox Detector (UPC Reading Group)
A More Scaleable Way of Making Recommendations with MLlib-(Xiangrui Meng, Dat...
A More Scaleable Way of Making Recommendations with MLlib-(Xiangrui Meng, Dat...
MLSEV. Logistic Regression, Deepnets, and Time Series
MLSEV. Logistic Regression, Deepnets, and Time Series
Feature Engineering in H2O Driverless AI - Dmitry Larko - H2O AI World London...
Feature Engineering in H2O Driverless AI - Dmitry Larko - H2O AI World London...
Recently uploaded
原版制作(swinburne毕业证书)斯威本科技大学毕业证毕业完成信一模一样
学校原件一模一样【微信:741003700 】《(swinburne毕业证书)斯威本科技大学毕业证》【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
一比一原版(UIUC毕业证)伊利诺伊大学|厄巴纳-香槟分校毕业证如何办理
UIUC毕业证offer【微信95270640】☀《伊利诺伊大学|厄巴纳-香槟分校毕业证购买》GoogleQ微信95270640《UIUC毕业证模板办理》加拿大文凭、本科、硕士、研究生学历都可以做,二、业务范围:
★、全套服务:毕业证、成绩单、化学专业毕业证书伪造《伊利诺伊大学|厄巴纳-香槟分校大学毕业证》Q微信95270640《UIUC学位证书购买》
(诚招代理)办理国外高校毕业证成绩单文凭学位证,真实使馆公证(留学回国人员证明)真实留信网认证国外学历学位认证雅思代考国外学校代申请名校保录开请假条改GPA改成绩ID卡
1.高仿业务:【本科硕士】毕业证,成绩单(GPA修改),学历认证(教育部认证),大学Offer,,ID,留信认证,使馆认证,雅思,语言证书等高仿类证书;
2.认证服务: 学历认证(教育部认证),大使馆认证(回国人员证明),留信认证(可查有编号证书),大学保录取,雅思保分成绩单。
3.技术服务:钢印水印烫金激光防伪凹凸版设计印刷激凸温感光标底纹镭射速度快。
办理伊利诺伊大学|厄巴纳-香槟分校伊利诺伊大学|厄巴纳-香槟分校毕业证offer流程:
1客户提供办理信息:姓名生日专业学位毕业时间等(如信息不确定可以咨询顾问:我们有专业老师帮你查询);
2开始安排制作毕业证成绩单电子图;
3毕业证成绩单电子版做好以后发送给您确认;
4毕业证成绩单电子版您确认信息无误之后安排制作成品;
5成品做好拍照或者视频给您确认;
6快递给客户(国内顺丰国外DHLUPS等快读邮寄)
-办理真实使馆公证(即留学回国人员证明)
-办理各国各大学文凭(世界名校一对一专业服务,可全程监控跟踪进度)
-全套服务:毕业证成绩单真实使馆公证真实教育部认证。让您回国发展信心十足!
(详情请加一下 文凭顾问+微信:95270640)欢迎咨询!的鬼地方父亲的家在高楼最底屋最下面很矮很黑是很不显眼的地下室父亲的家安在别人脚底下须绕过高楼旁边的垃圾堆下八个台阶才到父亲的家很狭小除了一张单人床和一张小方桌几乎没有多余的空间山娃一下子就联想起学校的男小便处山娃很想笑却怎么也笑不出来山娃很迷惑父亲的家除了一扇小铁门连窗户也没有墓穴一般阴森森有些骇人父亲的城也便成了山娃的城父亲的家也便成了山娃的家父亲让山娃呆在屋里做作业看电视最多只能在门口透透气间
The Building Blocks of QuestDB, a Time Series Database
Talk Delivered at Valencia Codes Meetup 2024-06.
Traditionally, databases have treated timestamps just as another data type. However, when performing real-time analytics, timestamps should be first class citizens and we need rich time semantics to get the most out of our data. We also need to deal with ever growing datasets while keeping performant, which is as fun as it sounds.
It is no wonder time-series databases are now more popular than ever before. Join me in this session to learn about the internal architecture and building blocks of QuestDB, an open source time-series database designed for speed. We will also review a history of some of the changes we have gone over the past two years to deal with late and unordered data, non-blocking writes, read-replicas, or faster batch ingestion.
一比一原版(BCU毕业证书)伯明翰城市大学毕业证如何办理
原版定制【微信:41543339】【(BCU毕业证书)伯明翰城市大学毕业证】【微信:41543339】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信41543339】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信41543339】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
一比一原版(UniSA毕业证书)南澳大学毕业证如何办理
原版定制【微信:41543339】【(UniSA毕业证书)南澳大学毕业证】【微信:41543339】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信41543339】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信41543339】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
06-04-2024 - NYC Tech Week - Discussion on Vector Databases, Unstructured Dat...
06-04-2024 - NYC Tech Week - Discussion on Vector Databases, Unstructured Data and AI
Discussion on Vector Databases, Unstructured Data and AI
https://www.meetup.com/unstructured-data-meetup-new-york/
This meetup is for people working in unstructured data. Speakers will come present about related topics such as vector databases, LLMs, and managing data at scale. The intended audience of this group includes roles like machine learning engineers, data scientists, data engineers, software engineers, and PMs.This meetup was formerly Milvus Meetup, and is sponsored by Zilliz maintainers of Milvus.
一比一原版(牛布毕业证书)牛津布鲁克斯大学毕业证如何办理
毕业原版【微信:41543339】【(牛布毕业证书)牛津布鲁克斯大学毕业证】【微信:41543339】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信41543339】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信41543339】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
一比一原版(UO毕业证)渥太华大学毕业证如何办理
UO毕业证录取书【微信95270640】购买(渥太华大学毕业证成绩单硕士学历)Q微信95270640代办UO学历认证留信网伪造渥太华大学学位证书精仿渥太华大学本科/硕士文凭证书补办渥太华大学 diplomaoffer,Transcript购买渥太华大学毕业证成绩单购买UO假毕业证学位证书购买伪造渥太华大学文凭证书学位证书,专业办理雅思、托福成绩单,学生ID卡,在读证明,海外各大学offer录取通知书,毕业证书,成绩单,文凭等材料:1:1完美还原毕业证、offer录取通知书、学生卡等各种在读或毕业材料的防伪工艺(包括 烫金、烫银、钢印、底纹、凹凸版、水印、防伪光标、热敏防伪、文字图案浮雕,激光镭射,紫外荧光,温感光标)学校原版上有的工艺我们一样不会少,不论是老版本还是最新版本,都能保证最高程度还原,力争完美以求让所有同学都能享受到完美的品质服务。
文凭办理流程:
1客户提供办理信息:姓名生日专业学位毕业时间等(如信息不确定可以咨询顾问:微信95270640我们有专业老师帮你查询);
2开始安排制作毕业证成绩单电子图;
3毕业证成绩单电子版做好以后发送给您确认;
4毕业证成绩单电子版您确认信息无误之后安排制作成品;
5成品做好拍照或者视频给您确认;
6快递给客户(国内顺丰国外DHLUPS等快读邮寄)。
7完成交易删除客户资料
高精端提供以下服务:
一:渥太华大学渥太华大学毕业证文凭证书全套材料从防伪到印刷水印底纹到钢印烫金
二:真实使馆认证(留学人员回国证明)使馆存档
三:真实教育部认证教育部存档教育部留服网站可查
四:留信认证留学生信息网站可查
五:与学校颁发的相关证件1:1纸质尺寸制定(定期向各大院校毕业生购买最新版本毕,业证成绩单保证您拿到的是鲁昂大学内部最新版本毕业证成绩单微信95270640)
A.为什么留学生需要操作留信认证?
留信认证全称全国留学生信息服务网认证,隶属于北京中科院。①留信认证门槛条件更低,费用更美丽,并且包过,完单周期短,效率高②留信认证虽然不能去国企,但是一般的公司都没有问题,因为国内很多公司连基本的留学生学历认证都不了解。这对于留学生来说,这就比自己光拿一个证书更有说服力,因为留学学历可以在留信网站上进行查询!
B.为什么我们提供的毕业证成绩单具有使用价值?
查询留服认证是国内鉴别留学生海外学历的唯一途径但认证只是个体行为不是所有留学生都操作所以没有办理认证的留学生的学历在国内也是查询不到的他们也仅仅只有一张文凭。所以这时候我们提供的和学校颁发的一模一样的毕业证成绩单就有了使用价值。只硕大的蛇皮袋手里拎着长铁钩正站在门口朝黑色的屋内张望不好坏人小偷山娃一怔却也灵机一动立马仰起头双手拢在嘴边朝楼上大喊:“爸爸爸——有人找——那人一听朝山娃尴尬地笑笑悻悻地走了山娃立马“嘭的一声将铁门锁死心却咚咚地乱跳当山娃跟父亲说起这事时父亲很吃惊抚摸着山娃的头说还好醒得及时要不家早被人掏空了到时连电视也没得看啰不过父亲还是夸山娃能临危不乱随机应变有胆有谋山娃笑笑说那都是书上学的看童话和小说时多
Enhanced Enterprise Intelligence with your personal AI Data Copilot.pdf
Recently we have observed the rise of open-source Large Language Models (LLMs) that are community-driven or developed by the AI market leaders, such as Meta (Llama3), Databricks (DBRX) and Snowflake (Arctic). On the other hand, there is a growth in interest in specialized, carefully fine-tuned yet relatively small models that can efficiently assist programmers in day-to-day tasks. Finally, Retrieval-Augmented Generation (RAG) architectures have gained a lot of traction as the preferred approach for LLMs context and prompt augmentation for building conversational SQL data copilots, code copilots and chatbots.
In this presentation, we will show how we built upon these three concepts a robust Data Copilot that can help to democratize access to company data assets and boost performance of everyone working with data platforms.
Why do we need yet another (open-source ) Copilot?
How can we build one?
Architecture and evaluation
在线办理(英国UCA毕业证书)创意艺术大学毕业证在读证明一模一样
学校原件一模一样【微信:741003700 】《(英国UCA毕业证书)创意艺术大学毕业证》【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
University of New South Wales degree offer diploma Transcript
澳洲UNSW毕业证书制作新南威尔士大学假文凭定制Q微168899991做UNSW留信网教留服认证海牙认证改UNSW成绩单GPA做UNSW假学位证假文凭高仿毕业证申请新南威尔士大学University of New South Wales degree offer diploma Transcript
一比一原版(Glasgow毕业证书)格拉斯哥大学毕业证如何办理
毕业原版【微信:41543339】【(Glasgow毕业证书)格拉斯哥大学毕业证】【微信:41543339】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信41543339】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信41543339】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
一比一原版(爱大毕业证书)爱丁堡大学毕业证如何办理
毕业原版【微信:41543339】【(爱大毕业证书)爱丁堡大学毕业证】【微信:41543339】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信41543339】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信41543339】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
STATATHON: Unleashing the Power of Statistics in a 48-Hour Knowledge Extravag...
"Join us for STATATHON, a dynamic 2-day event dedicated to exploring statistical knowledge and its real-world applications. From theory to practice, participants engage in intensive learning sessions, workshops, and challenges, fostering a deeper understanding of statistical methodologies and their significance in various fields."
一比一原版(Coventry毕业证书)考文垂大学毕业证如何办理
毕业原版【微信:41543339】【(Coventry毕业证书)考文垂大学毕业证】【微信:41543339】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信41543339】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信41543339】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
Population Growth in Bataan: The effects of population growth around rural pl...
A population analysis specific to Bataan.
一比一原版(UCSB文凭证书)圣芭芭拉分校毕业证如何办理
毕业原版【微信:176555708】【(UCSB毕业证书)圣芭芭拉分校毕业证】【微信:176555708】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信176555708】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信176555708】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
Recently uploaded (20)
Influence of Marketing Strategy and Market Competition on Business Plan
Influence of Marketing Strategy and Market Competition on Business Plan
The Building Blocks of QuestDB, a Time Series Database
The Building Blocks of QuestDB, a Time Series Database
06-04-2024 - NYC Tech Week - Discussion on Vector Databases, Unstructured Dat...
06-04-2024 - NYC Tech Week - Discussion on Vector Databases, Unstructured Dat...
Enhanced Enterprise Intelligence with your personal AI Data Copilot.pdf
Enhanced Enterprise Intelligence with your personal AI Data Copilot.pdf
University of New South Wales degree offer diploma Transcript
University of New South Wales degree offer diploma Transcript
STATATHON: Unleashing the Power of Statistics in a 48-Hour Knowledge Extravag...
STATATHON: Unleashing the Power of Statistics in a 48-Hour Knowledge Extravag...
Population Growth in Bataan: The effects of population growth around rural pl...
Population Growth in Bataan: The effects of population growth around rural pl...
ML Label engineering and N-Hot Encoders
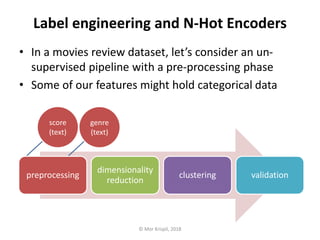
- 1. Label engineering and N-Hot Encoders • In a movies review dataset, let’s consider an un- supervised pipeline with a pre-processing phase • Some of our features might hold categorical data preprocessing dimensionality reduction clustering validation © Mor Krispil, 2018 score (text) genre (text)
- 2. Label engineering – Categorical features • In a movies review dataset, let’s consider an un- supervised pipeline with a pre-processing phase • Some of our features might hold categorical data © Mor Krispil, 2018 name score genre Super Kill high action Music and more medium musical UFO Invasion 2 low sci-fi
- 3. Label engineering – Label Encoding Each unique label is coded with a running int. For ex: • Score: (“low”, “medium”, “high”) => (1, 2, 3) • Genre: (“action”, “musical”, “sci-fi”) => (1, 2, 3) Each label feature is replaced with a numeric feature: X (m, n) => Xt (m, n) © Mor Krispil, 2018 name score genre Super Kill 3 1 Music and more 2 2 UFO Invasion 2 1 3
- 4. Label Encoding - Review Pros: • Simple implementation (ex: scikit LabelEncoder) • Dataset shape and density stays the same Limitations: • New label values should be meticulously coded with that running int • Can only be used with labels when order is meaningful! – “medium” (2) is indeed > “low” (1) – But.. does “sci-fi” (3) > “musical” (2)?? © Mor Krispil, 2018
- 5. Label engineering – One Hot Encoding Each unique label is assigned with a new binary feature, in which 1 represents its existence. • For ex: our Genre feature is transformed into 3 binary features: For m rows with n label-features X (m, n) => Xt (m, 1st_unique_vals + ... + nth_uni_vals) © Mor Krispil, 2018 name genre_action genre_musical genre_sci-ifi Super Kill 1 0 0 Music and more 0 1 0 UFO Invasion 2 0 0 1
- 6. One Hot Encoding - Review Pros: • New label values can be stacked later as additional features • Built in implenetation of both scikit (OneHotEncoder) and pandas (get_dummies) Limitations: • Good for few label values per feature (ENUM like) • Feature “explosion” and the Curse of Dimensionality with many values © Mor Krispil, 2018
- 7. Label Encoding – prefer One Hot Encoding • Even with many label values – the resulting matrix is highly sparse • Late scikit versions support sparse DataFrames out of the box (not just scipy csr_matrix anymore ) © Mor Krispil, 2018 preprocessing dimensionality reduction clustering validation Hot Encod.
- 8. Label Encoding – prefer One Hot Encoding • We can then apply “sparse friendly” Dimensionality Reduction, like scikit TruncatedSVD, which is less sensitive to data normalization – thus your matrix gets to stay sparse! © Mor Krispil, 2018 preprocessing dimensionality reduction clustering validation Hot Encod. Trunc. SVD
- 9. Label Encoding – Multi / Weighted Labels But what can we do with multiple labels per feature? • Scenario 1: from our current dataset: © Mor Krispil, 2018 name score genre Super Kill high action Music and more medium musical UFO Invasion 2 low sci-fi Killing Me Softly high action, comedy
- 10. Label Encoding – Multi / Weighted Labels Also, in the preprocessing phase we’d sometimes like to aggregate rows per some entity. What can we do with multiple occurrences of the same value? A weighted representation? • Scenario 2: In a user watch-list dataset, we’d like to aggregate the genres watched, per user © Mor Krispil, 2018 user movie genre sam Super Kill action sam Super Kill 2 action sam Music and more musical user Genres sam ??
- 11. Label Encoding and N-Hot Encoders N-Hot Encoding suggests that each unique label is assigned with a new numeric feature, in which 1-N value represents existence and weight. © Mor Krispil, 2018 user genre_action genre_musical genre_sci-ifi sam 2 1 0 musical_dude 0 10 0 scully 5 0 20
- 12. N-Hot Encoders - Review Pros: • Weighted categorical features, model ready • Resulting data shape and sparsity is the same as with One-Hot Limitations: • Same as with One-Hot • No built-in implementations • A little bit extra weight - features are numeric, not binary. Use the minimum int size required © Mor Krispil, 2018
- 13. Label Encoding and N-Hot Encoders Thanks © Mor Krispil, 2018 preprocessing dimensionality reduction clustering validation N-Hot Encod. Trunc. SVD