Downloaded 37 times











![Easy to use
scala> :paste
// Entering paste mode (ctrl-D to finish)
val gscOptionMap = Map(
"url" -> "jdbc:postgresql://gpmaster.domain/tutorial",
"user" -> "user1",
"password" -> "pivotal",
"dbschema" -> "faa",
"dbtable" -> "otp_c",
"partitionColumn" -> "airlineid"
)
val gpdf = spark.read.format("greenplum")
.options(gscOptionMap)
.load()
// Exiting paste mode, now interpreting.
gpdf: org.apache.spark.sql.DataFrame = [flt_year: smallint, flt_quarter: smallint ... 44 more fields]](https://image.slidesharecdn.com/greenplumsparkwebinar16thaugust2018powerpoint-180816214125/85/Mixing-Analytic-Workloads-with-Greenplum-and-Apache-Spark-14-320.jpg)


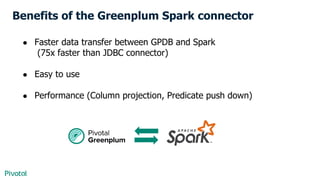




This document discusses mixing analytic workloads between Greenplum and Apache Spark. It recommends using Greenplum for large-scale data processing and queries over entire datasets, while using Spark for in-memory processing, data exploration, and ETL workloads involving streaming or micro-batches of data. It introduces the Greenplum-Spark connector for high-speed parallel data transfer between the two systems and optimizing performance through column projection and predicate pushdown. The key benefits are faster data transfer and leveraging the strengths of both platforms for mixed workloads.






















































































