The document discusses new features in IBM Information Server/DataStage 11.3. Key points include:
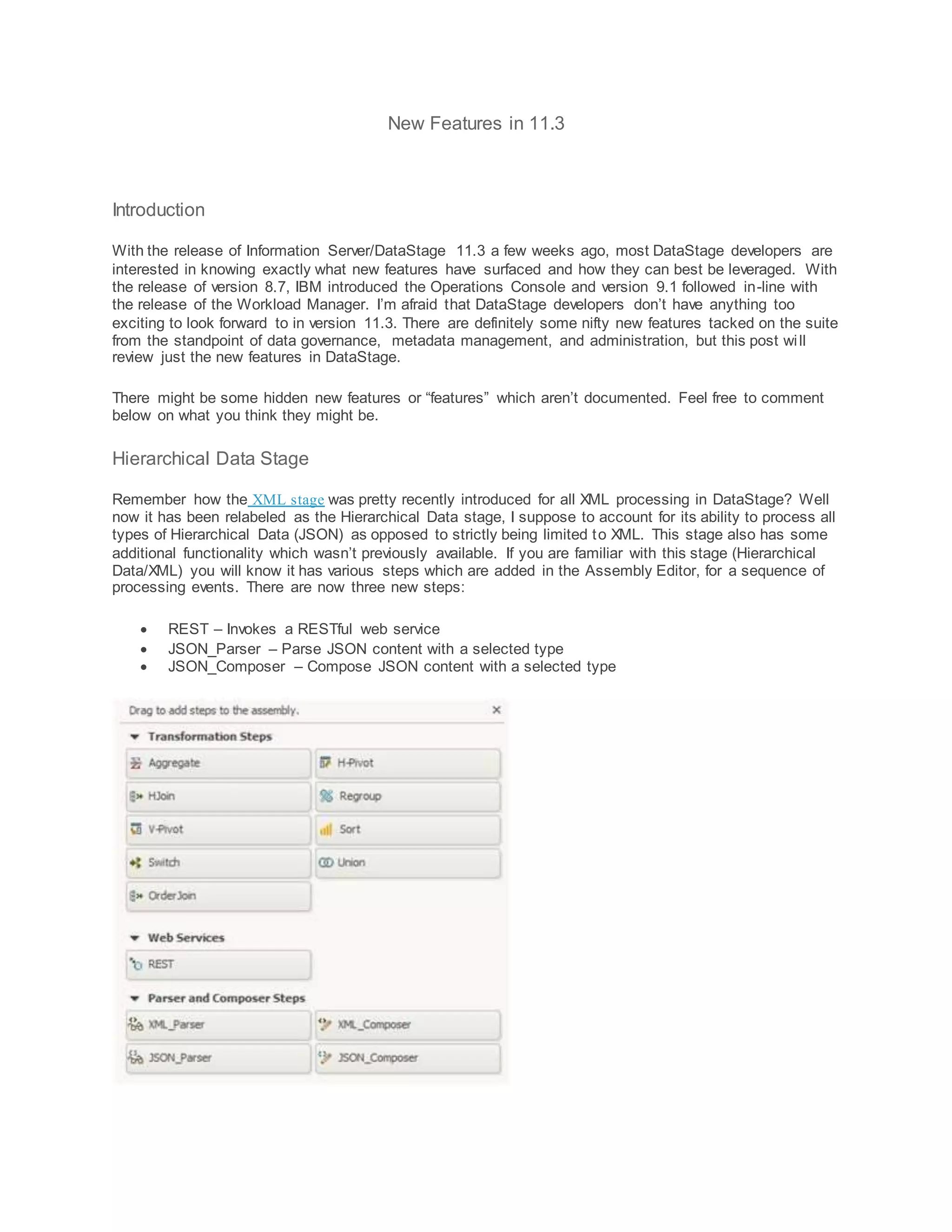
- The Hierarchical Data stage was renamed and can now process JSON and includes new REST, JSON parsing, and composition steps.
- The Big Data File stage supports more Hadoop distributions and Greenplum and Master Data Management connector stages were added.
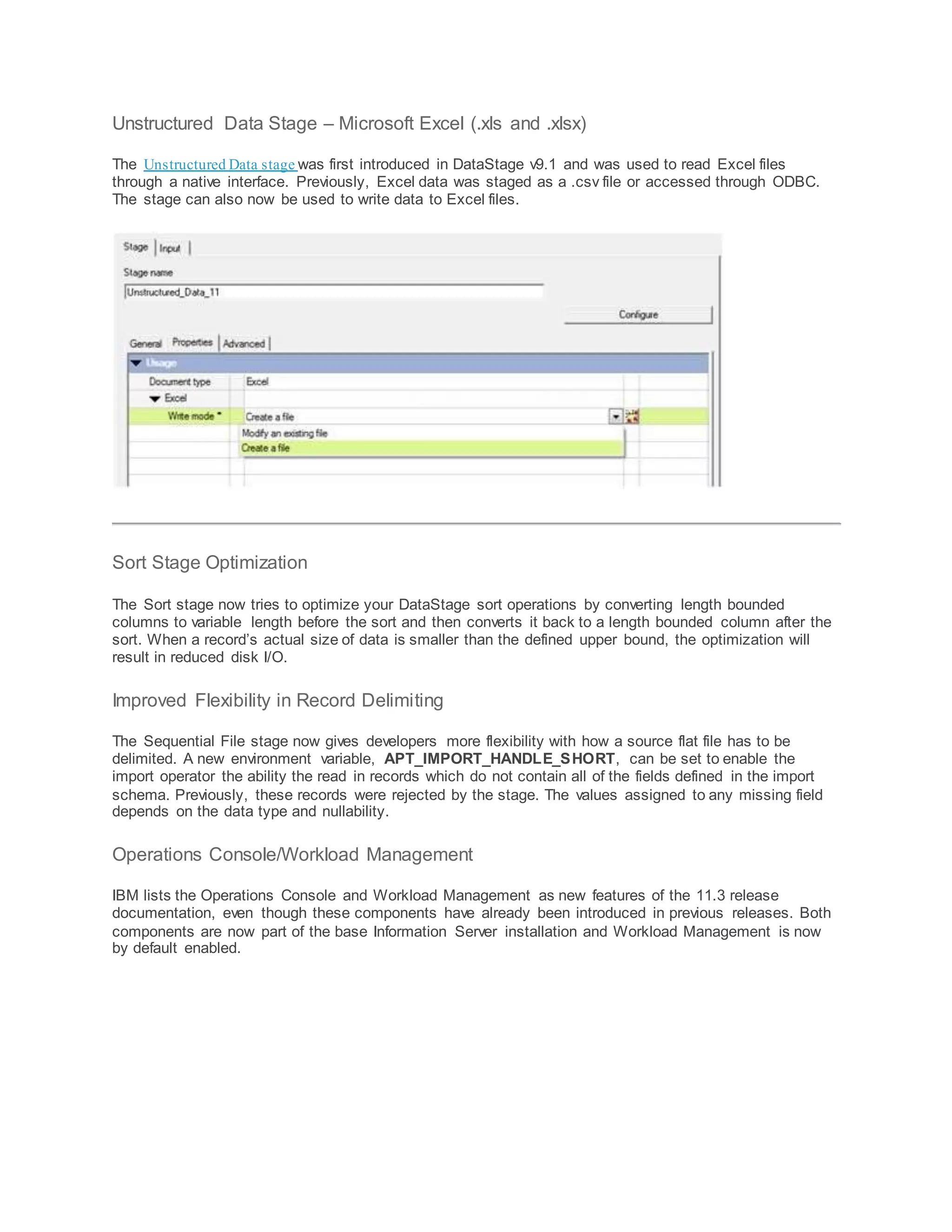
- The Amazon S3 and Microsoft Excel connectors were enhanced.
- Sorting and record delimiting were optimized and Operations Console/Workload Manager are now default features.