Download to read offline















![Schema
{!
st: "u724463",!
ts: ISODate("1991-01-01T00:00:00Z"),!
position: {!
type: "Point",!
coordinates: [!
-94.6,!
39.117!
]!
},!
elevation: 231,!
… other fields …!
}!
station ID and source](https://image.slidesharecdn.com/midwest-140715160818-phpapp02/85/A-Century-Of-Weather-Data-Midwest-io-21-320.jpg)
![Schema
{!
st: "u724463",!
ts: ISODate("1991-01-01T00:00:00Z"),!
position: {!
type: "Point",!
coordinates: [!
-94.6,!
39.117!
]!
},!
elevation: 231,!
… other fields …!
}!
GeoJSON](https://image.slidesharecdn.com/midwest-140715160818-phpapp02/85/A-Century-Of-Weather-Data-Midwest-io-23-320.jpg)










![Aggregation
pipeline = [{!
'$match': {!
'ts': {!
'$gte': dt,!
'$lt': dt + timedelta(hours=1)},!
'airTemperature.quality': {!
'$in': ['0', '1', '5', '9']}!
}!
}, {!
'$group': {!
'_id': '$st',!
'position': {'$first': '$position'},!
'airTemperature': {'$first': '$airTemperature'}}!
}]!
!
cursor = db.data.aggregate(pipeline, cursor={})!](https://image.slidesharecdn.com/midwest-140715160818-phpapp02/85/A-Century-Of-Weather-Data-Midwest-io-36-320.jpg)
![{!
name : "New York",!
! geometry : {!
type: "MultiPolygon",!
coordinates: [!
[!
[-71.94, 41.28],!
[-71.92, 41.29],!
/* 2000 more points... */!
[-71.94, 41.28]!
]!
]!
}!
}!
db.states.createIndex({!
geometry: '2dsphere'!
});!
GeoFencing](https://image.slidesharecdn.com/midwest-140715160818-phpapp02/85/A-Century-Of-Weather-Data-Midwest-io-39-320.jpg)
![GeoFencing
db.states.find_one({!
'geometry': {!
'$geoIntersects': {!
'$geometry': {!
'type': 'Point',!
'coordinates': [lng, lat]}}}})!](https://image.slidesharecdn.com/midwest-140715160818-phpapp02/85/A-Century-Of-Weather-Data-Midwest-io-40-320.jpg)







![Analytics: Maximum Temperature
db.data.aggregate
([
{
"$match"
:
{
"airTemperature.quality"
:
{
"$in"
:
[
"1",
"5"
]
}
}
},
{
"$group"
:
{
"_id"
:
null,
"maxTemp"
:
{
"$max"
:
"$airTemperature.value"
}
}
}
])
61.8 °C = 143 °F
2 h 30 min
Single Server
2 min
Cluster](https://image.slidesharecdn.com/midwest-140715160818-phpapp02/85/A-Century-Of-Weather-Data-Midwest-io-56-320.jpg)



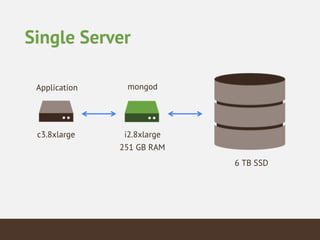
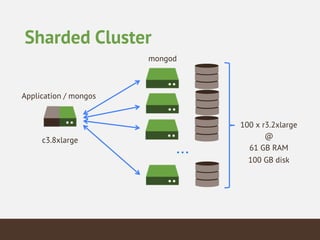
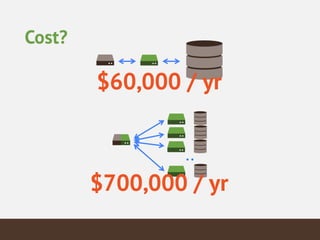
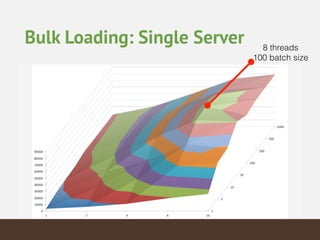
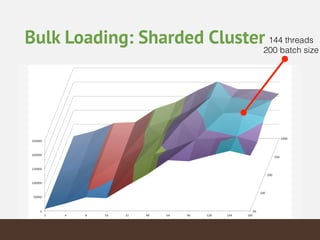
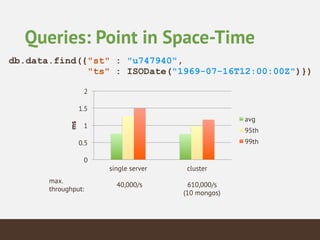
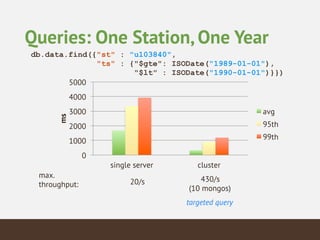
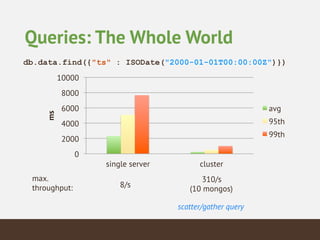
This document summarizes the key considerations and performance tests for storing and querying a large weather dataset containing over 2.5 billion data points. It describes the schema design using MongoDB to embed data and index on location. Bulk loading of data was 10 hours on a single server but only 3 hours on a sharded cluster. Queries for a single data point were fastest on the cluster at under 1ms while worldwide queries were faster at 310/second. Analytics like maximum temperature took 2.5 hours on a single server but only 2 minutes on the cluster. The cluster provided much higher throughput and better performance for complex queries while being more expensive.