Downloaded 40 times



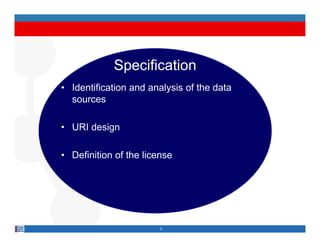


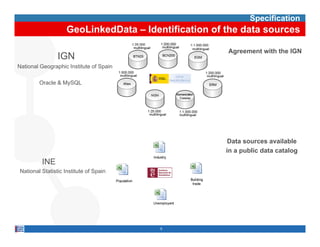
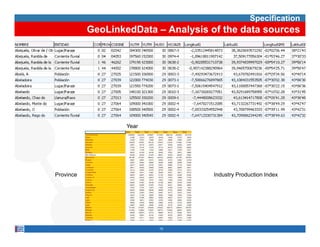




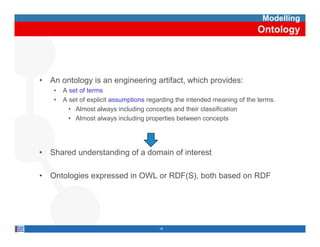
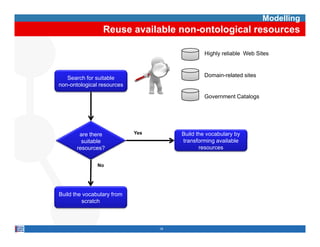
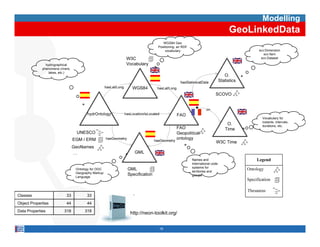
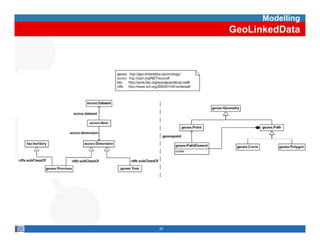
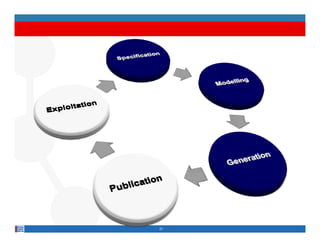


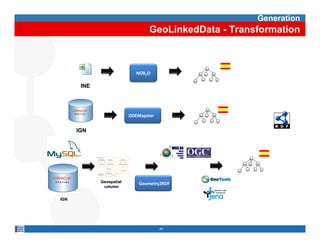
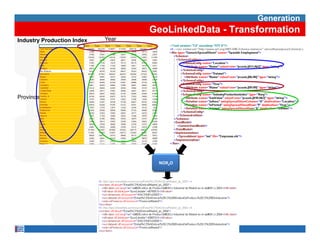
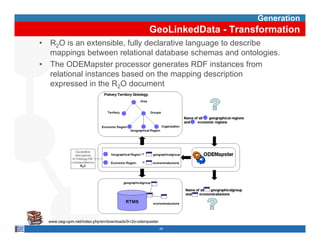
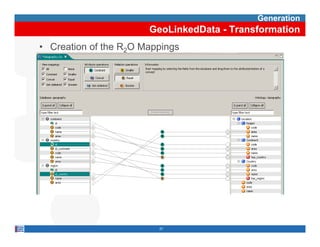
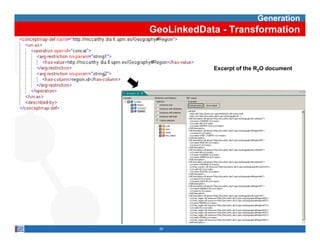
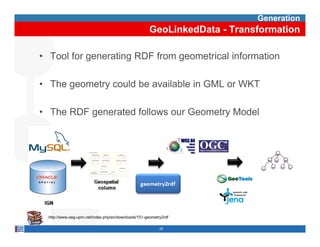
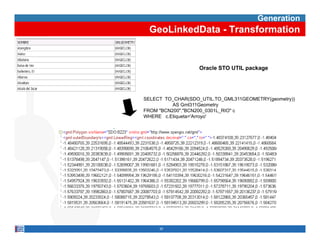



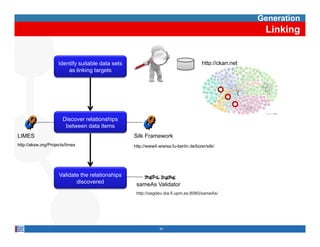
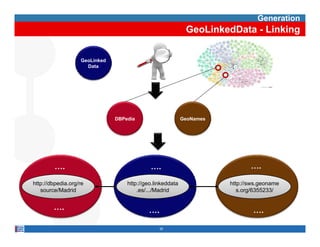
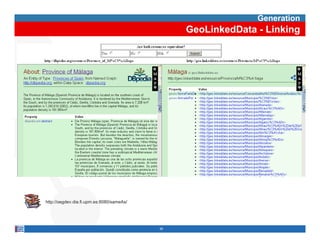
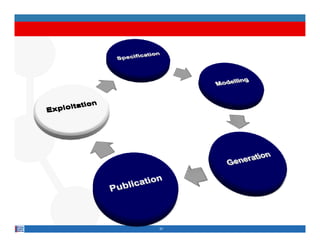




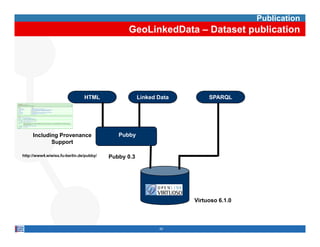
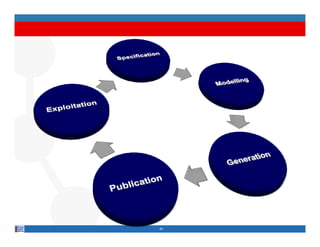
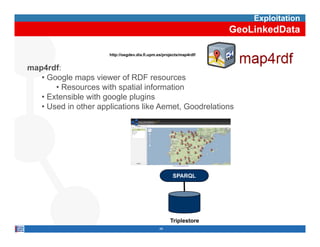

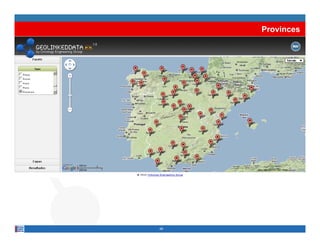
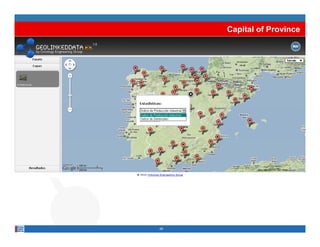
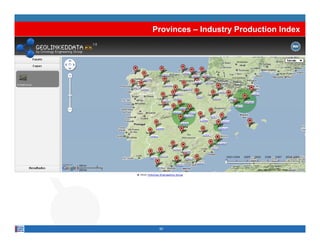
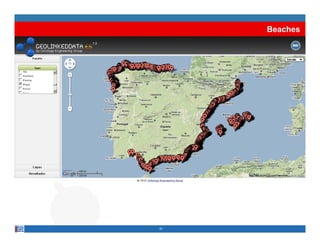



This document provides methodological guidelines for publishing linked data. It outlines the main steps in the process, including identifying and analyzing data sources, designing URIs, defining licenses, modeling ontologies, transforming and cleansing data, linking datasets, and publishing and discovering the linked data. The guidelines are based on experiences applying these methods to real government datasets.


































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)












