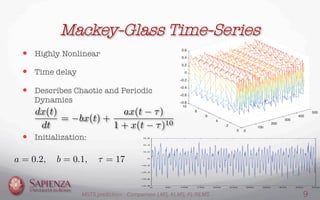
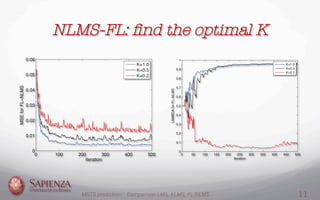
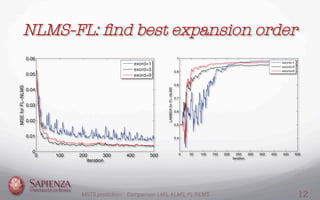
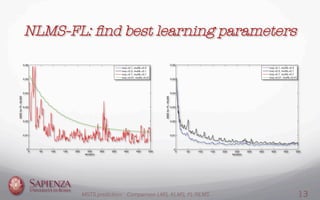
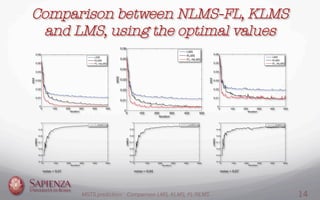
This document compares the LMS, KLMS, and NLMS-FL algorithms for time series prediction on the Mackey-Glass time series. It finds that the NLMS-FL algorithm achieves the best performance with the fastest convergence and lowest mean squared error. Experiments are conducted to determine the optimal parameters for NLMS-FL and compare the performance of the three algorithms under different noise levels and learning rates. The NLMS-FL algorithm outperforms LMS and KLMS in most conditions, demonstrating its effectiveness for time series prediction.




![The Functional Link Nonlinear Filter
— An artificial neural network with a single layer
— Creation of Enhanced Input Pattern z[n]
— Adaptive filtering through NLMS algorithm
— Weight Vector:
— Error on the prediction:
— Weight Update Rule:
— Output of the Functional Link Filter:
MGTS prediction: Comparison LMS, KLMS, FL-NLMS 5](https://image.slidesharecdn.com/neuralnetworkspresentation-140516083915-phpapp02/85/Mackey-Glass-Time-Series-Prediction-5-320.jpg)
![Creation of Enhanced Input Pattern
x[1,n]
x[2,n]
x[3,n]
x[Lin,n]
cos( πx[1,n])
sin(2πx[1,n])
cos(5πx[1,n])
sin(6πx[1,n])
cos(3πx[1,n])
sin(4πx[1,n])
1
2*exord =
= 6
cos( πx[Lin,n])
sin(2πx[Lin,n])
cos(5πx[Lin,n])
sin(6πx[Lin,n])
cos(3πx[Lin,n])
sin(4πx[Lin,n])
2*exord * Lin =
= 6*10 = ∆
bias = 1x[n]
z[n]
∆ + bias = 61 = Len
MGTS prediction: Comparison LMS, KLMS, FL-NLMS 6](https://image.slidesharecdn.com/neuralnetworkspresentation-140516083915-phpapp02/85/Mackey-Glass-Time-Series-Prediction-6-320.jpg)

![A Robust Architecture
— How is the adaptive parameter λ[n] computed?
— It’s computed in function of an adaptive parameter a[n]:
— How is the adaptive parameter a[n] computed?
— It’s computed in function of another adaptive parameter r[n]:
— r[n] is the estimated power of yFL[n]:
MGTS prediction: Comparison LMS, KLMS, FL-NLMS 8](https://image.slidesharecdn.com/neuralnetworkspresentation-140516083915-phpapp02/85/Mackey-Glass-Time-Series-Prediction-8-320.jpg)




![Thanks for
Your Attention!"
References:
[1] D.Comminiello, A.Uncini, R. Parisi and
M.Scarpiniti, A Functional Link Based
Nonlinear Echo Canceller Exploiting
Sparsity.
[2] D.Comminiello, A.Uncini, M.Scarpiniti,
L.A.Azpicueta-Ruiz and J.Arenas-Garcia,
Functional Link Based Architectures For
Nonlinear Acoustic Echo Cancellation.
[3] Y.H.Pao, Adaptive Pattern Recognition
and Neural Networks.
[4] A.Uncini, Neural Networks:
Computational and Biological Inspired
Intelligent Circuits.
[5] Weifeng Liu, Jose C. Principe, and Simon
Haykin, Kernel Adaptive Filtering:
A Comprehensive Introduction.
[6] Dave Touretzky and Kornel Laskowski,
15-486/782: Artificial Neural Network, FALL
2006, Neural Networks for Time Series
Prediction.
MGTS prediction: Comparison LMS, KLMS, FL-NLMS 18](https://image.slidesharecdn.com/neuralnetworkspresentation-140516083915-phpapp02/85/Mackey-Glass-Time-Series-Prediction-18-320.jpg)