Downloaded 11 times


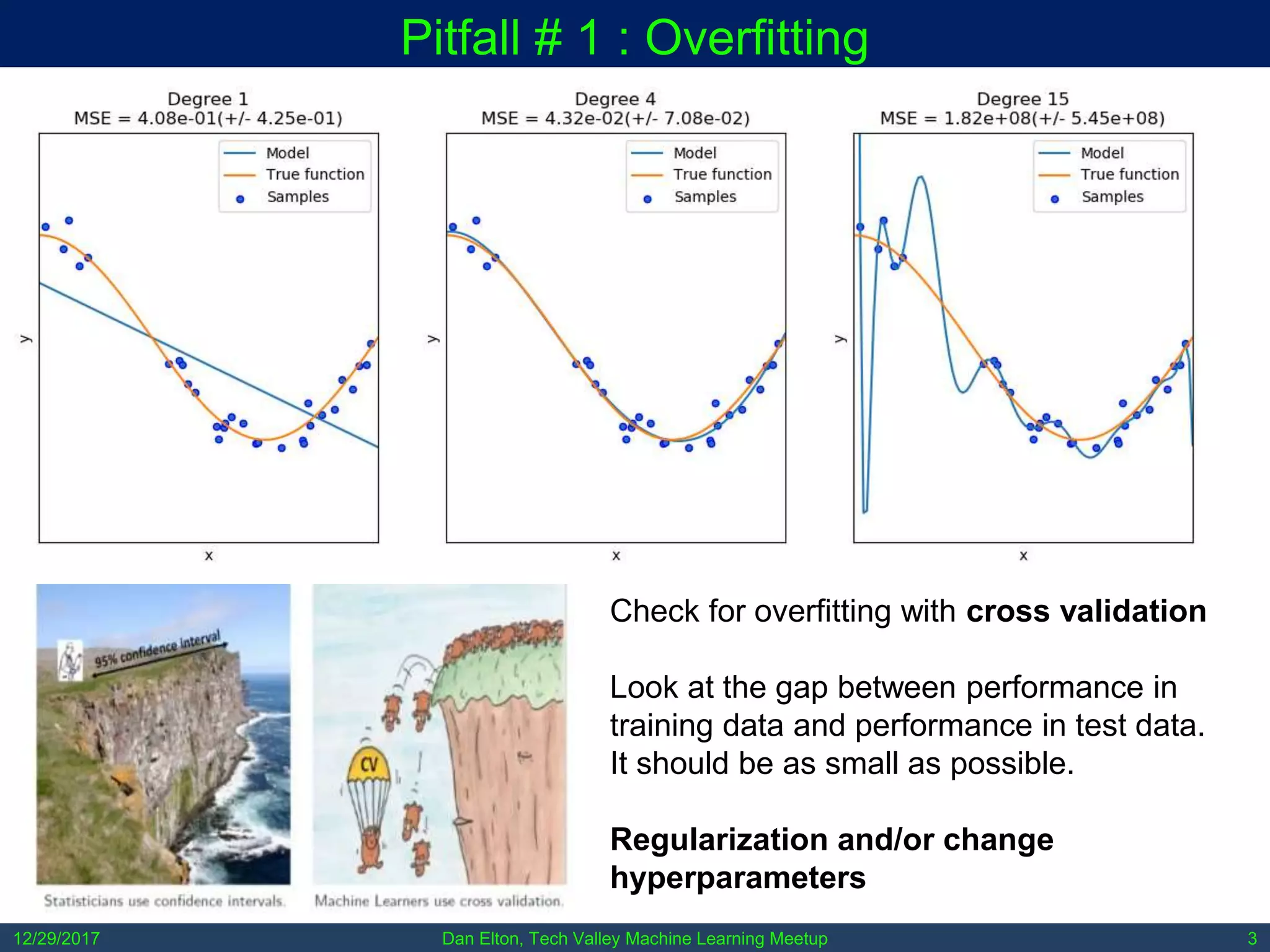
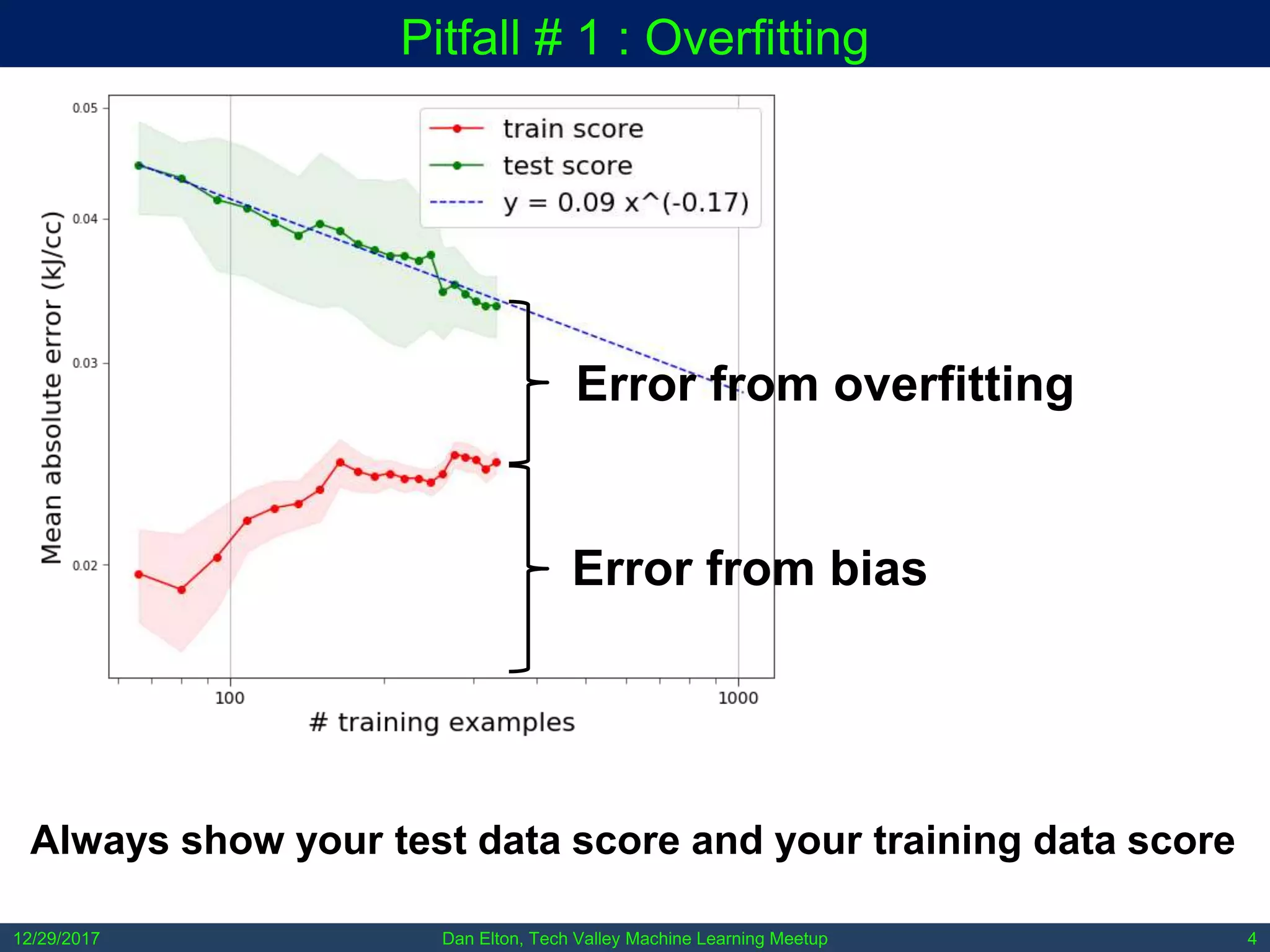






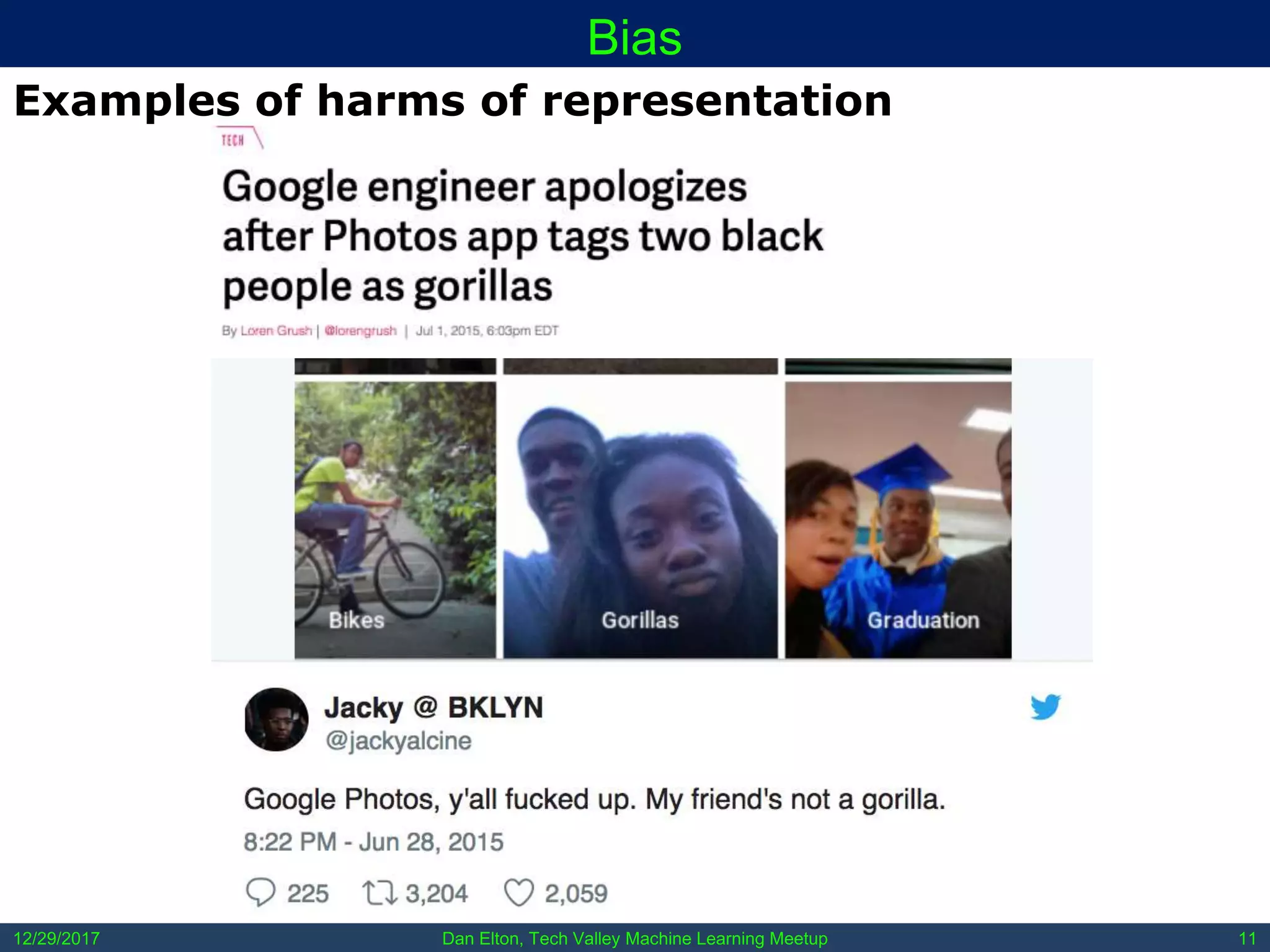


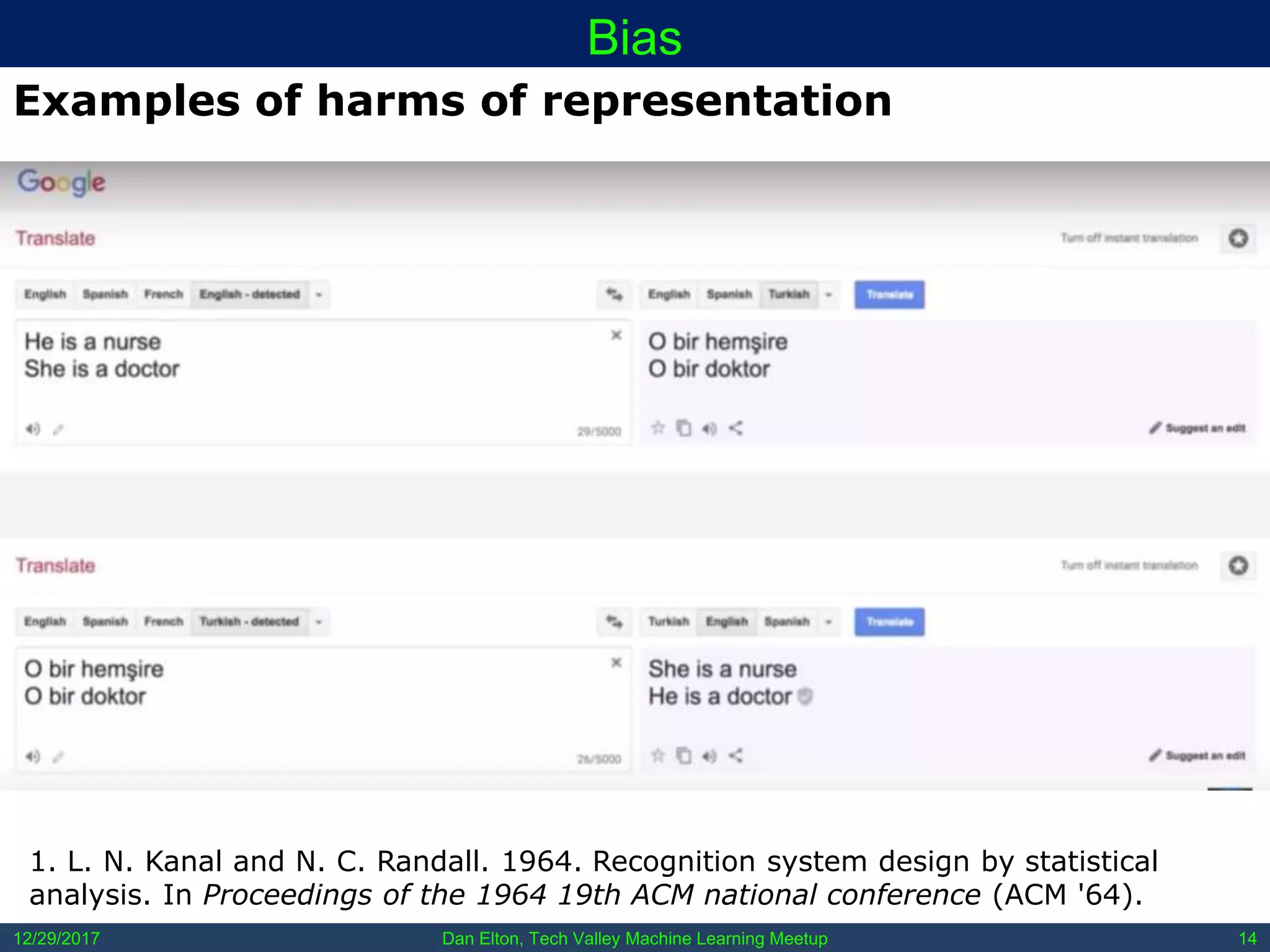


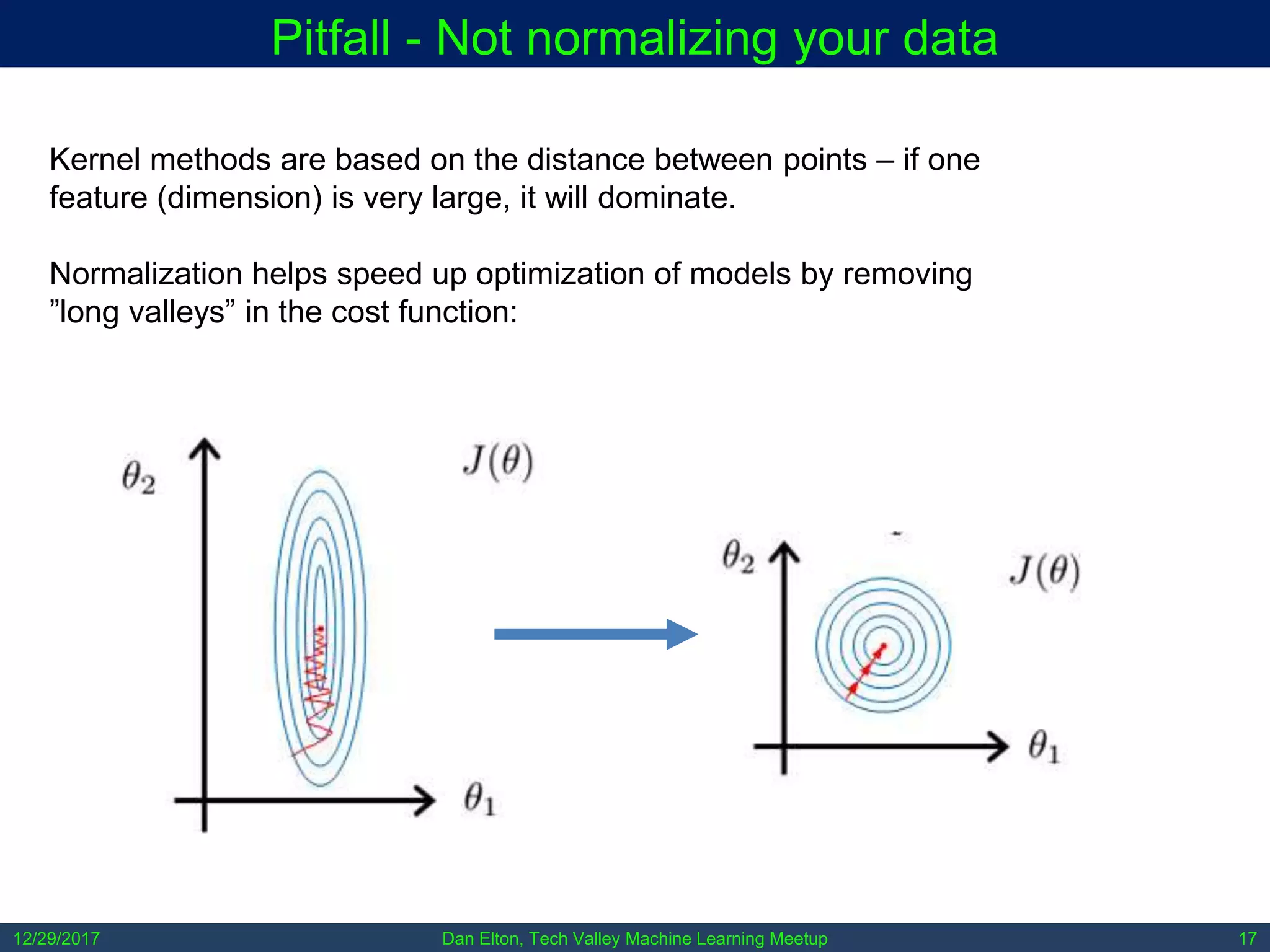
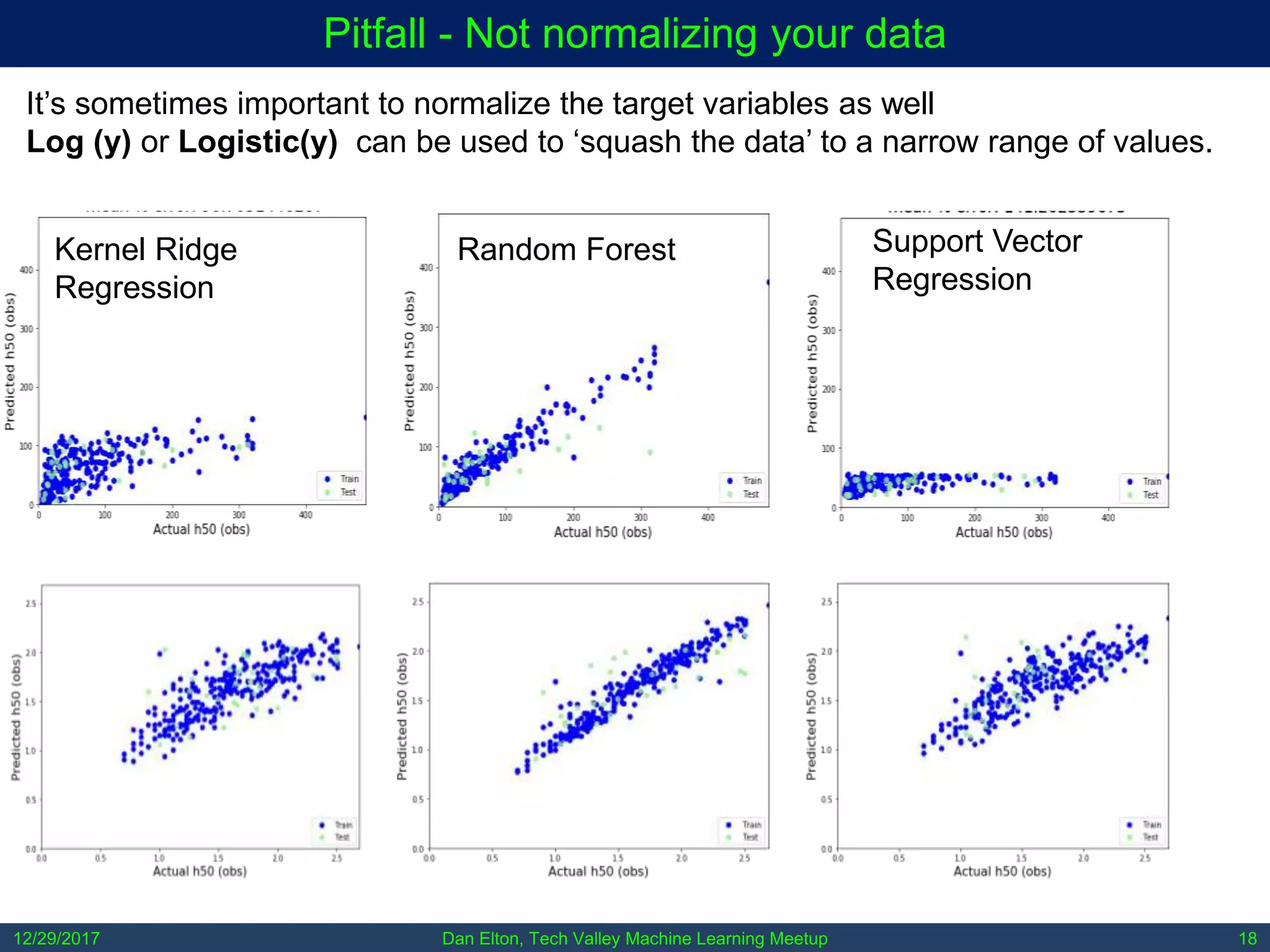
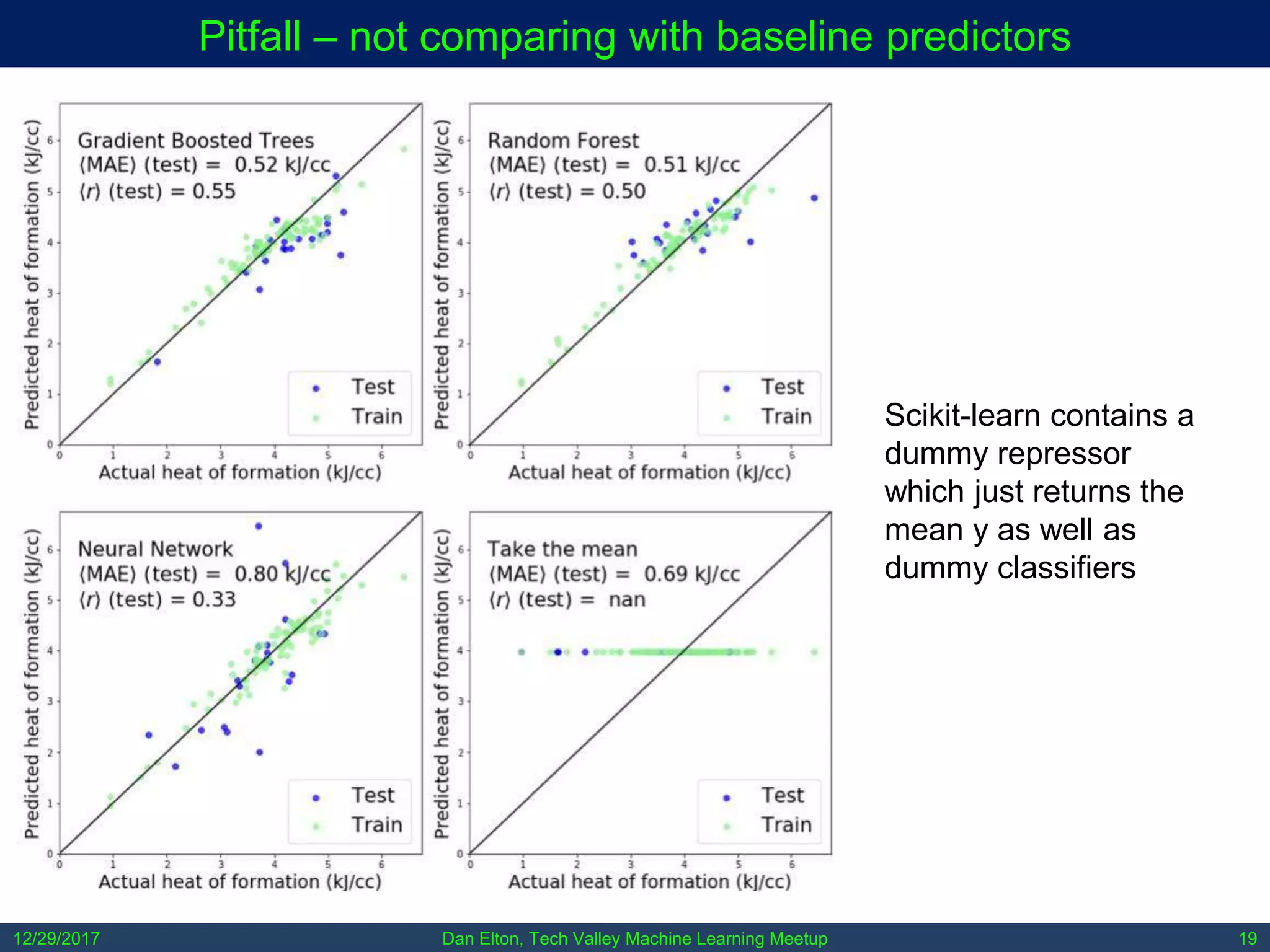

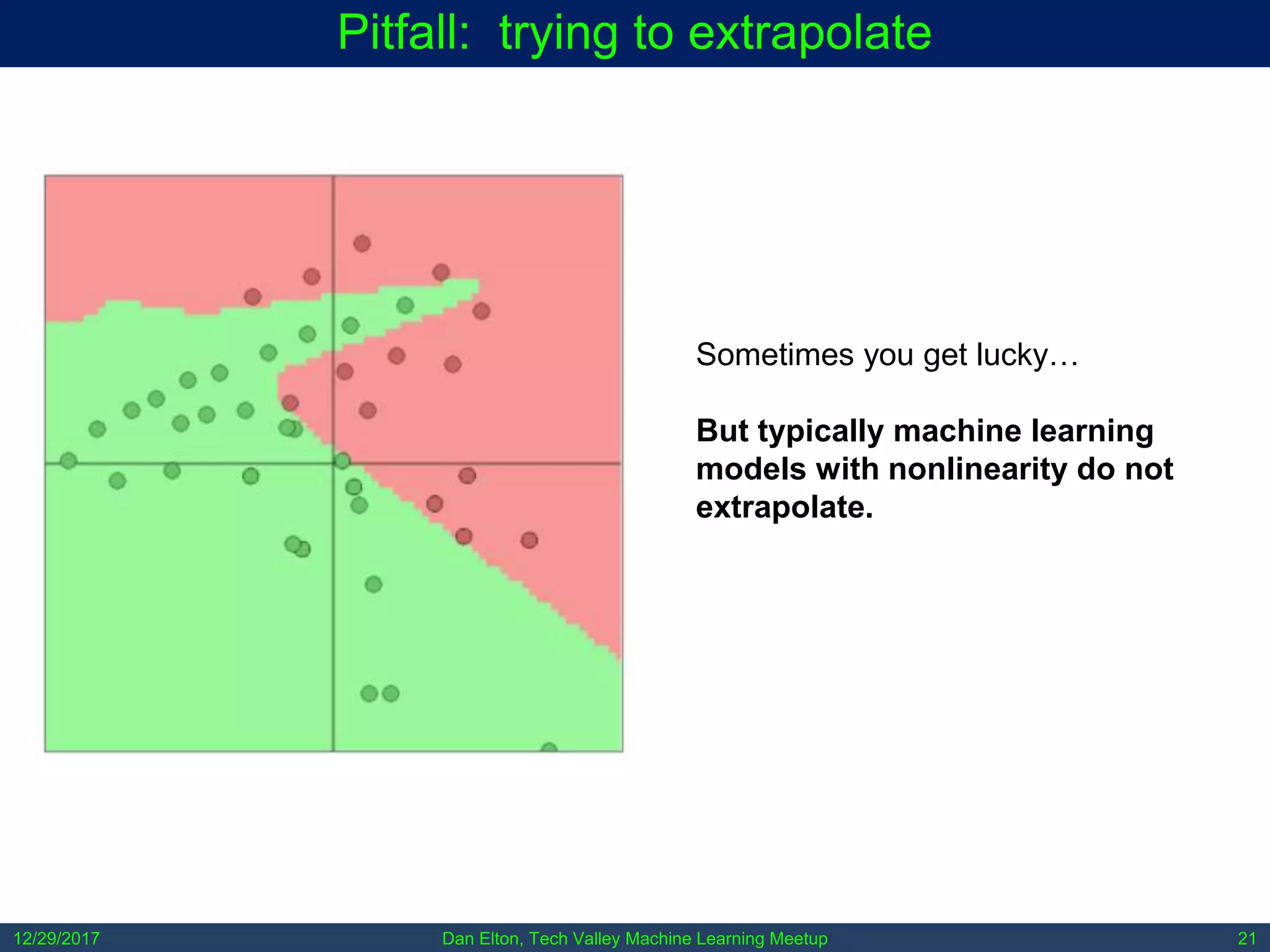





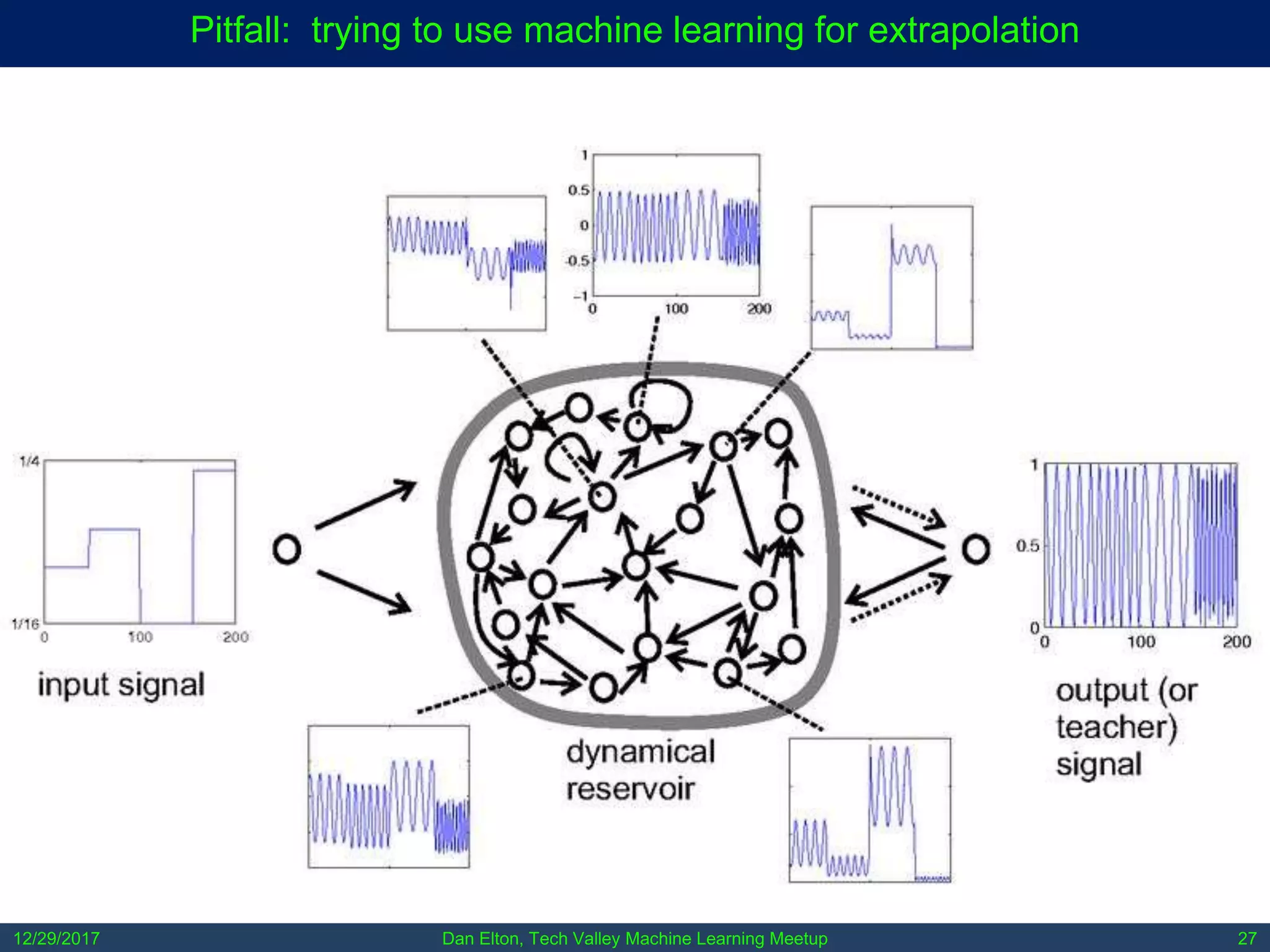
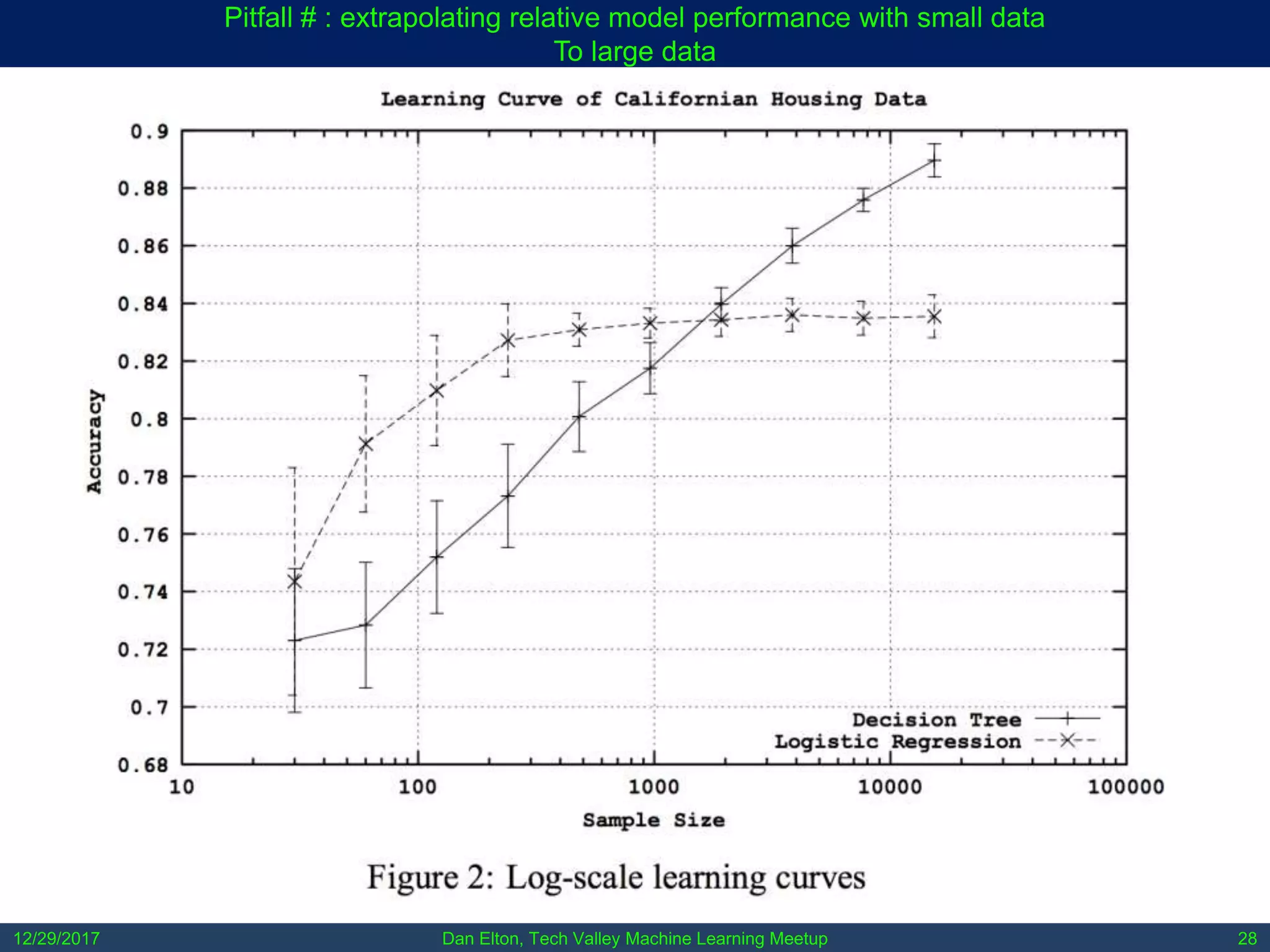

The document outlines common pitfalls in machine learning, including overfitting, biases in training data, and the importance of data cleaning and normalization. It discusses various types of bias, such as statistical and social bias, and highlights examples of harms caused by these biases. Additionally, it emphasizes the significance of transparency in models and the need for rigor in data science practices.


































































