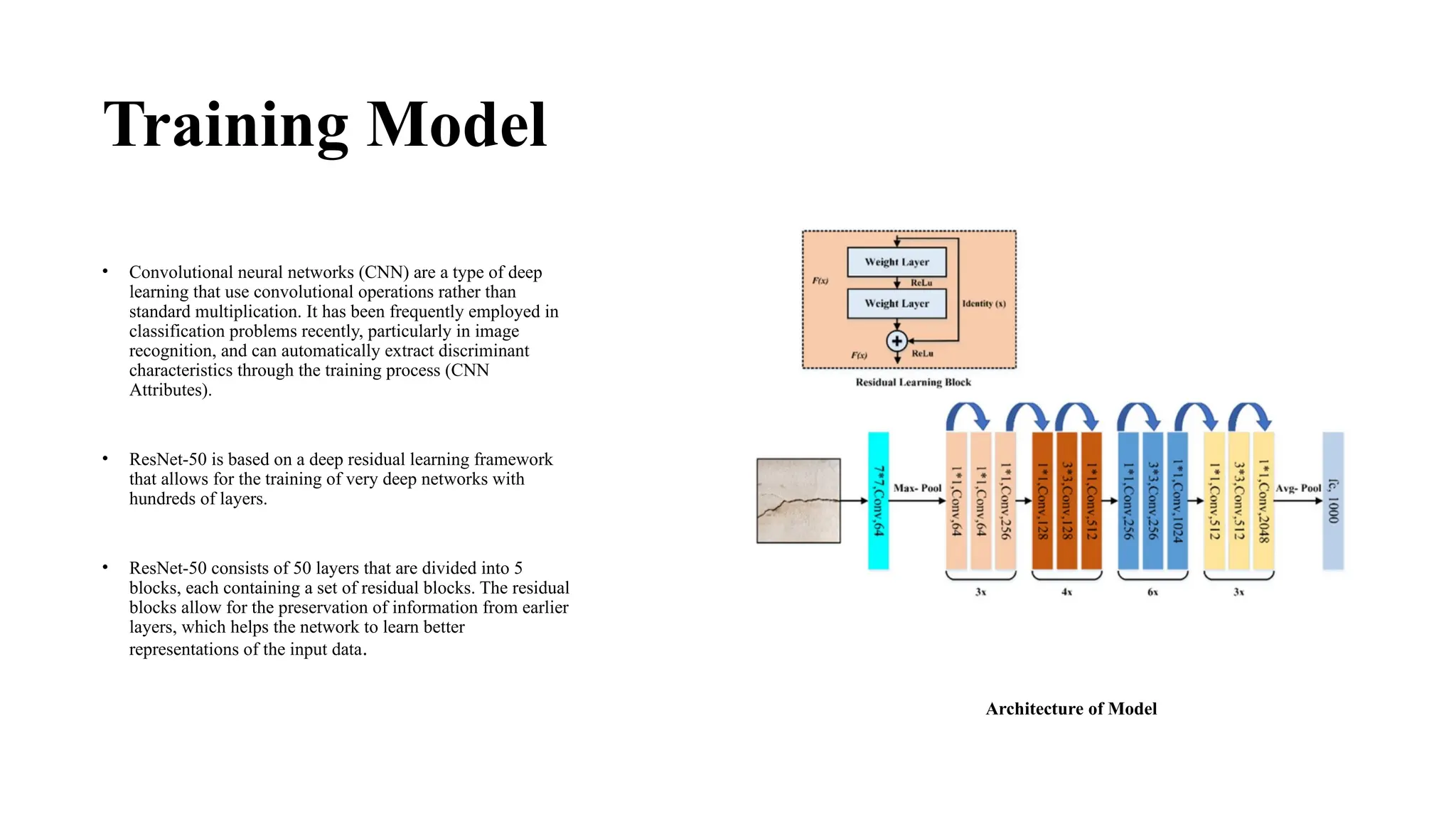
This document discusses a project on applying machine learning for object recognition in preschool education using the CIFAR-10 dataset, aiming to enhance early childhood learning experiences. It identifies gaps in preschool education, such as disparities in accessibility and quality, and outlines the methodology using Convolutional Neural Networks (CNN) with a focus on the ResNet-50 architecture. The goal is to develop a machine learning model that effectively classifies objects, thereby improving educational outcomes for young learners.









![Methodology
Understanding the CNN
CNN (convolution Neural network) is, Neural Network are a subset of machine learning, and they are at the heart of deep learning algorithms.
They are comprised of node layers, containing an input layer, one or more hidden layers, and an output layer. Each node connects to another
and has an associated weight and threshold.
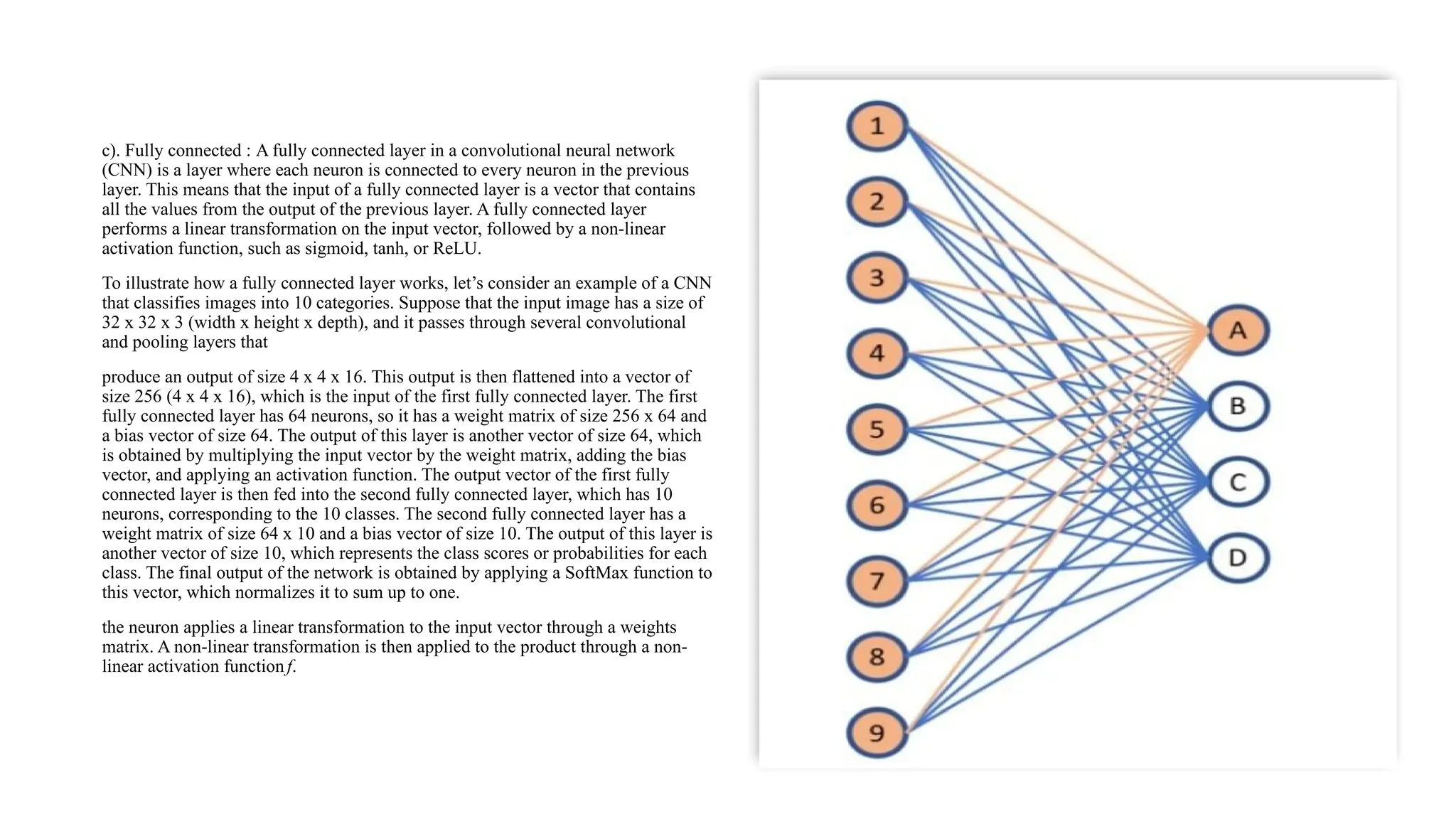
a). Convolution Layer: The convolutional layer is the core building block of a CNN, and it is where most of the computation occurs. It requires
a few components, which are input data, a filter, and a feature map. Let’s assume that the given input will be colour image, which is made up of
a matrix of pixels in 3D. This means the input will have 3 dimensions— height, width, and depth—which correspond to RGB in an image. We
also have a feature detector, also known as a kernel or a filter, which will move across the receptive fields of the image [2], checking if the
feature is present. This process is known as a convolution.
• The final output from the series of dot products from the input and the filter is known as a feature map, activation map, or a convolved
feature. the weights in the feature detector remain fixed as it moves across the image, which is also known as parameter sharing.
• A parameter sharing scheme is used in convolutional layers to control the number of free parameters. It relies on the assumption that if a
patch feature is useful to compute at some spatial position, then it should also be useful to compute at other positions. Denoting a single 2-
dimensional slice of depth as adepth slice, the neurons in each depth slice are constrained to use the same weights and bias.](https://image.slidesharecdn.com/btppresentation-final-240921195451-a59ca6c7/75/machine-learning-based-object-recognition-using-cifar-10-10-2048.jpg)

![Illustration for how a convolutional
layer operates.
ReLu activation function makes the network converge much faster as it does not saturate (when x > 0) and is computationally
efficient. It is defined as, f(x) = max (0, x) but it suffers from a drawback, when x < 0, during forward pass neurons remain inactive
and weights are not updated during backpropagation. As a result, the network does not learn. Hence, we use leaky ReLu [8] which is
defined as](https://image.slidesharecdn.com/btppresentation-final-240921195451-a59ca6c7/75/machine-learning-based-object-recognition-using-cifar-10-12-2048.jpg)
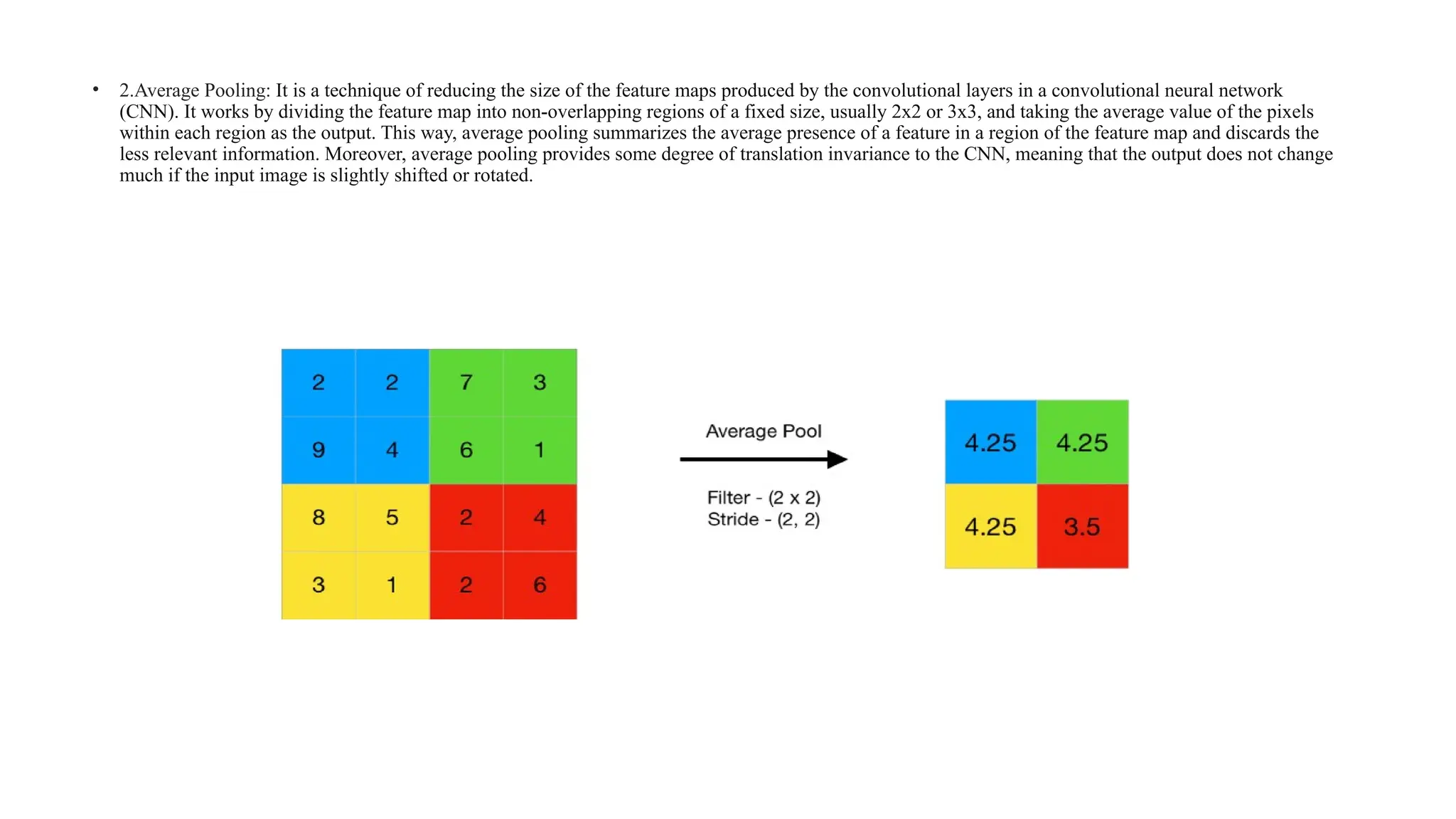
![b). Pooling Layer: Pooling layer is used to reduce the size of the image along with keeping the important parameters in role. Thus, it helps to
reduce the computation in the model.
1.Max Pooling we narrow down the scope and of all the features, the most important features are only considered. Thus, the problem is solved.
Pooling is done in two ways Average Pooling or Max Pooling. Max Pooling is generally used [5]. It will only consider the maximum value
within a kernel filter as per the size of strides and enhance the edge detection i.e., vertical and horizontal edge. It will reduce the image size and
make the computational faster.
But max pooling technique is not used in case of large data set as it will reduce the size of image significantly and thus change the image
parameter.](https://image.slidesharecdn.com/btppresentation-final-240921195451-a59ca6c7/75/machine-learning-based-object-recognition-using-cifar-10-13-2048.jpg)



![Fig-1 Accuracy after 10 epochs Fig-2 Loss after 10 epochs
• Fig 2 shows the loss of data during the training and validation process. Loss function denotes the degree of error while making predictions
during training and testing process.
• Fig 1 shows the accuracy of data during the training and validation process. Fig [1,2] shows the model performance in the form of accuracy
and loss with respect to iterations. The output demonstrates the model’s accuracy after 10 iterations.
• After each iteration, the training performance progressively got better and stayed stable.
• In the validation set for the classification of objects (CIFAR-10 dataset), an averaged accuracy of 71% was attained after 10 iterations, or
epochs. With each iteration, the loss likewise decreased, entire model took 41 seconds to predict the labels correctly.](https://image.slidesharecdn.com/btppresentation-final-240921195451-a59ca6c7/75/machine-learning-based-object-recognition-using-cifar-10-20-2048.jpg)

















































