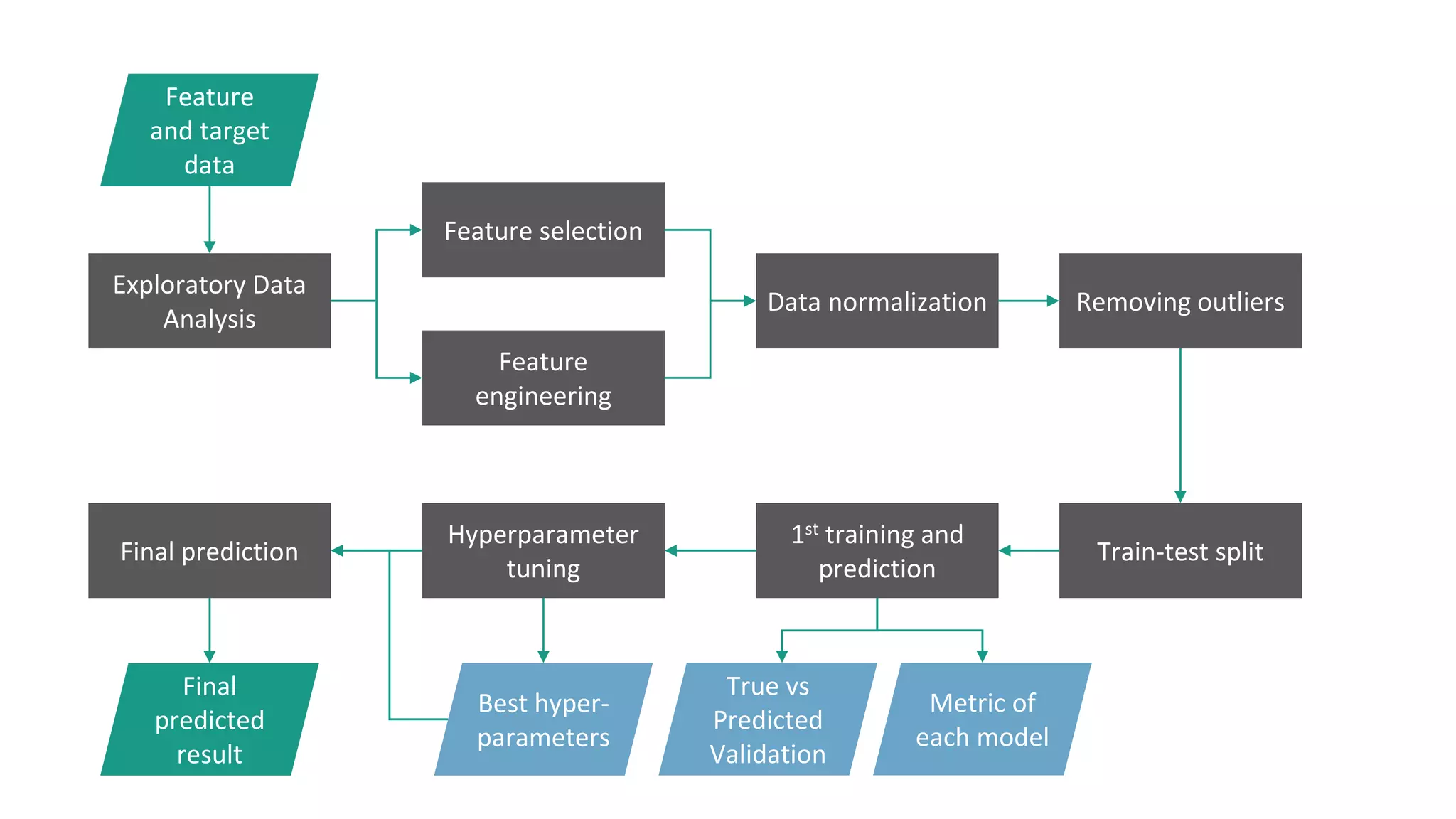
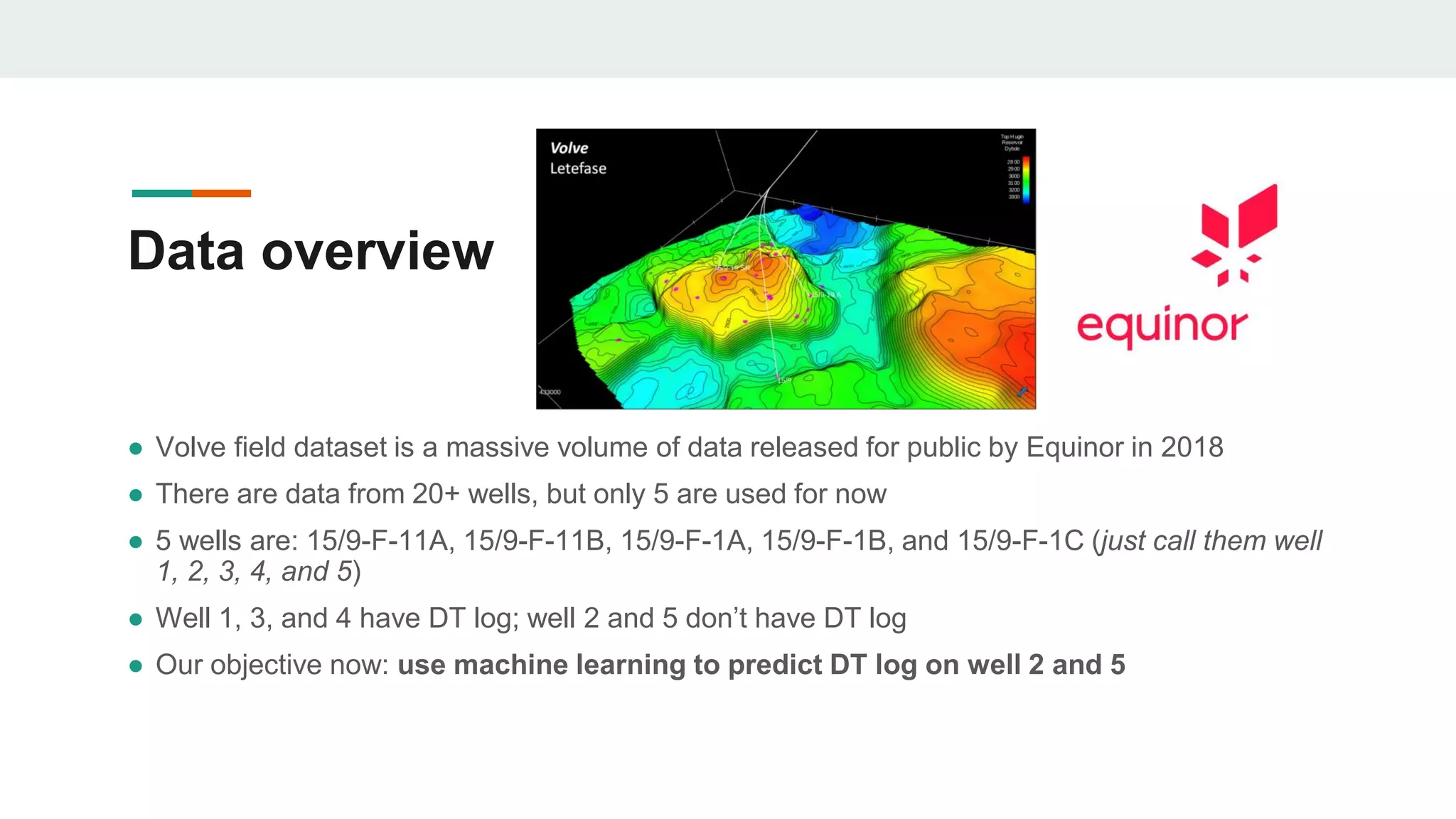
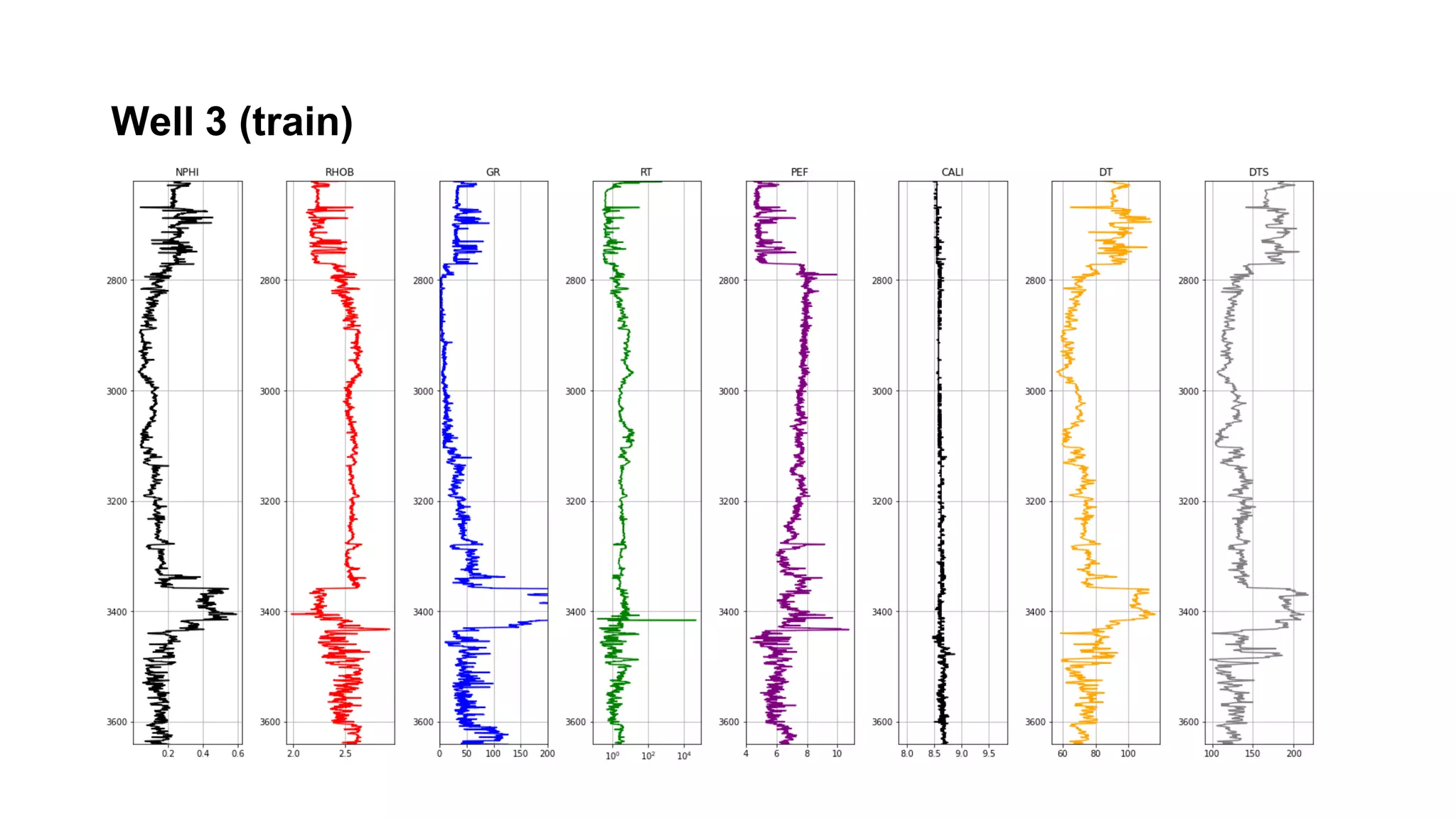
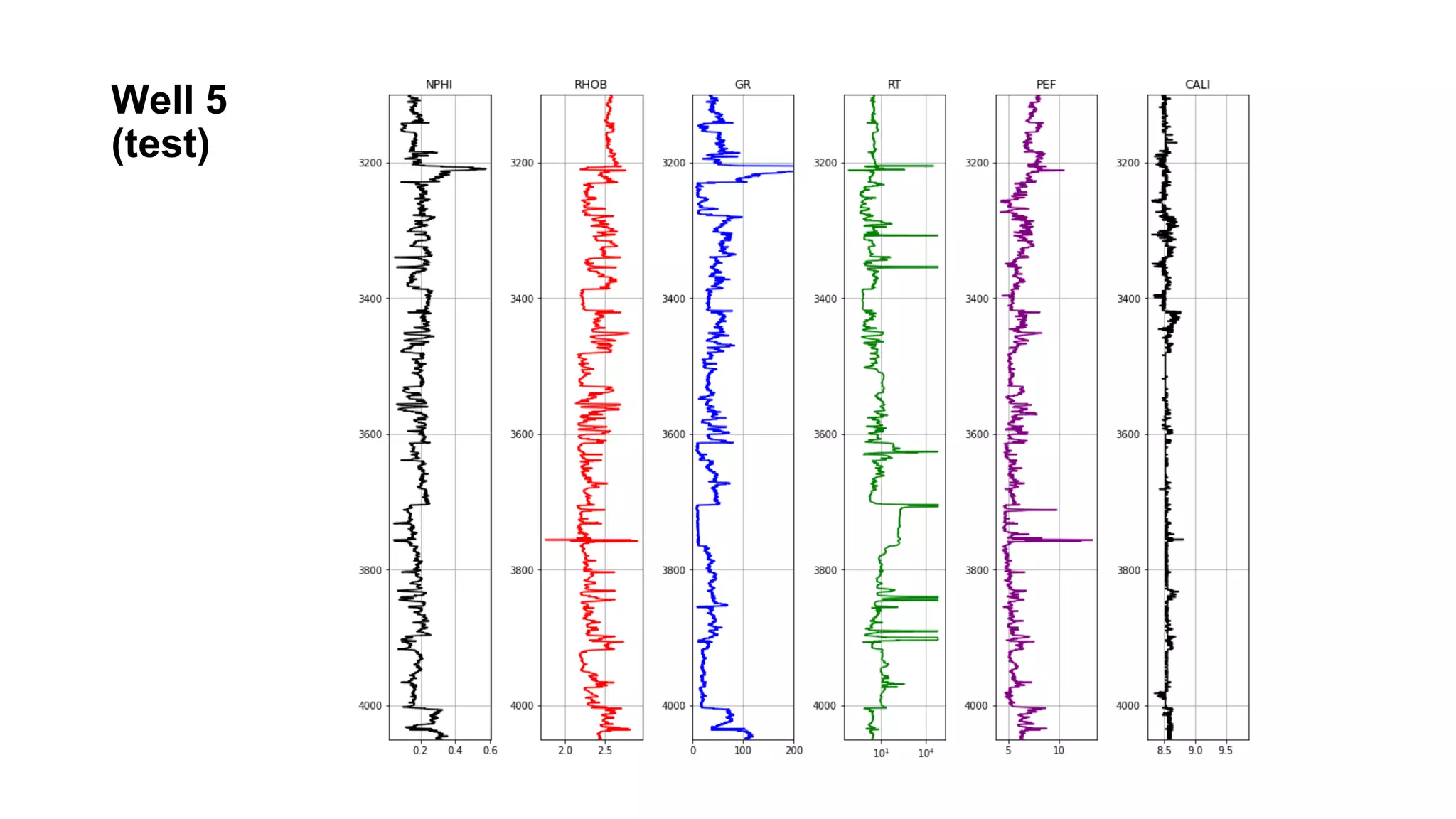
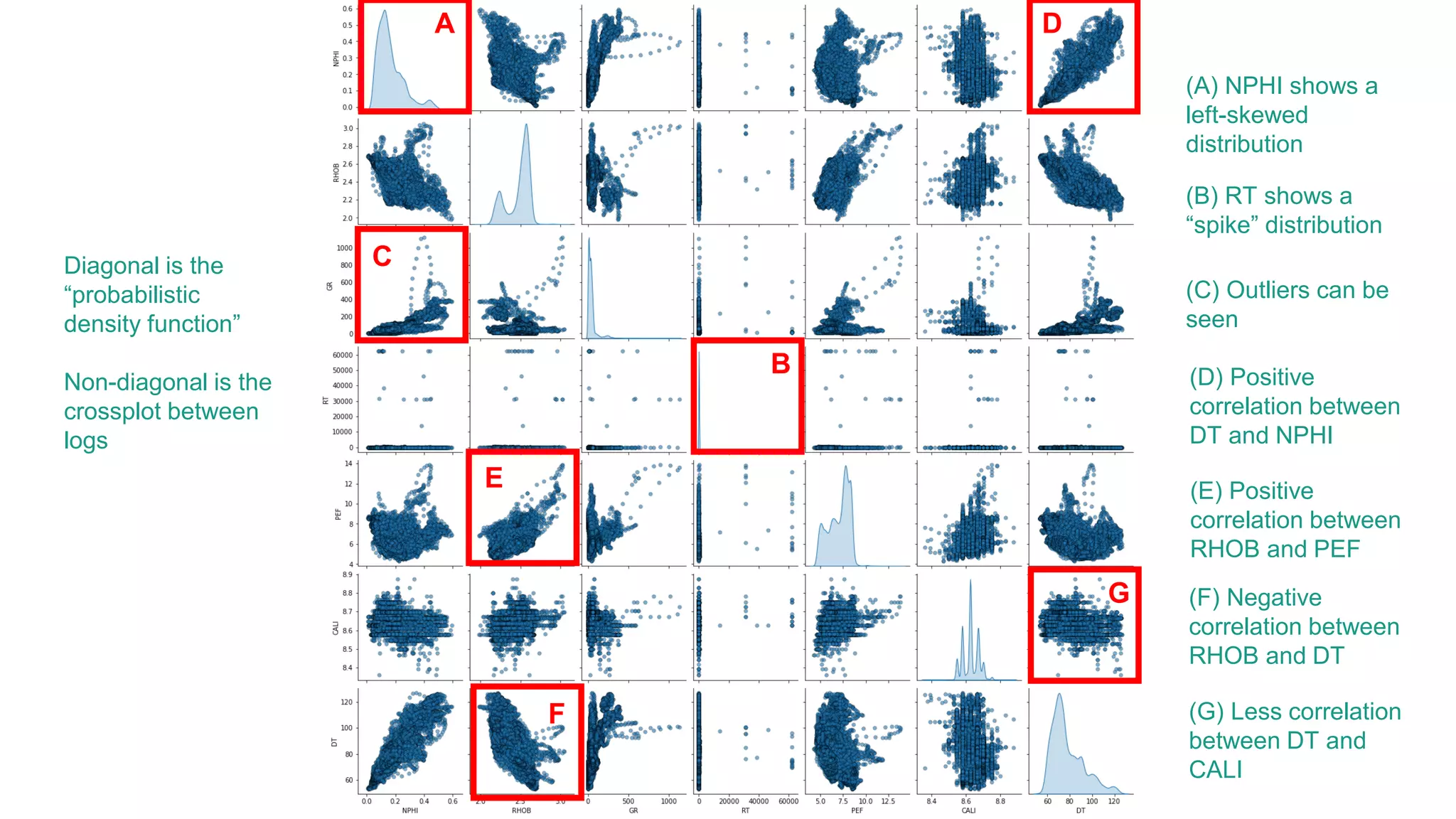
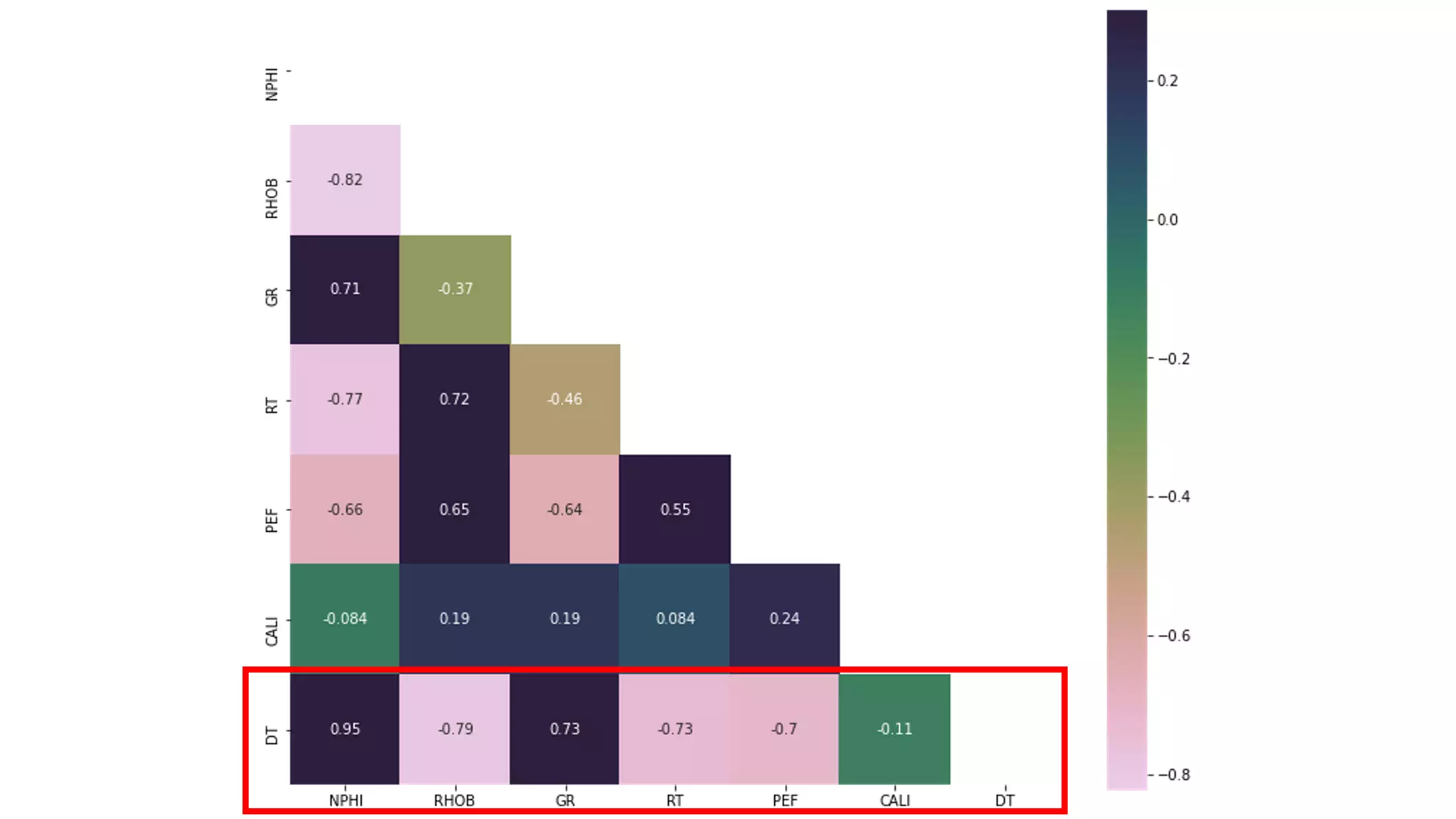
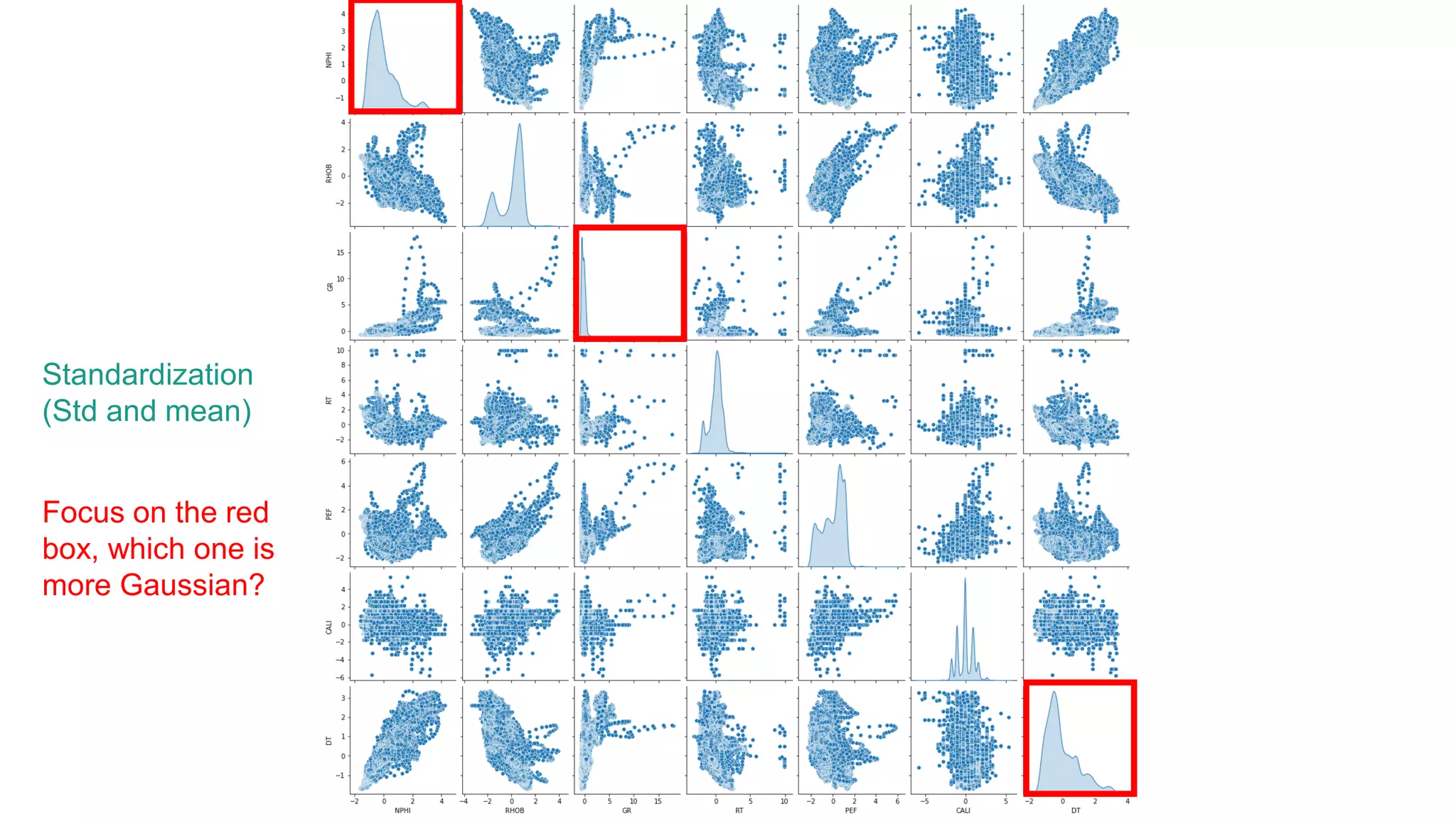
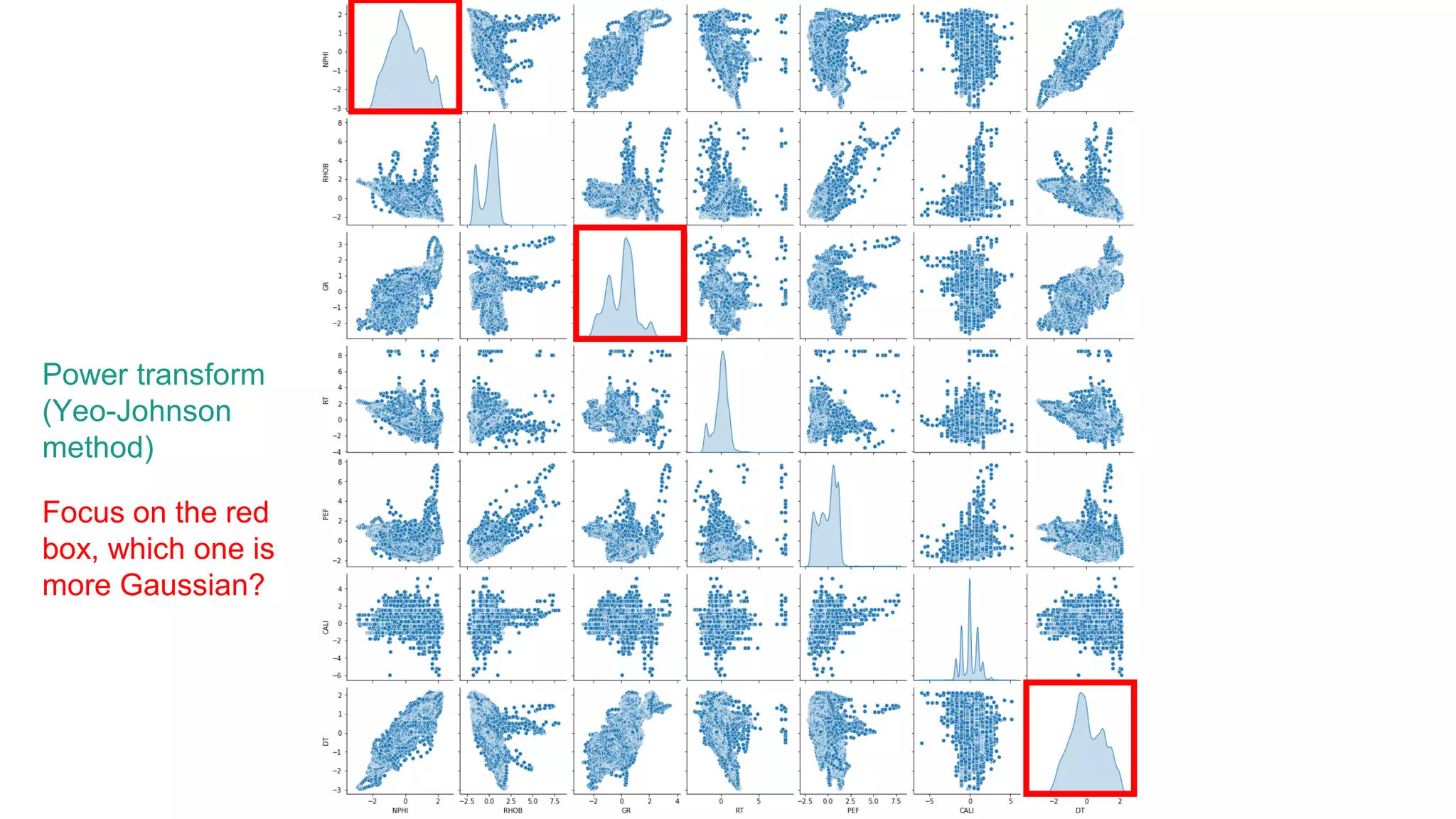
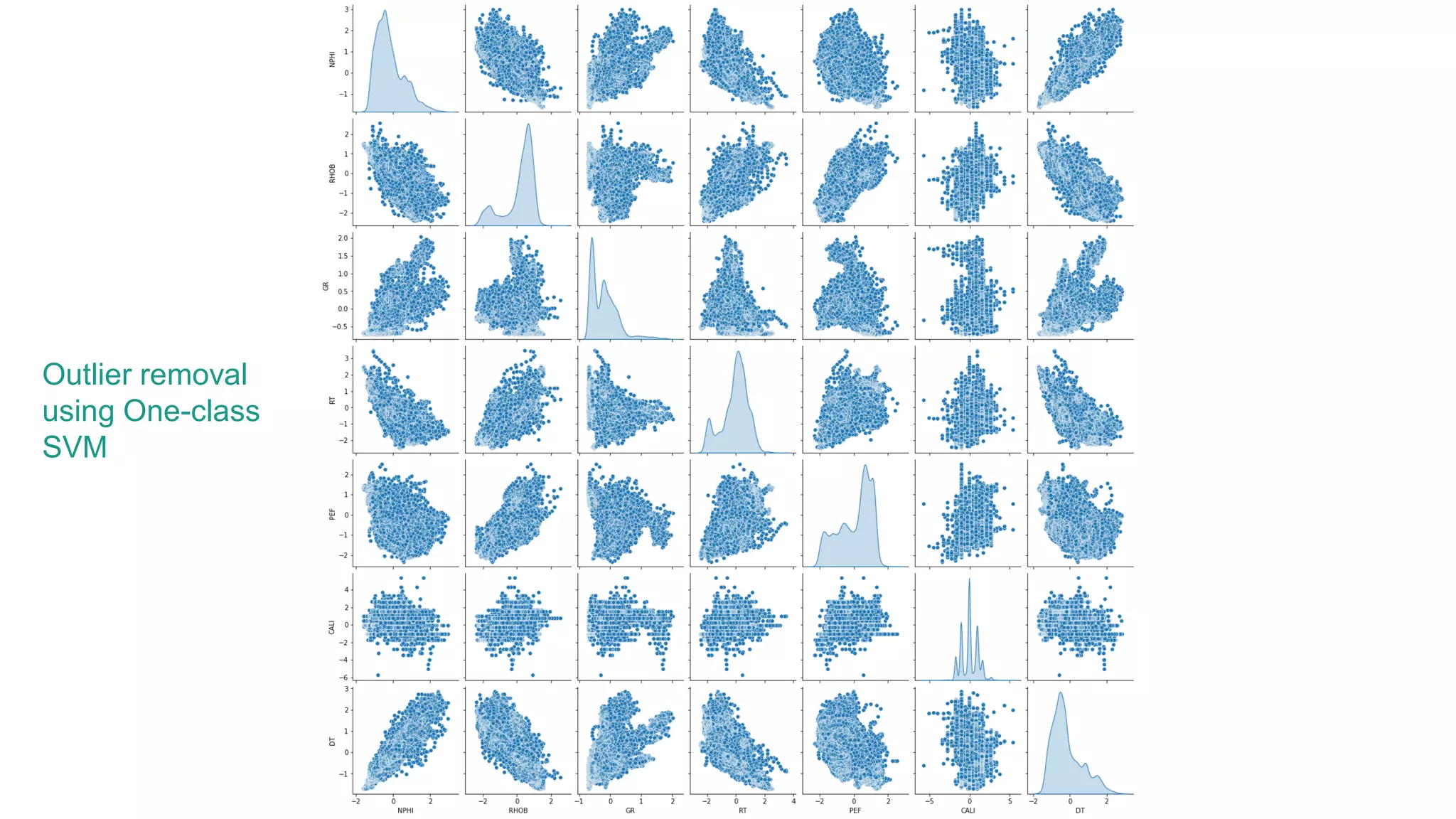
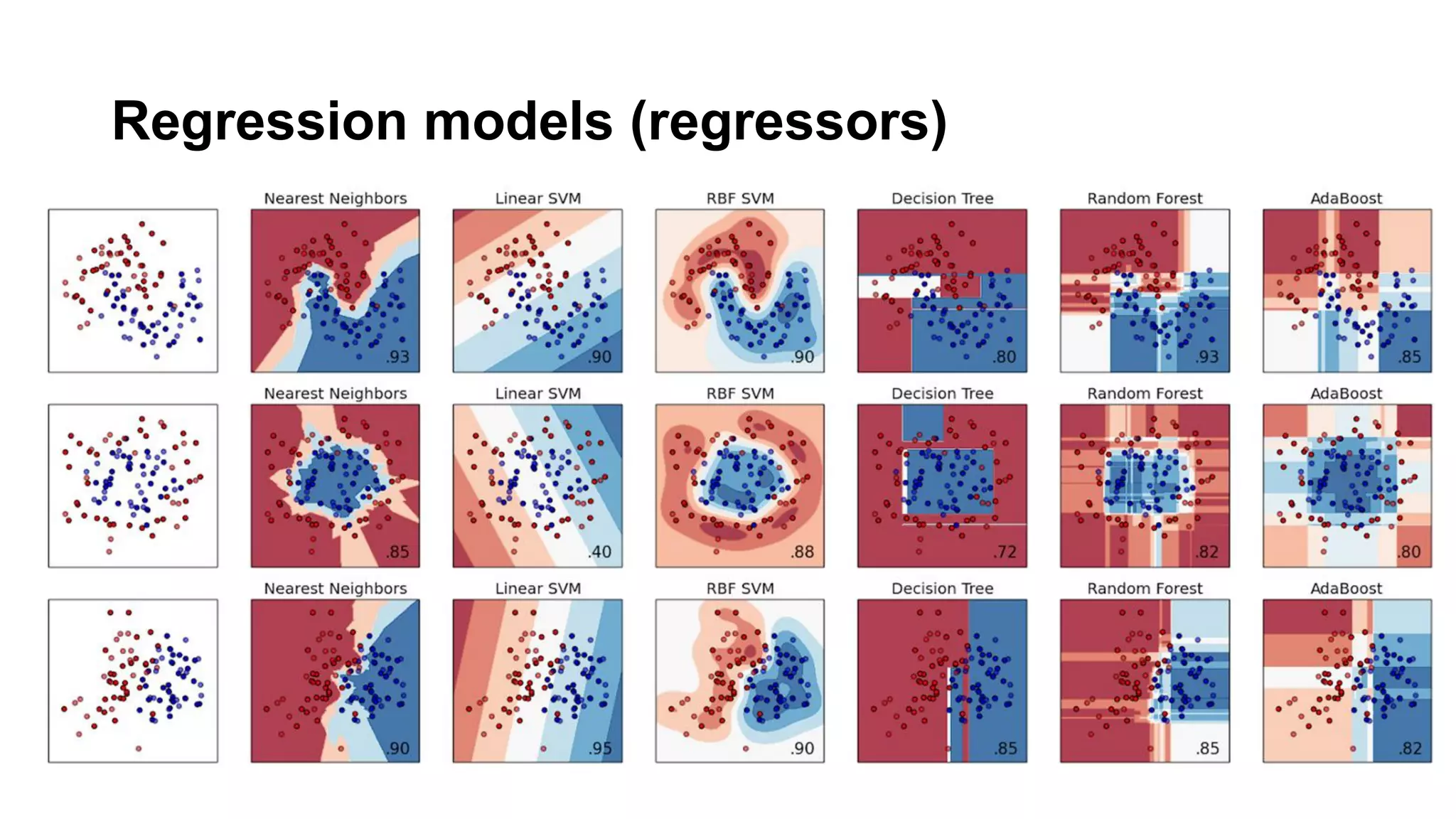
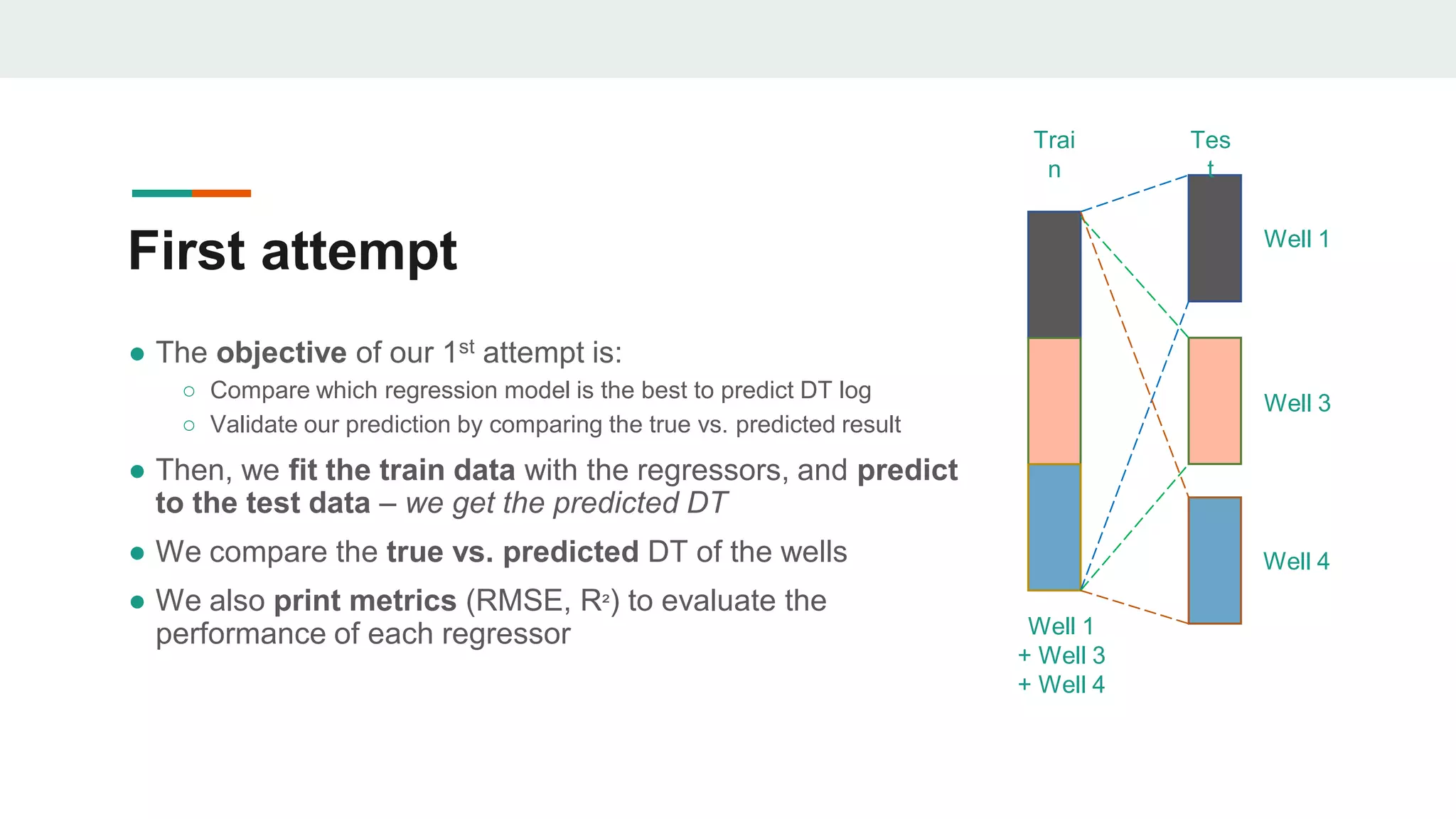
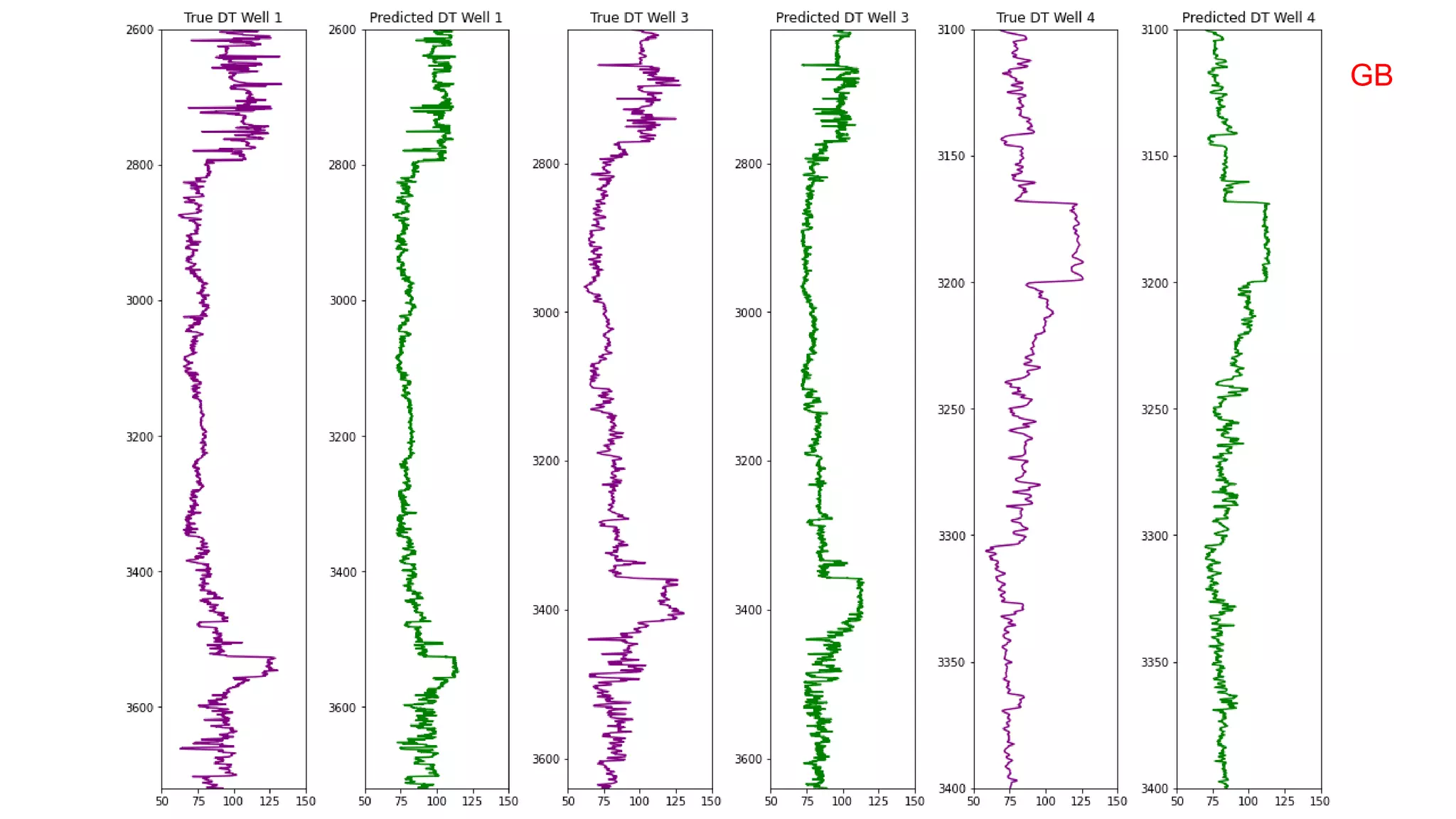
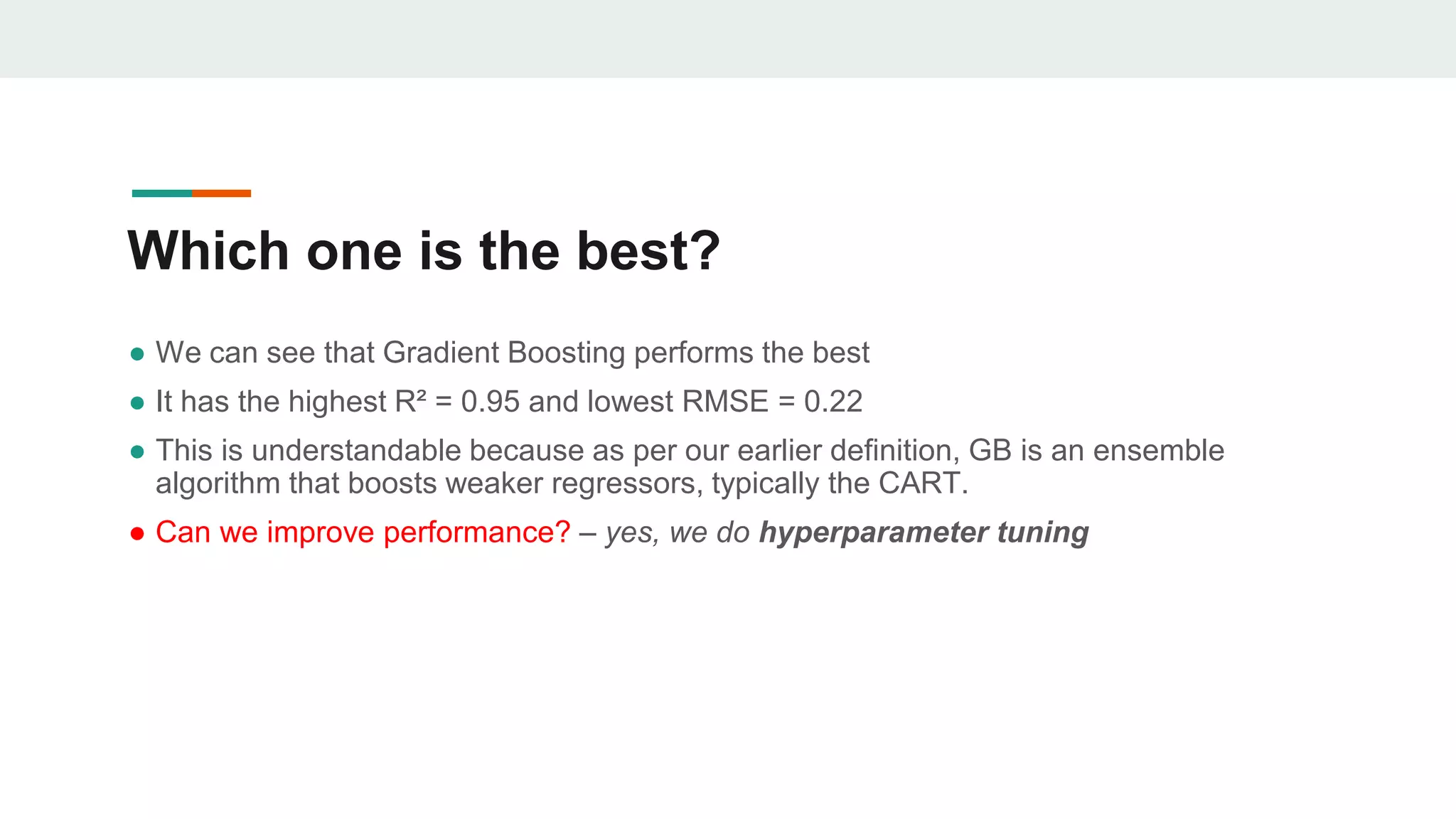
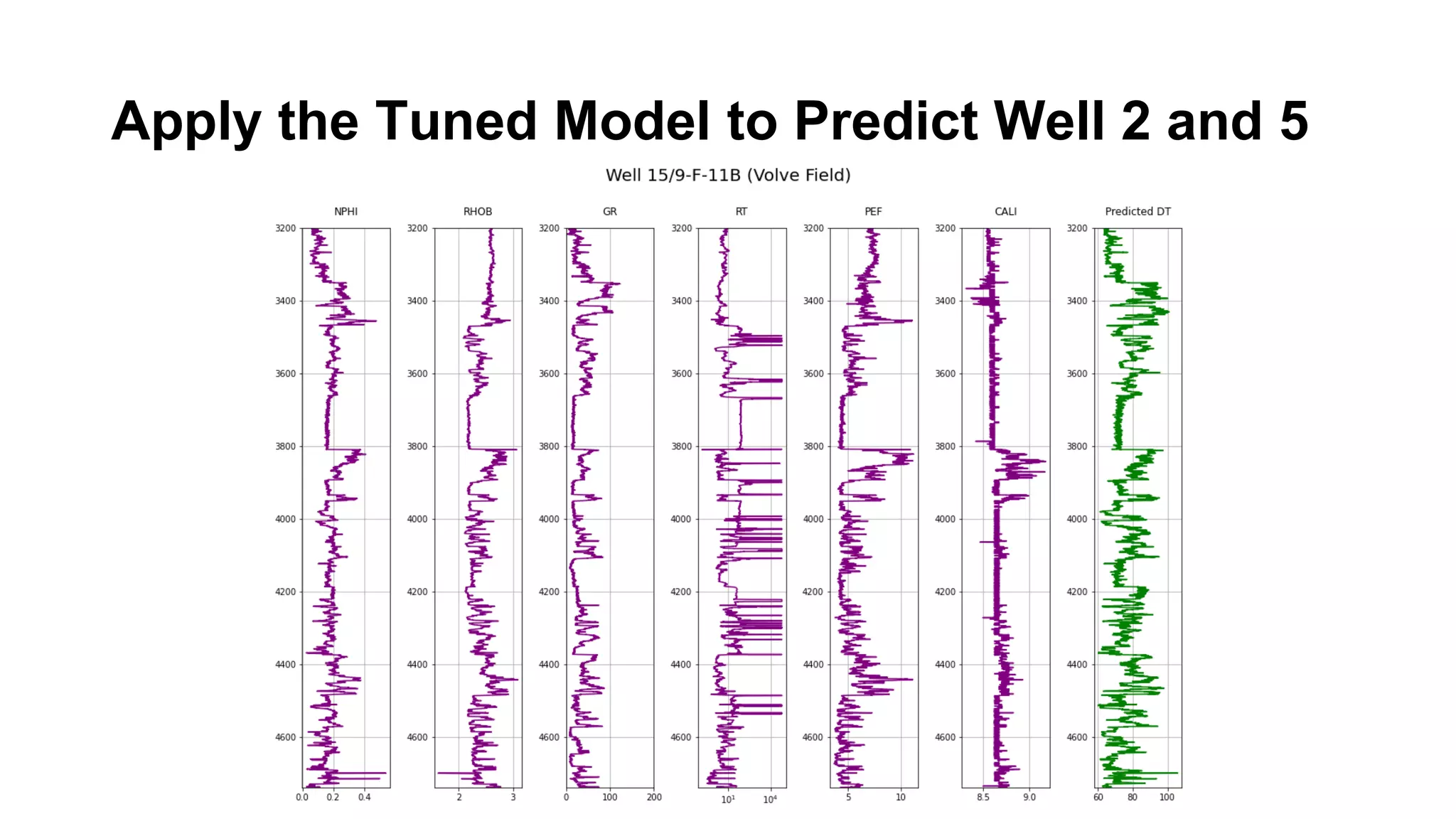
This document discusses the application of machine learning in subsurface analysis, focusing on a case study in the Volve field in the North Sea. It outlines the machine learning workflow and techniques for exploratory data analysis, feature engineering, and prediction using various regression models, concluding that gradient boosting performs the best in this context. The importance of data normalization and outlier removal is highlighted as critical steps for improving prediction accuracy.