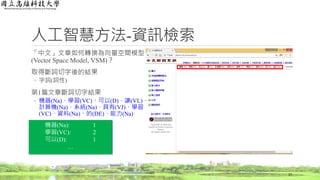
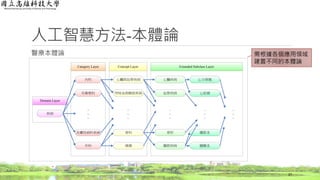
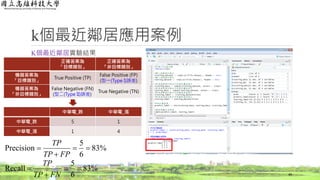
人工智慧方法-資訊檢索
文章如何轉換為向量空間模型(Vector Space Model,VSM)?
7
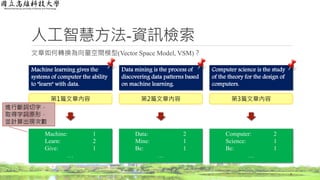
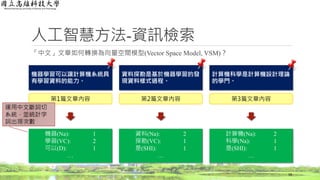
Machine learning gives the
systems of computer the ability
to "learn" with data.
Data mining is the process of
discovering data patterns based
on machine learning.
Computer science is the study
of the theory for the design of
computers.
第1篇文章內容 第2篇文章內容 第3篇文章內容
Machine: 1
Learn: 2
Give: 1
…
Data: 2
Mine: 1
Be: 1
…
Computer: 2
Science: 1
Be: 1
…
進行斷詞切字,
取得字詞原形,
並計算出現次數
8.
人工智慧方法-資訊檢索
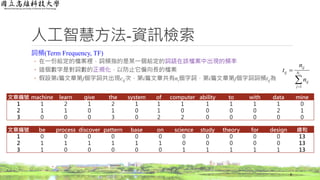
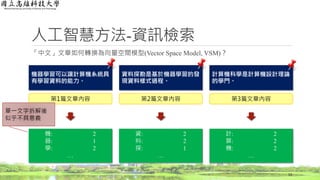
詞頻(Term Frequency, TF)
◦在一份給定的檔案裡,詞頻指的是某一個給定的詞語在該檔案中出現的頻率
◦ 這個數字是對詞數的正規化,以防止它偏向長的檔案
◦ 假設第i篇文章第j個字詞共出現cij次,第i篇文章共有ni個字詞,第i篇文章第j個字詞詞頻tij為
8
文章編號 machine learn give the system of computer ability to with data mine
1 1 2 1 2 1 1 1 1 1 1 1 0
2 1 1 0 1 0 1 0 0 0 0 2 1
3 0 0 0 3 0 2 2 0 0 0 0 0
文章編號 be process discover pattern base on science study theory for design 總和
1 0 0 0 0 0 0 0 0 0 0 0 13
2 1 1 1 1 1 1 0 0 0 0 0 13
3 1 0 0 0 0 0 1 1 1 1 1 13
iN
j
ij
ij
ij
n
n
t
1
9.
人工智慧方法-資訊檢索
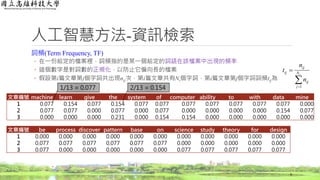
詞頻(Term Frequency, TF)
◦在一份給定的檔案裡,詞頻指的是某一個給定的詞語在該檔案中出現的頻率
◦ 這個數字是對詞數的正規化,以防止它偏向長的檔案
◦ 假設第i篇文章第j個字詞共出現nij次,第i篇文章共有Ni個字詞,第i篇文章第j個字詞詞頻tij為
9
文章編號 machine learn give the system of computer ability to with data mine
1 0.077 0.154 0.077 0.154 0.077 0.077 0.077 0.077 0.077 0.077 0.077 0.000
2 0.077 0.077 0.000 0.077 0.000 0.077 0.000 0.000 0.000 0.000 0.154 0.077
3 0.000 0.000 0.000 0.231 0.000 0.154 0.154 0.000 0.000 0.000 0.000 0.000
iN
j
ij
ij
ij
n
n
t
1
文章編號 be process discover pattern base on science study theory for design
1 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
2 0.077 0.077 0.077 0.077 0.077 0.077 0.000 0.000 0.000 0.000 0.000
3 0.077 0.000 0.000 0.000 0.000 0.000 0.077 0.077 0.077 0.077 0.077
1/13 = 0.077 2/13 = 0.154
10.
人工智慧方法-資訊檢索
逆向文件頻率(Inverse Document Frequency,IDF)
◦ 一個詞語普遍重要性的度量
◦ 可以由總檔案數目除以包含該詞語之檔案的數目,再將得到的商取以10為底的對數得到
◦ 假設第j個字詞出現在mj篇文章,文章總共有M篇,第j個字詞逆向文件頻率dj為
10
文章編號 machine learn give the system of computer ability to with data mine
1 o o o o o o o o o o o x
2 o o x o x o x x x x o o
3 x x x o x o o x x x x x
mj 2 2 1 3 1 3 2 1 1 1 2 1
j
j
m
M
d log
文章編號 be process discover pattern base on science study theory for design
1 x x x x x x x x x x x
2 o o o o o o x x x x x
3 o x x x x x o o o o o
mj 2 1 1 1 1 1 1 1 1 1 1
11.
人工智慧方法-資訊檢索
逆向文件頻率(Inverse Document Frequency,IDF)
◦ 一個詞語普遍重要性的度量
◦ 可以由總檔案數目除以包含該詞語之檔案的數目,再將得到的商取以10為底的對數得到
◦ 假設第j個字詞出現在mj篇文章,文章總共有M篇,第j個字詞逆向文件頻率dj為
11
文章編號 machine learn give the system of computer ability to with data mine
1 0.176 0.176 0.477 0.000 0.477 0.000 0.176 0.477 0.477 0.477 0.176 0.477
2 0.176 0.176 0.477 0.000 0.477 0.000 0.176 0.477 0.477 0.477 0.176 0.477
3 0.176 0.176 0.477 0.000 0.477 0.000 0.176 0.477 0.477 0.477 0.176 0.477
mj 2 2 1 3 1 3 2 1 1 1 2 1
j
j
m
M
d log
文章編號 be process discover pattern base on science study theory for design
1 0.176 0.477 0.477 0.477 0.477 0.477 0.477 0.477 0.477 0.477 0.477
2 0.176 0.477 0.477 0.477 0.477 0.477 0.477 0.477 0.477 0.477 0.477
3 0.176 0.477 0.477 0.477 0.477 0.477 0.477 0.477 0.477 0.477 0.477
mj 2 1 1 1 1 1 1 1 1 1 1
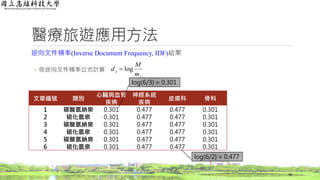
log(3/2) = 0.176 log(3/3) = 0
12.
人工智慧方法-資訊檢索
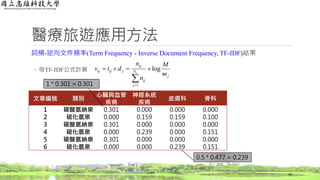
TF-IDF
◦ 詞頻(Term Frequency,TF)和逆向文件頻率(Inverse Document Frequency, IDF)相乘
◦ 第i篇文章第j個字詞TF-IDF值vij為
12
j
N
j
ij
ij
jijij
m
M
n
n
dtv i
log
1
文章編號 machine learn give the system of computer ability to with data mine
1 0.014 0.027 0.037 0.000 0.037 0.000 0.014 0.037 0.037 0.037 0.014 0.000
2 0.014 0.014 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.027 0.037
3 0.000 0.000 0.000 0.000 0.000 0.000 0.027 0.000 0.000 0.000 0.000 0.000
文章編號 be process discover pattern base on science study theory for design
1 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
2 0.014 0.037 0.037 0.037 0.037 0.037 0.000 0.000 0.000 0.000 0.000
3 0.014 0.000 0.000 0.000 0.000 0.000 0.037 0.037 0.037 0.037 0.037
0.077 * 0.176 = 0.014
0.213 * 0 = 0
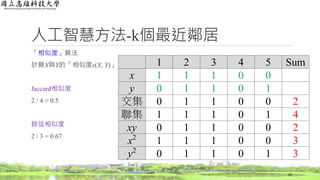
1. 在詞頻的計算下,找出
同一篇文章具有代表性
的字詞
2. 在逆向文件頻率的計算
下,把每篇文章都會出
現的一般字詞去除
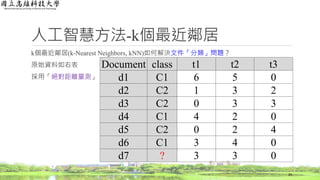
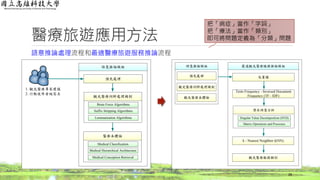
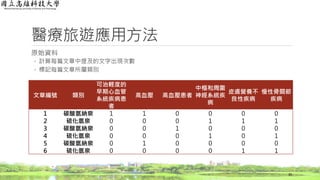
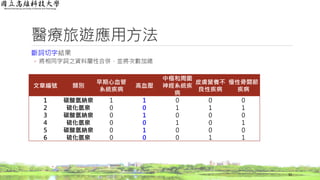
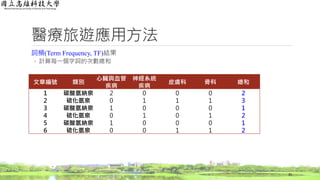
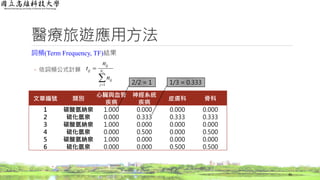
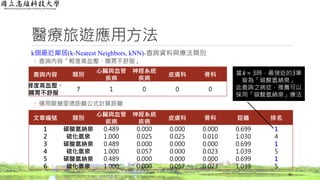
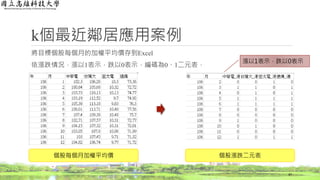
醫療旅遊應用方法
詞頻(Term Frequency, TF)結果
◦依詞頻公式計算
36
文章編號 類別
心臟與血管
疾病
神經系統
疾病
皮膚科 骨科
1 碳酸氫納泉 1.000 0.000 0.000 0.000
2 硫化氫泉 0.000 0.333 0.333 0.333
3 碳酸氫納泉 1.000 0.000 0.000 0.000
4 硫化氫泉 0.000 0.500 0.000 0.500
5 碳酸氫納泉 1.000 0.000 0.000 0.000
6 硫化氫泉 0.000 0.000 0.500 0.500
iN
j
ij
ij
ij
n
n
t
1 2/2 = 1 1/3 = 0.333
37.
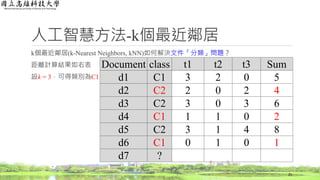
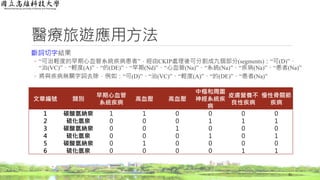
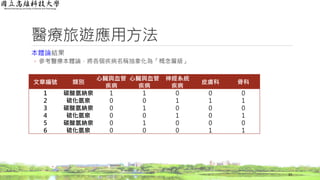
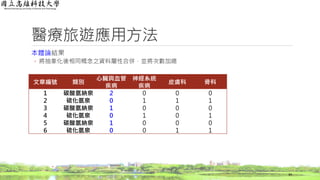
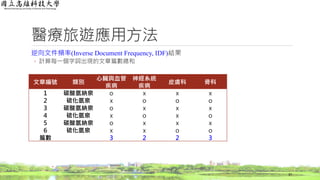
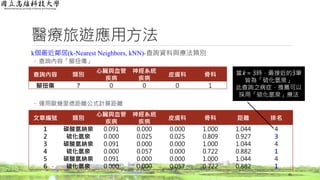
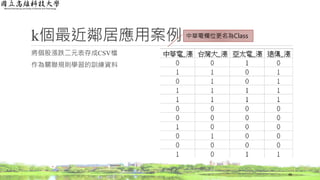
醫療旅遊應用方法
逆向文件頻率(Inverse Document Frequency,IDF)結果
◦ 計算每一個字詞出現的文章篇數總和
37
文章編號 類別
心臟與血管
疾病
神經系統
疾病
皮膚科 骨科
1 碳酸氫納泉 o x x x
2 硫化氫泉 x o o o
3 碳酸氫納泉 o x x x
4 硫化氫泉 x o x o
5 碳酸氫納泉 o x x x
6 硫化氫泉 x x o o
篇數 3 2 2 3






























![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)






























