Support Vector Machine
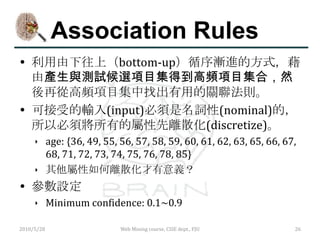
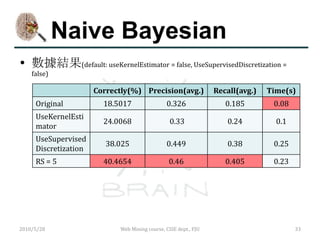
參數設定
Kernel
The normalized polynomial kernel(norPoly)
The polynomial kernel(Poly)
The Pearson VII function-based universal kernel(PUK)
The RBF kernel(RBF)
C: The complexity parameter
Random seed(RS)
2010/5/28 Web Mining course, CSIE dept., FJU 36
37.
Support Vector Machine
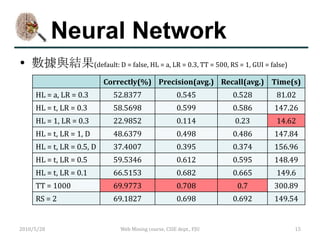
數據結果(default: c = 1.0)
Correctly(%) Precision(avg.) Recall(avg.) Time(s)
norPoly Failed
Poly 28.5471 0.275 0.285 5.44
PUK Failed
RBF Failed
C = 0.7 Failed
C = 1.5 Failed
2010/5/28 Web Mining course, CSIE dept., FJU 37



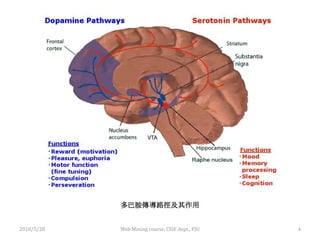



















![Association Rules
數據與結果
一直到minimum confidence = 0.1才有結果。
Minimum support = 0.15(881 instances)
Number of cycles performed: 17
Shimmer='(-inf-0.056174]' Shimmer(dB)='(-inf-
0.4422]' Shimmer:APQ5='(-inf-0.034956]'
Shimmer:APQ11='(-inf-0.057084]' NHR='(-inf-
0.149881]' 4932 ==> total_UPDRS='(21.3976-26.1968]'
894 conf:(0.18)
2010/5/28 Web Mining course, CSIE dept., FJU 27](https://image.slidesharecdn.com/20100427miningtheparkinsonstelemonitoringdataset-100528230644-phpapp02/85/Mining-the-Parkinson-s-Telemonitoring-Data-Set-27-320.jpg)











![參考資料
[1]A Tsanas, MA Little, PE McSharry, LO Ramig (2009) ‘Accurate
telemonitoring of Parkinson disease progression by non-invasive
speech tests’, IEEE Transactions on Biomedical Engineering (to
appear).
[2]http://archive.ics.uci.edu/ml/datasets/Parkinsons+Telemonitoring
[3]http://www.mdvu.org/library/ratingscales/pd/updrs.pdf
[4]http://www.neuro.org.tw/movement/measure/view.asp?m_no=19
&page=1
[5]http://zh.wikipedia.org/zh/帕金森氏症
[6]http://en.wikipedia.org/wiki/Unified_Parkinson's_Disease_Rating_S
cale
[7]http://www.cs.waikato.ac.nz/~ml/weka/index_related.html
2010/5/28 Web Mining course, CSIE dept., FJU 40](https://image.slidesharecdn.com/20100427miningtheparkinsonstelemonitoringdataset-100528230644-phpapp02/85/Mining-the-Parkinson-s-Telemonitoring-Data-Set-40-320.jpg)










![[DSC 2016] 系列活動:許懷中 / R 語言資料探勘實務](https://cdn.slidesharecdn.com/ss_thumbnails/rdatamining-161030010840-thumbnail.jpg?width=640&height=640&fit=bounds)





































