本文件探討人工智慧(AI)如何透過將問題轉化為函數的形式來解決問題,包括定義函數與歷史資料的收集及訓練步驟。文中也介紹了監督式與非監督式學習的基本概念,並舉例說明分類與分群的應用。最後,強調選擇合適的問題及提供充分的數據對於成功運用AI的重要性。
















![人 工 智 慧 導 論
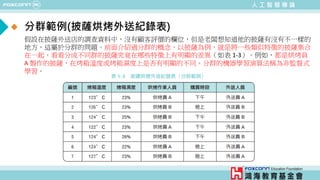
範例二: 以披薩烘烤紀錄演示支持向量機
• 範例1-2: SVM_Example.m
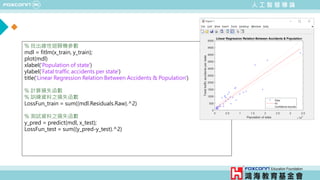
% 載入資料
load pizza
% 取出烤箱溫度、烤箱濕度與顧客評價的資料
x = pizza_data.Temperature;
y = pizza_data.Humidity;
z = pizza_data.Service;
% 利用支持向量機分類顧客評價
SVMModel = fitcsvm([x,y], z, 'KernelFunction', 'linear', 'Standardize', true);
% 以披薩烘烤紀錄演示支持向量機
figure
h(1:2) = gscatter(x,y,z);](https://image.slidesharecdn.com/ppt-aiclaire-240413160131-5bf5963f/85/Chapter-1_Understanding-Artificial-Intelligence-25-320.jpg)
![人 工 智 慧 導 論
hold on
h(3) = plot(x(SVMModel.IsSupportVector),...
y(SVMModel.IsSupportVector),'ko','MarkerSize',10);
d = 0.01;
[x1Grid,x2Grid] = meshgrid(min(x):d:max(x), min(y):d:max(y));
xGrid = [x1Grid(:),x2Grid(:)];
[~,scores1] = predict(SVMModel,xGrid);
contour(x1Grid,x2Grid,reshape(scores1(:,2),size(x1Grid)),[0 0],'k’);
xlabel('烤箱溫度 (^circC)')
ylabel('烤箱濕度 (%)')
% 預測烤箱溫度127度與烤箱濕度23%的顧客評價
newpoint = [127 0.23];
predict(SVMModel, newpoint)
% 烤箱溫度127度與烤箱濕度23,以黑色x表示
plot(newpoint(1),newpoint(2),'kx','MarkerSize',10,'LineWidth',2);
hold off
xlim([121 128])](https://image.slidesharecdn.com/ppt-aiclaire-240413160131-5bf5963f/85/Chapter-1_Understanding-Artificial-Intelligence-26-320.jpg)


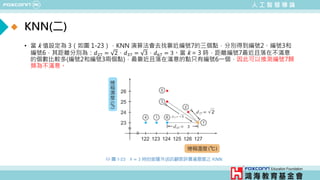
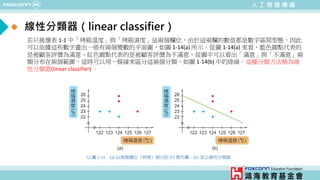
![人 工 智 慧 導 論
範例三: 以披薩烘烤紀錄演示K最近鄰居法(KNN)
• 範例1-3: KNN_Example.m
% 載入資料
load pizza
% 取出烤箱溫度、烤箱濕度與服務的資料並視覺化
x = [pizza_data.Temperature, pizza_data.Humidity];
y = pizza_data.Service;
figure;
gscatter(x(:,1),x(:,2),y);
title('Pizza Data -- Nearest Neighbors');
xlabel('烤箱溫度 (^circC)');
ylabel('烤箱濕度 (%)');
hold on](https://image.slidesharecdn.com/ppt-aiclaire-240413160131-5bf5963f/85/Chapter-1_Understanding-Artificial-Intelligence-33-320.jpg)
![人 工 智 慧 導 論
% 利用fitcknn對pizza烘烤外送服務進行KNN評價分類
mdl = fitcknn(x, y, 'NumNeighbors',3);
% 預測烤箱溫度127度與烤箱濕度23%時的顧客評價
newpoint = [127 0.23];
label = predict(mdl, newpoint)
% 烤箱溫度127度與烤箱濕度23%以黑色x表示
% 將最接近的3個鄰居以灰色圈圈表示
mdl2 = KDTreeSearcher(x);
[n,d] = knnsearch(mdl2,newpoint,'k',3);
plot(newpoint(1),newpoint(2),'kx','MarkerSize',10,'LineWidth',2);
plot(x(n,1),x(n,2),'o','Color',[.5 .5 .5],'MarkerSize',10);
xlim([121 128])](https://image.slidesharecdn.com/ppt-aiclaire-240413160131-5bf5963f/85/Chapter-1_Understanding-Artificial-Intelligence-34-320.jpg)

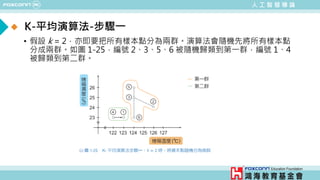


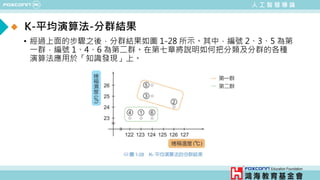
![人 工 智 慧 導 論
範例四: K-平均演算法
• 範例1-4: Kmeans_Example.m
% 載入資料
load pizza
% 取出烤箱溫度與烤箱濕度的資料
x = pizza_data.Temperature;
y = pizza_data.Humidity;
% K平均演算法
[idx,C] = kmeans([x, y],2);
% K-平均演算法的分群結果
gscatter(x, y,idx,'bgm')
hold on
plot(C(:,1),C(:,2),'kx')
xlabel('烤箱溫度 (^circC)')
ylabel('烤箱濕度 (%)')
legend('第一群','第二群','重心')](https://image.slidesharecdn.com/ppt-aiclaire-240413160131-5bf5963f/85/Chapter-1_Understanding-Artificial-Intelligence-40-320.jpg)


















![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)










![[台中分校] 第一期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/sw-ppt-181217031715-thumbnail.jpg?width=640&height=640&fit=bounds)






